Python网络爬虫——爬取和分析NBA球员排名及各项数据
一、选题的背景介绍(15分)
NBA受到世界各地极大多数人的喜爱,不分年龄,学生、员工、劳动工人等社会各界都有热爱篮球的人,也有各自喜欢信仰的球星,在NBA中国官方网站里他们更好的了解和清楚自己喜爱的球星和其它联盟里的球星的一些数据对比,知道他们近期的一些起伏和爆发,本次爬虫建立在这基础上,通过对网页数据的提取并进行可视化对比,更好地了解联盟里球员的排名和其余各项数据之间的关系来分析对球队的贡献好与坏。
二、数据可视化分析的步骤(60分)
1.爬虫名称:爬取NBA球员排名及各项数据
2.爬取内容:爬取NBA球员排名、场均得分、各项命中率、三分命中率等
3.方案概述:访问网页得到状态码200,分析网页源代码,找出所需要的的标签,逐个提取标签保存到相同路径csv文件中,读取该文件,进行数据清洗,数据模型分析,数据可视化处理,绘制排名与其余几项数据的关系图。
技术难点:
1.在爬取网页数据,提取数据成csv文件时,由于数据较为杂乱。
2. 做数据分析,即求回归系数,因为标题是文字,无法与数字作比较,需要把标题这一列删除才可。由于不明原因,输出结果经常会显示超出列表范围。
、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、
#预览数据
import pandas as pd
df = pd.read_csv('/Users/bigboss/Desktop/王受杰/qiuyuan.csv',encoding='utf-8')
print(df.head())

#查看空缺数据
df.info()

#查看异常值
df.describe()
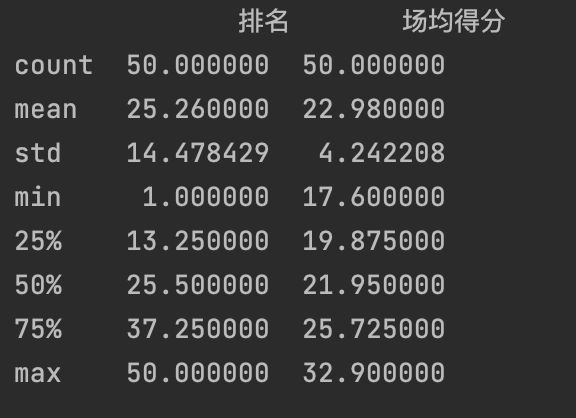
mport pandas as pd
df = pd.read_csv('/Users/bigboss/Desktop/王受杰/qiuyuan.csv',encoding='utf-8')
#清洗命中率、三分命中率、罚球命中率
re = df['命中率']
list1 = []
for i in re:
a = i[:-1]
print(a)
list1.append(a)
re1 = df['三分命中率']
list2 = []
for i in re1:
a = i[:-1]
print(a)
list2.append(a)
list3 = []
re2 = df['罚球命中率']
for i in re2:
a = i[:-1]
print(a)
list3.append(a)
header = ['alter_hit_rate' , 'alter_three' , 'alter_faqiu']
df1 = pd.DataFrame({header[0]:list1})
dataframe1 = df.join(df1)
dataframe1.to_csv('/Users/bigboss/Desktop/王受杰/qiuyuan.csv', mode='w', sep=',')
df2 = pd.DataFrame({header[1]:list2})
dataframe2 = dataframe1.join(df2)
dataframe2.to_csv('/Users/bigboss/Desktop/王受杰/qiuyuan.csv', mode='w', sep=',')
df3 = pd.DataFrame({header[2]:list3})
dataframe3 = dataframe2.join(df3)
dataframe3.to_csv('/Users/bigboss/Desktop/王受杰/qiuyuan.csv', mode='w', sep=',')
print(df.head(5))

df = pd.read_csv('/Users/bigboss/Desktop/王受杰/qiuyuan.csv',encoding='utf-8')
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
data = pd.DataFrame(list(df['场均得分'][:10]),
index=df['球员'][:10])
data.plot.bar(color='b')
plt.xticks(rotation = 45)
plt.xlabel('球员',fontsize = 15)
plt.ylabel('场均得分',fontsize = 15)
plt.title('前十球员的得分对比图',color = 'r',fontsize = 16)
plt.show()
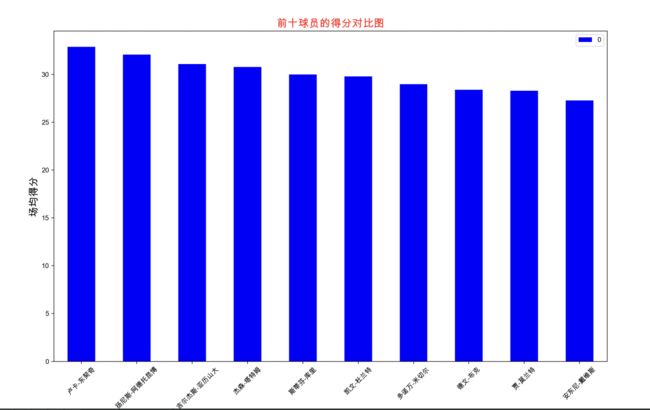
此图可以看出整个球员谁的得分能力最强,可以看到东契奇,也是我很喜欢的一名球星,他的得分能力是最强的,在各大联盟之间也是很抢手的存在。
fig = plt.figure(figsize=(8, 6), dpi=100)
ax = plt.subplot(111, polar=True)
listk = []
