基于Python的HOG+SVM行人识别
前言
首先我将简单阐述一下HOG和SVM的原理,当然重点主要是HOG对于SVM已经有很多的资料讲述的很清楚我觉得此处没有必要再详细讲解。
- HOG特征提取原理
- SVM简单原理概述
- 基于Python的HOG+SVM的行人识别
一、HOG特征提取原理
首先先讲一下HOG是什么和HOG特征提取的步骤吧。
首先HOG就是梯度方向直方图 (Histogram of Oriented Gradient, HOG) ,HOG 特征是直接将图像像素点的方向梯度作为图像特征,包括梯度大小和方向。说实话在我自己看来的话,其实HOG有点像边缘提取把一个物体的轮廓可以用梯度的方法很好的描绘出来,而轮廓说实在的就是特征了吧。
然后就是HOG特征提取的步骤。其实网上已经有很多HOG特征提取原理的概述但是我看了这么多好像都是大同小异,在我刚开始看的时候真的看了很多然后发现讲来讲去都是那些东西对于刚理解刚入手的人来说是有点困难但这也不可避免,看不懂真的就要多看多看多坎=看几遍!!多看+思考就会发现原来HOG不会太难。这是HOG特征提取的一个经典步骤图:
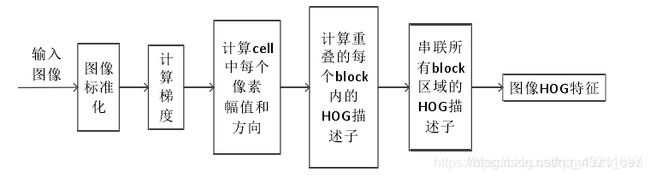
1.图像标准化,在其他地方可能也会成为对图像进行伽马处理。就是对每个图像中的像素点进行n次方,其中的n称为伽马系数,一般n=0.5。伽马值,是对图像的优化调整,是亮度和对比度的辅助功能。其实好像如果做静态图片处理的时候没怎么用到这一步欸。
2.计算梯度,梯度的计算是要求每个像素点水平和垂直方向的梯度值
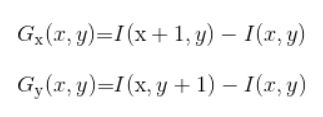
I(x,y)是指在(x,y)处的像素点的值,然后就得到了x和y方向上的梯度值
然后就可以求梯度方向和幅值了
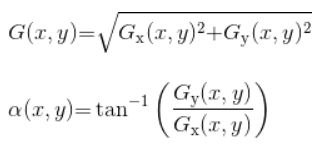
3.接下来要说的是重点就是Win,block,blockStride,cell,cellBin
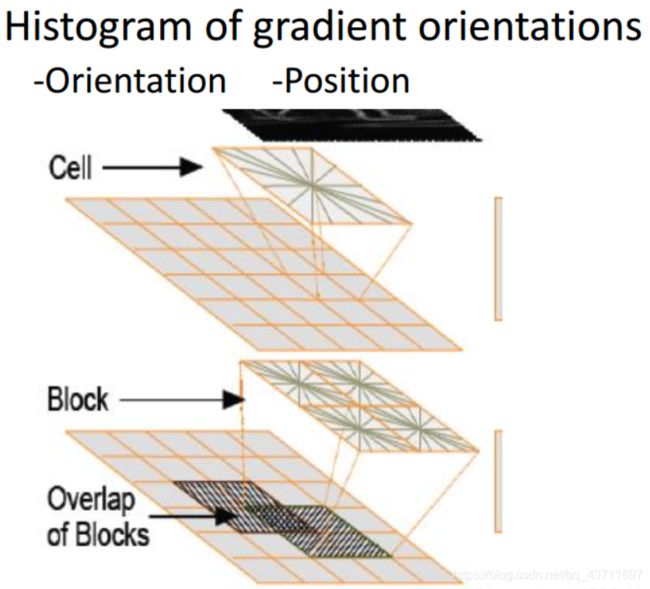
win就是一个检测窗口一般的化我们都是习惯上采用64128因为这是用来检测行人或车辆上研究出来比较适合的一个参数值1:2或2:1。
block是在win窗口里面移动的一个1616的块
blockStride就是块每次移动的步长了一般为88
cell就是block里面一个88的元组,一个块里面含有四个cell
一个cell里面一般分为9个bin也就是9个方向,下面这个图是方向分类的一个圆图

可能有人要问为什么一定是这些参数,其实我当时也有质疑过,但后来发现这些参数的设定是有一定道理的,这是人家在经过多次的试验之后得出来得一个比较合理通用的一个参数。
4.然后就像以上那样求出所有像素点得特征后我们来计算一下。一张图像一般裁剪成64128(行人检测)然后一共有((64-16)/8+1)((128-16)/8+1)=105个块,一个块有4个cell,一个cell有9个bin,那么一共有105x4x9=3780个bin,也就是一张图像会得到3780个数字也就是这张图象特征维度。然后我们会把这个3780个数放在一个数组里面。
二、SVM简单概述
SVM就是支持向量机,它在做线性二分类问题上有着很突出的性能优势,当然在其他方面也是一样,这也要配合于核函数,可以说核函数在机器学习里面十分的重要和强大。
SVM就是找到一个分界面把两类数据能够分离开来,然后使得两边最靠近的点的距离最大。
函数间隔y(wx+b):|wx+b|表示点x距离超平面的远近,wx+b的符号与y的符号是否一致表示分类是否正确,所以y(wx+b)就表示分类的正确性和确信度。
max(几何间隔) -> max(函数间隔/||w||) -> min(1/||w||2),即求解凸二次优化问题(最大间隔法求解)或应用拉格朗日对偶性 -> 求解对偶问题(SMO算法)。
核函数的作用就是处理线性分类问题。例如需要用超曲面来分开所有实例点。原理是使用一个变换将原空间的数据映射到新空间。在处理非线性分类问题的时候,实例点无法用线性模型正确分开,需要使用和核函数将数据映射到一个新的空间,在新空间里用线性分类学习方法求得超平面。
以上就是SVM的简介如果需要更详细的叙述可以查看书籍或网上资料有很多关于SVM的细节上的推导。
三、基于Python的HOG+SVM行人检测
HOG+SVM的基本步骤其实都大同小异这里我整理了下自己的。
1.提取获得正样本和负样本数据当然还有测试集数据,正样本就是行人的图像标签为+1而负样本就是非行人的图像标签为-1。
2.开始获得正样本和负样本的HOG数据并且保存在数组里面,还要再设一个标签数组用来存放正负样本的标签值
3.svm对象的训练,并且保存下训练后的数据文件
4.加载测试对象,载入数据文件,计算HOG,用svm判断。
下面上代码
import cv2
import numpy as np
def get_svm_detector(svm):
sv = svm.getSupportVectors() #SVM支持向量
rho, _, _ = svm.getDecisionFunction(0)#SVM的决策函数
sv = np.transpose(sv)
