MySQL集群解决方案
**
1:mysql数据分库分表,读写分离,主从切换使用mycat
2:集群方案(分布式+集群)
**
分布式:不同的服务器部署不同的模块/工程,他们之间通过RPC/Rmi通信和调用,对外提供服务和组内协作
集群:不同的服务器部署相同的模块/工程,他们之间通过分布式调动软件进行统一调度,对外提供服务和访问
多图文,详细介绍mysql各个集群方案
一,mysql原厂出品
1,MySQL Replication
2,MySQL Fabirc
3,MySQL Cluster
二,mysql第三方优化
4,MMM
5,MHA
6,Galera Cluster
三,依托硬件配合
7,heartbeat+SAN
8,heartbeat+DRDB
四,其它
9,Zookeeper + proxy
10,Paxos
mysql第三方优化
2.1,MMM
MMM是在MySQL Replication的基础上,对其进行优化。
MMM(Master Replication Manager for MySQL)是双主多从结构,这是Google的开源项目,使用Perl语言来对MySQL Replication做扩展,提供一套支持双主故障切换和双主日常管理的脚本程序,主要用来监控mysql主主复制并做失败转移。

MMM_lgx211
注意:这里的双主节点,虽然叫做双主复制,但是业务上同一时刻只允许对一个主进行写入,另一台备选主上提供部分读服务,以加速在主主切换时刻备选主的预热。
就各个集群方案来说,其优势为:
自动的主主Failover切换,一般3s以内切换备机。
多个从节点读的负载均衡。
其劣势为:
无法完全保证数据的一致性。如主1挂了,MMM monitor已经切换到主2上来了,而若此时双主复制中,主2数据落后于主1(即还未完全复制完毕),那么此时的主2已经成为主节点,对外提供写服务,从而导致数据不一。
由于是使用虚拟IP浮动技术,类似Keepalived,故RIP(真实IP)要和VIP(虚拟IP)在同一网段。如果是在不同网段也可以,需要用到虚拟路由技术。但是绝对要在同一个IDC机房,不可跨IDC机房组建集群。
2.2,MHA
MHA是在MySQL Replication的基础上,对其进行优化。
MHA(Master High Availability)是多主多从结构,这是日本DeNA公司的youshimaton开发,主要提供更多的主节点,但是缺少VIP(虚拟IP),需要配合keepalived等一起使用。

要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器,一主二从,即一台充当master,一台充当备用master,另外一台充当从库。
MHA_lgx211
就各个集群方案来说,其优势为:
可以进行故障的自动检测和转移
具备自动数据补偿能力,在主库异常崩溃时能够最大程度的保证数据的一致性。
其劣势为:
MHA架构实现读写分离,最佳实践是在应用开发设计时提前规划读写分离事宜,在使用时设置两个连接池,即读连接池与写连接池,也可以选择折中方案即引入SQL Proxy。但无论如何都需要改动代码;
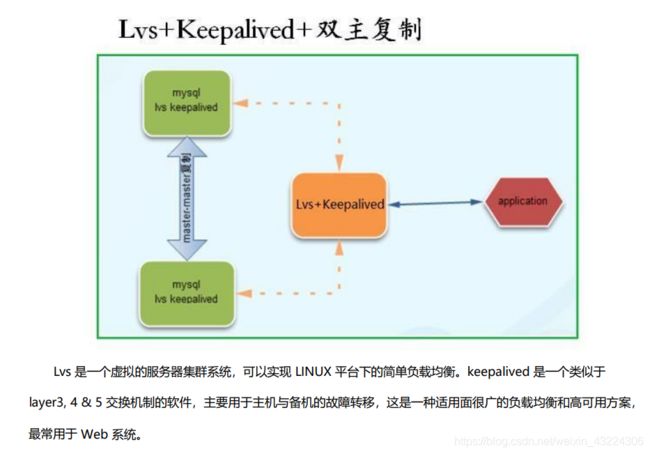
关于读负载均衡可以使用F5、LVS、HAPROXY或者SQL Proxy等工具,只要能实现负载均衡、故障检查及备升级为主后的读写剥离功能即可,建议使用LVS
2.3,Galera Cluster
Galera Cluster是由Codership开发的MySQL多主结构集群,这些主节点互为其它节点的从节点。不同于MySQL原生的主从异步复制,Galera采用的是多主同步复制,并针对同步复制过程中,会大概率出现的事务冲突和死锁进行优化,就是复制不基于官方binlog而是Galera复制插件,重写了wsrep api。
异步复制中,主库将数据更新传播给从库后立即提交事务,而不论从库是否成功读取或重放数据变化。这种情况下,在主库事务提交后的短时间内,主从库数据并不一致。
同步复制时,主库的单个更新事务需要在所有从库上同步 更新。换句话说,当主库提交事务时,集群中所有节点的数据保持一致。
对于读操作,从每个节点读取到的数据都是相同的。对于写操作,当数据写入某一节点后,集群会将其同步到其它节点。