listk.append(df['alter_hit_rate'][4])
listk.append(df['alter_three'][4])
listk.append(df['alter_faqiu'][4])
listd = []
listd.append(df['alter_hit_rate'][0])
listd.append(df['alter_three'][0])
listd.append(df['alter_faqiu'][0])
lists = ['命中率','三分命中率','罚球命中率']
results = [{lists[0]:listk[0],
lists[1]:listk[1],
lists[2]:listk[2]},
{lists[0]:listd[0],
lists[1]:listd[1],
lists[2]:listd[2]}]
data_length = len(results[0])
# 将极坐标根据数据长度进行等分
angles = np.linspace(0, 2*np.pi, data_length, endpoint=False)
labels = [key for key in results[0].keys()]
score = [[v for v in result.values()] for result in results]
# 使雷达图数据封闭
score_a = np.concatenate((score[0], [score[0][0]]))
score_b = np.concatenate((score[1], [score[1][0]]))
angles = np.concatenate((angles, [angles[0]]))
labels = np.concatenate((labels, [labels[0]]))
# 绘制雷达图
ax.plot(angles, score_a, color='g')
ax.plot(angles, score_b, color='b')
# 设置雷达图中每一项的标签显示
ax.set_thetagrids(angles*180/np.pi, labels)
# 设置雷达图的0度起始位置
ax.set_theta_zero_location('N')
# 设置雷达图的坐标刻度范围
ax.set_rlim(0, 100)
# 设置雷达图的坐标值显示角度,相对于起始角度的偏移量
ax.set_rlabel_position(270)
ax.set_title("球员能力率综合对比")
plt.legend(["库里", "东契奇"], loc='best')
plt.show()
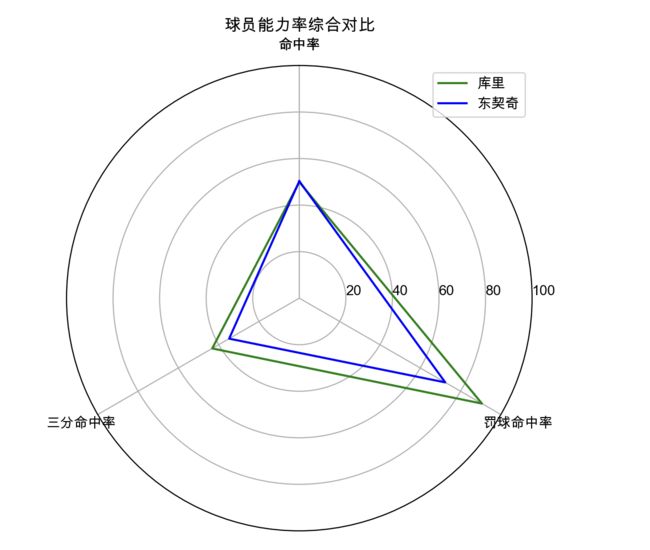
这张图可以看出,库里在命中率方面和东契奇是不相上下的,但是在三分和罚球方面库里是要比东契奇好一点的,在综合得分能力上库里是稍强于东契奇的。
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
sns.distplot(df['场均得分'])
plt.xlabel("得分",color = 'g',fontsize = 12)
plt.ylabel('百分占比',color = 'b' , fontsize = 12)
plt.title('得分分布图', fontsize = 15)
plt.show()

可以看出,nba各大联盟的各大球星中,场均得分均会稳定在20-25分之间,球员的得分能力都较为稳定。
x= np.arange(0,50)
y=np.array(df['alter_faqiu'])
labels=np.array(df['球员'])
fig=plt.figure(figsize=(10,6),dpi=80)
ax=fig.add_subplot(111)
markerline,stemlines,baseline=ax.stem(x,y,linefmt='--',markerfmt='o',label='TestStem',use_line_collection=True)
plt.setp(stemlines,lw=1)
plt.xlabel(u"",fontsize = 15,color='r')
plt.ylabel("",fontsize = 15,color = 'r')
plt.title("",fontsize = 15,color = 'b')
ax.set_xticks(x)
ax.set_xticklabels(labels,rotation=70)
plt.title('球员罚球命中率对比' , color = 'b')
plt.xlabel('球员')
plt.ylabel('罚球率%')
ax.set_ylim([0,100])
for temp_x,temp_y in zip(x,y):
ax.text(temp_x,temp_y+100,s='{}'.format(temp_y),ha='center',va='bottom',fontsize=12)
plt.show()
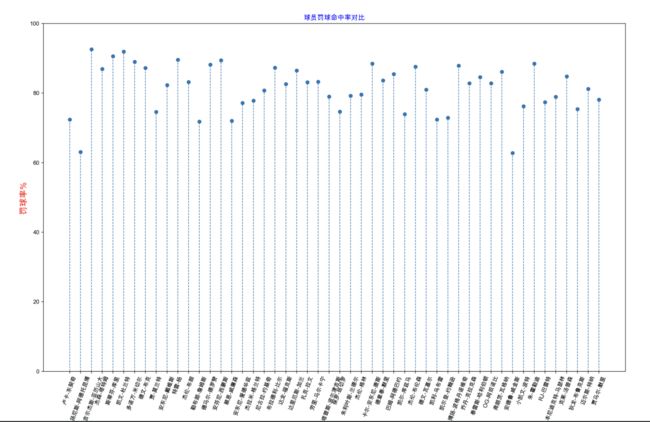
