pytorch nn.LSTM(),nn.GRU()参数详解
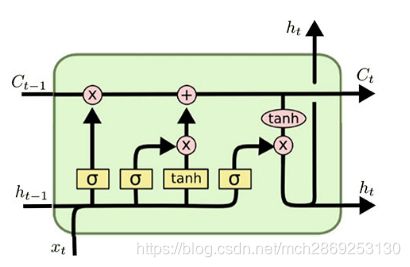
LSTM结构中是一个神经网络,即上图的结构就是一个LSTM单元,里面的每个黄框是一个神经网络,这个网络的隐藏单元个数我们设为hidden_size,那么这个LSTM单元里就有4*hidden_size个参数。每个LSTM输出的都是向量,包括 C t 和 h t C_t和h_t Ct和ht ,它们的长度都是当前LSTM单元的hidden_size
函数
class torch.nn.LSTM(*args, **kwargs)
参数列表
- input_size:x的特征维度
- hidden_size:隐藏层的特征维度
- num_layers:lstm隐层的层数,默认为1
- bias:False则bih=0和bhh=0. 默认为True
- batch_first:True则输入输出的数据格式为 (batch, seq, feature)
- dropout:除最后一层,每一层的输出都进行dropout,默认为: 0
- bidirectional:True则为双向lstm默认为False
输入:input, (h0, c0)
输出:output, (hn,cn)
h 0 和 C 0 h_0和C_0 h0和C0是第一个LSTM cell的隐藏层状态。 h n 和 C n h_n和C_n hn和Cn是最后一个LSTM cell的隐藏层状态。
输入数据格式:
input(seq_len, batch, input_size)
h0(num_layers * num_directions, batch, hidden_size)
c0(num_layers * num_directions, batch, hidden_size)
这里解释一下为什么输入数据的格式是 [ s e q l e n , b a t c h , i n p u t s i z e ] [seqlen, batch, inputsize] [seqlen,batch,inputsize]。比如第一个LSTM,输入的是 b a t c h batch batch个句子的第一个单词,第二个LSTM输入是 b a t c h batch batch个句子的第二个单词,依次类推。总共有seq_len个LSTM,所以输入的结构是 [ s e q l e n , b a t c h , i n p u t s i z e ] [seqlen, batch, inputsize] [seqlen,batch,inputsize]
再解释一下 h 0 h_0 h0的维度,先解释最后一维,由于 h 0 h_0 h0是LSTM的内部参数,所以第三维是hidden_isze,总共有batch个句子,每个句子都有一个 h 0 h_0 h0,所以第二维是batch,总共有num_layers层LSTM,每一层都有一个初始状态 h 0 h_0 h0,如果是双向LSTM,则有两个 h 0 h0 h0,所以第一维是num_layers * num_directions。 c 0 c_0 c0的维度同理。
输出数据格式:
output(seq_len, batch, hidden_size * num_directions)
hn(num_layers * num_directions, batch, hidden_size)
cn(num_layers * num_directions, batch, hidden_size)
num_directions指的是单向(值为1)还是双向(值为2)。
import torch
import torch.nn as nn
from torch.autograd import Variable
# 构建网络模型---输入矩阵特征数input_size、输出矩阵特征数hidden_size、层数num_layers
rnn = nn.LSTM(10,20,2) # (input_size,hidden_size,num_layers)
inputs = torch.randn(5,3,10) # (seq_len,batch_size,input_size)
h0 = torch.randn(2,3,20) # (num_layers* 1,batch_size,hidden_size)
c0 = torch.randn(2,3,20) # (num_layers*1,batch_size,hidden_size)
num_directions=1 # 因为是单向LSTM
output,(hn,cn) = rnn(inputs,(h0,c0)) # (h0,c0)也可以用none来代替,使系统来初始化
print(output.size())
print(hn.size())
print(cn.size())
'''输出
torch.Size([5, 3, 20])
torch.Size([2, 3, 20])
torch.Size([2, 3, 20])
'''
batch_first 输入输出的第一维是否为 batch_size,默认值 False。因为 Torch 中,人们习惯使用Torch中带有的dataset,dataloader向神经网络模型连续输入数据,这里面就有一个 batch_size 的参数,表示一次输入多少个数据。 在 LSTM 模型中,输入数据必须是一批数据,为了区分LSTM中的批量数据和dataloader中的批量数据是否相同意义,LSTM 模型就通过这个参数的设定来区分。 如果是相同意义的,就设置为True,如果不同意义的,设置为False。 torch.LSTM 中 batch_size 维度默认是放在第二维度,故此参数设置可以将 batch_size 放在第一维度。如:input 默认是(4,1,5),中间的 1 是 batch_size,指定batch_first=True后就是(1,4,5)。所以,如果你的输入数据是二维数据的话,就应该将 batch_first 设置为True;
nn.GRU()与nn.LSTM类似,不再赘述。