MHA_lgx211
就各个集群方案来说,其优势为:
多主多活下,可对任一节点进行读写操作,就算某个节点挂了,也不影响其它的节点的读写,都不需要做故障切换操作,也不会中断整个集群对外提供的服务。
拓展性优秀,新增节点会自动拉取在线节点的数据(当有新节点加入时,集群会选择出一个Donor Node为新节点提供数据),最终集群所有节点数据一致,而不需要手动备份恢复。
其劣势为:
能做到数据的强一致性,毫无疑问,也是以牺牲性能为代价。
3:mysq5.7已经支持分布式事务
4:分布式id生成
2.2 Mycat 高可用方案
Mycat 作为一个代理层中间件,Mycat 系统的高可用涉及到 Mycat 本身的高可用以及后端 MySQL 的高可用,
前面章节所讲的 MySQL 高可用方案都可以在此用来确保 Mycat 所连接的后端 MySQL 服务的高可用性。在大多
数情况下,建议采用标准的 MySQL 主从复制高可用性配置并交付给 Mycat 来完成后端 MySQL 节点的主从自动
切换。
mycat的三大功能:分库分表、读写分离、主从切换
Mycat关键特性
关键特性
支持SQL92标准
支持MySQL、Oracle、DB2、SQL Server、PostgreSQL等DB的常见SQL语法
遵守Mysql原生协议,跨语言,跨平台,跨数据库的通用中间件代理。
基于心跳的自动故障切换,支持读写分离,支持MySQL主从,以及galera cluster集群。
支持Galera for MySQL集群,Percona Cluster或者MariaDB cluster
基于Nio实现,有效管理线程,解决高并发问题。
支持数据的多片自动路由与聚合,支持sum,count,max等常用的聚合函数,支持跨库分页。
支持单库内部任意join,支持跨库2表join,甚至基于caltlet的多表join。
支持通过全局表,ER关系的分片策略,实现了高效的多表join查询。
支持多租户方案。
支持分布式事务(弱xa)。
支持XA分布式事务(1.6.5)。
支持全局序列号,解决分布式下的主键生成问题。
分片规则丰富,插件化开发,易于扩展。
强大的web,命令行监控。
支持前端作为MySQL通用代理,后端JDBC方式支持Oracle、DB2、SQL Server 、 mongodb 、巨杉。
支持密码加密
支持服务降级
支持IP白名单
支持SQL黑名单、sql注入攻击拦截
支持prepare预编译指令(1.6)
支持非堆内存(Direct Memory)聚合计算(1.6)
支持PostgreSQL的native协议(1.6)
支持mysql和oracle存储过程,out参数、多结果集返回(1.6)
支持zookeeper协调主从切换、zk序列、配置zk化(1.6)
支持库内分表(1.6)
集群基于ZooKeeper管理,在线升级,扩容,智能优化,大数据处理(2.0开发版)。
什么是MYCAT
一个彻底开源的,面向企业应用开发的大数据库集群
支持事务、ACID、可以替代MySQL的加强版数据库
一个可以视为MySQL集群的企业级数据库,用来替代昂贵的Oracle集群
一个融合内存缓存技术、NoSQL技术、HDFS大数据的新型SQL Server
结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品
一个新颖的数据库中间件产品
MYCAT监控
支持对Mycat、Mysql性能监控
支持对Mycat的JVM内存提供监控服务
支持对线程的监控
支持对操作系统的CPU、内存、磁盘、网络的监控
目标
低成本的将现有的单机数据库和应用平滑迁移到“云”端,解决数据存储和业务规模迅速增长情况下的数据瓶颈问题。
1.6版本架构
长期规划2.0
完全实现分布式事务,完全的支持分布式。
通过Mycat web(eye)完成可视化配置,及智能监控,自动运维。
通过mysql 本地节点,完整的解决数据扩容难度,实现自动扩容机制,解决扩容难点。
支持基于zookeeper的主从切换及Mycat集群化管理。
通过Mycat Balance 替代第三方的Haproxy,LVS等第三方高可用,完整的兼容Mycat集群节点的动态上下线。
接入Spark等第三方工具,解决数据分析及大数据聚合的业务场景。
通过Mycat智能优化,分析分片热点,提供合理的分片建议,索引建议,及数据切分实时业务建议。
优势
基于阿里开源的Cobar产品而研发,Cobar的稳定性、可靠性、优秀的架构和性能以及众多成熟的使用案例使得MYCAT一开始就拥有一个很好的起点,站在巨人的肩膀上,我们能看到更远。业界优秀的开源项目和创新思路被广泛融入到MYCAT的基因中,使得MYCAT在很多方面都领先于目前其他一些同类的开源项目,甚至超越某些商业产品。
MYCAT背后有一支强大的技术团队,其参与者都是5年以上软件工程师、架构师、DBA等,优秀的技术团队保证了MYCAT的产品质量。
MYCAT并不依托于任何一个商业公司,因此不像某些开源项目,将一些重要的特性封闭在其商业产品中,使得开源项目成了一个摆设。