可以看到不一定排名越高,他的所有能力都会那么强,可以发现他们的罚球有高有低,但是整天看下来相差并不是很大。
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.plot(df['alter_three'], df['alter_faqiu'], linestyle='', marker='.')
plt.xlabel('三分命中率',size=12, color='g')
plt.ylabel('罚球命中率',size=12, color='r')
plt.title('三分和罚球命中率图',size=20)
plt.show()
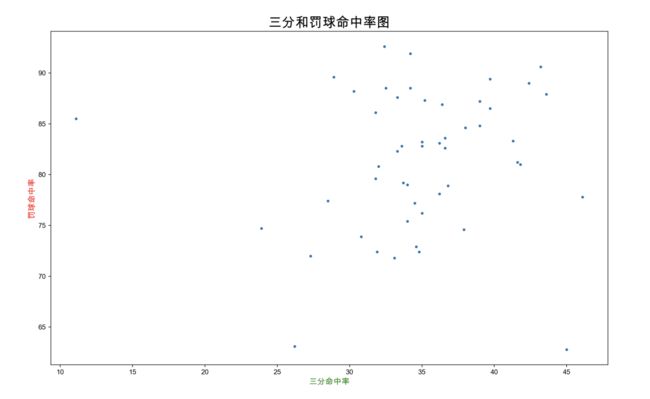
可以看到三分命中率越高的话,罚球的命中率也会相对来说有提升,而且大部分球员的三分命中率在35-40之间,但是罚球命中率低的密集程度是高于罚球命中率高的,说明大部分球员还是对罚球并没有特别大的把握。
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
sns.jointplot(x="失误",y="alter_hit_rate",data=df,kind='reg')
plt.xlabel('失误',size=12, color='g')
plt.ylabel('得分率',size=12, color='r')
plt.show()

根据图片可以看出,随着得分率的下降,失误率也会有所下降,但是幅度很小,可以看出,球员在有失误的情况下,也能把自己的真实水平发挥出来。
三、总结(15分)
通过一系列的数据分析及可视化可以发现,在爬取的这些球员之中,根据场均得分来进行的排名,事实上并不是能那么可靠地分析一个球员的好与坏,在场上不仅仅只有得分,还有其余的各项数据,投篮的命中率以及防守、进攻效率和对球队的1帮助很大程度上并不是根据场均得分来体现,得分高命中率低,可能会导致球队落后和失分。经过一系列数据对比我们可以的到此结论,达到了预期的目标。
四、附录(10分)
import csv
import requests
f = open('qiuyuan.csv', mode='a', encoding='utf8', newline='')
csv_write = csv.DictWriter(f,fieldnames=['排名', '球队', '球员','场均得分', '命中率', '三分命率','罚球命中率'])
csv_write.writeheader()
url = 'https://nba.hupu.com/stats/players'
head = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36',
'cookie' : 'Hm_lvt_4fac77ceccb0cd4ad5ef1be46d740615=1670421583,1670475116;'
'Hm_lpvt_4fac77ceccb0cd4ad5ef1be46d740615=1670475116;'
'Hm_lvt_b241fb65ecc2ccf4e7e3b9601c7a50de=1670421583,1670475116;'
'Hm_lpvt_b241fb65ecc2ccf4e7e3b9601c7a50de=1670475116;'
'Hm_lvt_a3d34dd67fa1fb34b2b430bbaaa2a5bf=1670421583,1670475117;'
'Hm_lpvt_a3d34dd67fa1fb34b2b430bbaaa2a5bf=1670475117',
'accept' : 'text/html,application/xhtml+xml,application/xml;'
'q=0.9,image/avif,image/webp,image/apng,*/*;'
'q=0.8,application/signed-exchange;v=b3;q=0.9'
}
nb = requests.get(url, headers=head).text
from lxml import etree
sb = etree.HTML(nb)
whh = sb.xpath('//tbody/tr[not(@class)]')
for i in whh:
pm = str(i.xpath('./td[1]/text()')).replace("['", "").replace("']", "") # 排名
team = str(i.xpath('./td[3]/a/text()')).replace("['", "").replace("']", "") # 球队
name = str(i.xpath('./td[2]/a/text()')).replace("['", "").replace("']", "") # 球员
score = str(i.xpath('./td[4]/text()')).replace("['", "").replace("']", "") # 得分