return np.append(sv, [[-rho]], 0) #得到支持向量和决策函数系数的一个数组
#SVM的分类平面计算
PosNum=3548
NegNum=10000
winSize=(64,128)
blockSize=(16,16)
blockStride=(8,8)
cellSize=(8,8)
nBin=9
#初始的值设定
hog=cv2.HOGDescriptor(winSize,blockSize,blockStride,cellSize,nBin)
#HOG对象的创建初始化
svm=cv2.ml.SVM_create()
#SVM对象的创建
featureNum = int(((128 - 16) / 8 + 1) * ((64 - 16) / 8 + 1) * 4 * 9)
#计算HOG的维度总数即特征数
featureArray = np.zeros(((PosNum + NegNum), featureNum), np.float32)
labelArray = np.zeros(((PosNum + NegNum), 1), np.int32)
#构建两个数组分别是放特征的和放标签的
for i in range(0,PosNum):
n=str(i+1)
fileName="C://Users//dell//Desktop//DATA//pos//person"+n.zfill(6)+".jpg"
img=cv2.imread(fileName)
hist=hog.compute(img,(8,8))
for j in range(0,featureNum):
featureArray[i,j]=hist[j]
labelArray[i,0]=1
#正样本的HOG特征的计算并存进featureArray数组中
for i in range(0,NegNum):
n=str(i+1)
filename="C://Users//dell//Desktop//DATA//neg//noperson"+n.zfill(6)+".jpg"
img=cv2.imread(filename)
hist=hog.compute(img,(8,8))
for j in range(0,featureNum):
featureArray[i+PosNum,j]=hist[j]
labelArray[i+PosNum,0]=-1
#负样本的HOG特征计算
#SVM的参数初始化,这里用SVM线性分类器来做速度比较快
svm.setCoef0(0)
svm.setCoef0(0.0)
svm.setDegree(3)
criteria = (cv2.TERM_CRITERIA_MAX_ITER + cv2.TERM_CRITERIA_EPS, 1000, 1e-3)
svm.setTermCriteria(criteria)
svm.setGamma(0)
svm.setNu(0.5)
svm.setP(0.1)
svm.setC(0.01)
svm.setType(cv2.ml.SVM_EPS_SVR)
svm.setKernel(cv2.ml.SVM_LINEAR)
svm.setC(0.01)
#SVM对象参数的设置,核算子的设定等
svm.train(featureArray, cv2.ml.ROW_SAMPLE, labelArray)
#把计算得到的HOG数据放到SVM对象分类器里面进行训练
HOG=cv2.HOGDescriptor()
HOG.setSVMDetector(get_svm_detector(svm))
HOG.save('myHogDector.bin')
#HOG和SVM结合的一个分类器并且把文件存下来save
myHog = cv2.HOGDescriptor()
myHog.load('myHogDector.bin')
#开始加载上述的那个分类器
imageSrc = cv2.imread('C://Users//dell//Desktop//2.jpg')
#输入检测的图像
rects,wei=myHog.detectMultiScale(imageSrc,0,(4, 4),(32, 32), 1.05, 2)
for (x, y, w, h) in rects:
cv2.rectangle(imageSrc, (x, y), (x + w, y + h), (0, 0, 255), 2)
#对检测出来的分类为1的矩形进行遍历框出来
cv2.imshow('dst', imageSrc)
cv2.waitKey(0)
下面是效果图分别是非行人图像和行人图像,对于非行人图是不会有矩形框出的,而对于行人图像将会有矩形框出行人大致轮廓。


四、结语与总结
这一份代码只是比较草稿比较简单的一份,只是写明了HOG+SVM来用于检测的一个基本的步骤,其实还是有错误率存在这是由于两个原因,一个是可能自身的样本还不够大,第二个是这份是比较简单和草稿的代码里面的SVM训练只有一次,其实按道理应该要对负样本进行一次训练然后抽出那些分类错的记录下来纠正一下,但这些还没写好,这里可能代码效果还不是很好,请谅解。
可能本文写的不是那么好还是请各位谅解,本人只是想记录一下学习的基本过程步骤,本文如有雷同敬请谅解,毕竟自己也是看了很多的文章和书籍然后脑海里综合了很多。