[Pytorch系列-53]:循环神经网络 - torch.nn.LSTM()参数详解
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/121644547
目录
第1章 LSTM基本理论
第2章 torch.nn.LSTM类的参数详解
2.1 类的原型
2.2 类的参数:用于构建LSTM神经网络实例
第3章 前向传播输入详解
3.1 前向传播的格式
3.2 input的格式
3.3 h_0的格式
3.4 c_0的格式
第4章 前向传播输出详解
4.1 输出返回值的格式
4.2 output的格式
4.3 h_n的格式
4.4 c_n的格式
第1章 LSTM基本理论
[人工智能-深度学习-52]:RNN的缺陷与LSTM的解决之道_文火冰糖(王文兵)的博客-CSDN博客作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客本文网址:目录第1章 RNN的缺陷1.1 RNN的前向过程1.2RNN反向求梯度过程1.2 梯度爆炸(每天进一步一点点,N天后,你就会腾飞)1.3 梯度弥散/消失(每天堕落一点点,N天后,你就彻底完蛋)1.4RNN网络梯度消失的原因1.5 解决“梯度消失“的方法主要有:1.5 RNN网络的功能缺陷第2章 LSTM长短期记忆网络2.1 LSTM概述2.3LSTM网...https://blog.csdn.net/HiWangWenBing/article/details/121547541
第2章 torch.nn.LSTM类的参数详解
2.1 类的原型

2.2 类的参数:用于构建LSTM神经网络实例

input_size: 输入序列的一维向量的长度。
hidden_size: 隐层的输出特征的长度。
num_layers:隐藏层堆叠的高度,用于增加隐层的深度。
bias:是否需要偏置b
batch_first:用于确定batch size是否需要放到输入输出数据形状的最前面。
若为真,则输入、输出的tensor的格式为(batch , seq , feature)
若为假,则输入、输出的tensor的格式为(seq, batch , feature)
为什么需要该参数呢?
在CNN网络和全连接网络,batch通常位于输入数据形状的最前面 。
而对于具有时间信息的序列化数据,通常需要把seq放在最前面,需要把序列数据串行地输入网络中。
dropout: 默认0 若非0,则为dropout率。
bidirectional:是否为双向LSTM, 默认为否
第3章 前向传播输入详解
3.1 前向传播的格式
lstm (input, (h_0, c_0))
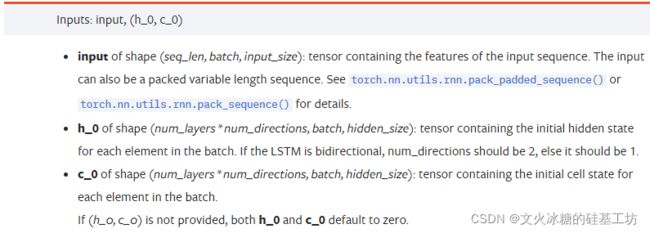
- input:输入序列样本
- h_0:先前的短期状态记忆
- c_0:先前的长期状态记忆
3.2 input的格式
(1)当batch_first=false(默认)
input的形状为(seq_len, batch, input_size)
(2)当batch_first=true
input的形状为(batch, seq_len, input_size)
(3)参数解读
- batch:batch的长度
- input_size:输入样本的向量长度。
- seq_len:输入序列的长度,一次可以串行输入多个输入样本
3.3 h_0的格式
若h_0和c_0不提供,则默认为全0 .
h_0是格式为: (num_layers * num_directions, batch, hidden_size) 的tensor
- num_directions:由隐层的层数决定
- batch:batch
- hidden_size:隐层输出特征的长度
3.4 c_0的格式
若c_0不提供时,则默认为全0 .
c_0是格式为: (num_layers * num_directions, batch, hidden_size) 的tensor
- num_directions:由隐层的层数决定
- batch:batch
- hidden_size:隐层输出特征的长度
第4章 前向传播输出详解
4.1 输出返回值的格式
output, (h_n, c_n) = lstm (input, (h_0, c_0))

4.2 output的格式
(1)当batch_first=false(默认)
input的形状为(seq_len, batch, num_layers * num_directions,)
(2)当batch_first=true
input的形状为(batch, seq_len, num_layers * num_directions,)
(3)参数解读
- batch:batch的长度
- num_directions:取决于堆叠的长度
- seq_len:输入序列的长度,输出的长度与输入序列的长度一致。
4.3 h_n的格式
h_0是格式为: (num_layers * num_directions, batch, hidden_size) 的tensor
- num_directions:由隐层的层数决定
- batch:batch
- hidden_size:隐层输出特征的长度
4.4 c_n的格式
c_0是格式为: (num_layers * num_directions, batch, hidden_size) 的tensor
- num_directions:由隐层的层数决定
- batch:batch
- hidden_size:隐层输出特征的长度
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/121644547