mzl = str(i.xpath('./td[6]/text()')).replace("['", "").replace("']", "") # 命中率
sfmzl = str(i.xpath('./td[8]/text()')).replace("['", "").replace("']", "") # 三分命中率
fqmzl = str(i.xpath('./td[10]/text()')).replace("['", "").replace("']", "") # 罚球命中率
print(pm)
print(team)
print(name)
print(score)
print(mzl)
print(sfmzl)
print(fqmzl)
data_dict = {'排名': pm, '球队': team,
'球员': name, '场均得分': score,
'命中率': mzl, '三分命中率': sfmzl,
'罚球命中率': fqmzl}
csv_write.writerow(data_dict)
f.close()
#预览数据
import pandas as pd
df = pd.read_csv('/Users/bigboss/Desktop/王受杰/qiuyuan.csv',encoding='utf-8')
print(df.head())
#查看空缺数据
df.info()
#查看异常值
df.describe()
import pandas as pd
df = pd.read_csv('/Users/bigboss/Desktop/王受杰/qiuyuan.csv',encoding='utf-8')
#清洗命中率、三分命中率、罚球命中率
re = df['命中率']
list1 = []
for i in re:
a = i[:-1]
print(a)
list1.append(a)
re1 = df['三分命中率']
list2 = []
for i in re1:
a = i[:-1]
print(a)
list2.append(a)
list3 = []
re2 = df['罚球命中率']
for i in re2:
a = i[:-1]
print(a)
list3.append(a)
header = ['alter_hit_rate' , 'alter_three' , 'alter_faqiu']
df1 = pd.DataFrame({header[0]:list1})
dataframe1 = df.join(df1)
dataframe1.to_csv('/Users/bigboss/Desktop/王受杰/qiuyuan.csv', mode='w', sep=',')
df2 = pd.DataFrame({header[1]:list2})
dataframe2 = dataframe1.join(df2)
dataframe2.to_csv('/Users/bigboss/Desktop/王受杰/qiuyuan.csv', mode='w', sep=',')
df3 = pd.DataFrame({header[2]:list3})
dataframe3 = dataframe2.join(df3)
dataframe3.to_csv('/Users/bigboss/Desktop/王受杰/qiuyuan.csv', mode='w', sep=',')
print(df.head(5))
df = pd.read_csv('/Users/bigboss/Desktop/王受杰/qiuyuan.csv',encoding='utf-8')
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
data = pd.DataFrame(list(df['场均得分'][:10]),
index=df['球员'][:10])
data.plot.bar(color='b')
plt.xticks(rotation = 45)
plt.xlabel('球员',fontsize = 15)
plt.ylabel('场均得分',fontsize = 15)
plt.title('前十球员的得分对比图',color = 'r',fontsize = 16)
plt.show()
fig = plt.figure(figsize=(8, 6), dpi=100)
ax = plt.subplot(111, polar=True)
listk = []
listk.append(df['alter_hit_rate'][4])
listk.append(df['alter_three'][4])
listk.append(df['alter_faqiu'][4])
listd = []
listd.append(df['alter_hit_rate'][0])
listd.append(df['alter_three'][0])
listd.append(df['alter_faqiu'][0])
lists = ['命中率','三分命中率','罚球命中率']
results = [{lists[0]:listk[0],
lists[1]:listk[1],
lists[2]:listk[2]},
{lists[0]:listd[0],
lists[1]:listd[1],
lists[2]:listd[2]}]
data_length = len(results[0])
# 将极坐标根据数据长度进行等分
angles = np.linspace(0, 2*np.pi, data_length, endpoint=False)
labels = [key for key in results[0].keys()]
score = [[v for v in result.values()] for result in results]
# 使雷达图数据封闭
score_a = np.concatenate((score[0], [score[0][0]]))
score_b = np.concatenate((score[1], [score[1][0]]))
angles = np.concatenate((angles, [angles[0]]))
labels = np.concatenate((labels, [labels[0]]))
# 绘制雷达图
ax.plot(angles, score_a, color='g')
ax.plot(angles, score_b, color='b')
# 设置雷达图中每一项的标签显示
ax.set_thetagrids(angles*180/np.pi, labels)
# 设置雷达图的0度起始位置
ax.set_theta_zero_location('N')
# 设置雷达图的坐标刻度范围
ax.set_rlim(0, 100)
# 设置雷达图的坐标值显示角度,相对于起始角度的偏移量
ax.set_rlabel_position(270)
ax.set_title("球员能力率综合对比")
plt.legend(["库里", "东契奇"], loc='best')
plt.show()
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
sns.distplot(df['场均得分'])
plt.xlabel("得分",color = 'g',fontsize = 12)
plt.ylabel('百分占比',color = 'b' , fontsize = 12)
plt.title('得分分布图', fontsize = 15)
财卡号
plt.show()
x= np.arange(0,50)
y=np.array(df['alter_faqiu'])
labels=np.array(df['球员'])
fig=plt.figure(figsize=(10,6),dpi=80)
ax=fig.add_subplot(111)
markerline,stemlines,baseline=ax.stem(x,y,linefmt='--',markerfmt='o',label='TestStem',use_line_collection=True)
plt.setp(stemlines,lw=1)
plt.xlabel(u"",fontsize = 15,color='r')
plt.ylabel("",fontsize = 15,color = 'r')
plt.title("",fontsize = 15,color = 'b')
ax.set_xticks(x)
ax.set_xticklabels(labels,rotation=70)
plt.title('球员罚球命中率对比' , color = 'b')
plt.xlabel('球员')
plt.ylabel('罚球率%')
ax.set_ylim([0,100])
for temp_x,temp_y in zip(x,y):
ax.text(temp_x,temp_y+100,s='{}'.format(temp_y),ha='center',va='bottom',fontsize=12)
plt.show()
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.plot(df['alter_three'], df['alter_faqiu'], linestyle='', marker='.')
plt.xlabel('三分命中率',size=12, color='g')
plt.ylabel('罚球命中率',size=12, color='r')
plt.title('三分和罚球命中率图',size=20)
plt.show()
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
sns.jointplot(x="失误",y="alter_hit_rate",data=df,kind='reg')
plt.xlabel('失误',size=12, color='g')
plt.ylabel('得分率',size=12, color='r')
plt.show()