【Python】【机器学习】企业欺诈识别
机器学习越来越多地在企业应用,本文跟大家分享一个采用机器学习方法,利用python对企业欺诈进行识别的具体案例。

一、加载数据

1 加载库
首先加载pandas库,并设置数据读取文件夹。
import os
import pandas as pd
os.chdir(r'F:\公众号\3.企业欺诈识别\audit_data') #设置数据读取的文件夹
2 加载数据
接着用read_csv函数读取数据。
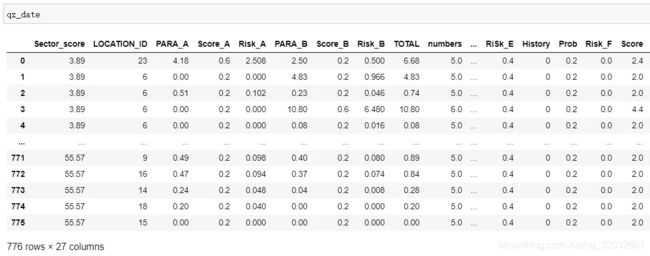
qz_date = pd.read_csv('audit_risk.csv') #读取数据
得到结果如下:
注:如需本文数据,请到公众号中回复“企业欺诈识别”即可免费获取。
本文数据776行、27列,其中每一行代表一个企业。前面的26列每一列代表一个特征,最后一列(取名为Risk)代表标签列,值为1表示企业存在欺诈,值为0表示企业不存在欺诈。
二、数据预处理
现实中,由于数据来源可能比较杂,建模数据可能会存在一些问题。所以我们在正式建模之前要先对数据进行分析处理。比如,看数据是否存在文本值,由于能输入到模型中去的一般是数值型数据,所以需要把文本型数据转换成数值型数据(例:性别列,“男”转换成1,“女”转换成0)。
有时数据中会存在缺失值,直接建模会报错,需要用别的数据进行填充(可以采用0值、均值、分位数等填充)。一般数据预处理分为两部分,首先看标签列的数据分布和缺失情况,再看特征列的数据情况。接下来我们进入具体的数据预处理环节。
1 分析标签列的数据分布
首先用value_counts函数看下标签列中0和1的分布情况,并查看该列是否存在缺失值和有问题的值。
qz_date.Risk.value_counts()
得到结果如下:

说明776家企业中,有305家企业存在欺诈行为(标记为1),471家企业不存在欺诈行为(标记为0)。数据类型为int64(整形),没有缺失值,所以不需要对该列进行处理。
2 特征列文本值处理
首先看下哪些列中存在文本值,具体语句如下:
import numpy as np
qz_date.applymap(np.isreal).all(0)
参数详解:
np.isreal函数表示对元素进行判断,如果是实数(数值型)就返回结果True,否则返回False。
.applymap函数表示对qz_date数据框中的每个元素进行判断,如果是数值型就返回True,否则返回False。返回的结果是和原数据框结构相同的布尔型数据框。
.all(0)表示按列对布尔型数据框进行判断,全为True返回True,否则返回False。如果把0变成1,则是按行进行判断。
得到结果如下:

可以发现只有LOCATION_ID这一列存在文本型数据,其它列都是数值型数据。接着把存在文本数据的列强制转换成数值型的列,具体语句如下:
qz_date.LOCATION_ID = pd.to_numeric(qz_date.LOCATION_ID, errors = 'coerce')
其中pd.to_numeric表示把其它类型的数据转换成数值型,errors='coerce’表示用空值填充异常数据。现在再来看下数据中是否存在文本数据,语句如下:
qz_date.applymap(np.isreal).all(0)
得到结果如下:

从上面的图片中可以看出,LOCATION_ID这一列经过转换变成数值型的。
3 特征列缺失值处理
首先用isnull函数找出所有的空值元素,再用any函数找出存在缺失值的列。
qz_date.isnull().any(0)
得到结果如下:

可以发现存在缺失值的列为:LOCATION_ID和Money_Value列。如果想要找出存在缺失值的行,把any函数中的0换成1即可。接下来对存在缺失值的元素进行填充。一种办法是用0值进行填充,具体语句如下:
qz_date = qz_date.fillna(0)
另一种办法可以用均值进行填充,具体语句如下:
from sklearn.impute import SimpleImputer
imp = SimpleImputer(strategy='mean')
qz_date = imp.fit_transform(qz_date)
如果想用别的分位数填充,或根据经验填充,大家可以自己去研究一下,也都是可以实现的。注意:本文采用的是0值填充。
三、训练集和测试集划分
由于训练模型的目的,是为了做预测。假设我现在有一批新的企业,只有这些企业的特征数据,不知道这些企业是否存在欺诈。我们想根据过去的经验,预测这些新的企业存在欺诈的可能性,那么我们需要判断这个模型能否做预测,也就是需要评估这个模型效果怎么样。那怎样来衡量模型效果呢?
可以把数据分为训练集和测试集,训练集的数据用来训练模型。训练好的模型在测试集上进行预测,这时会有一个预测结果,也有一个原始的真实结果。把这两种结果进行对比,就可以评估模型的好坏。所以接下来就给出分训练集和测试集的代码。
1 区分特征变量和标签变量
在分训练集和测试集之前,先把特征变量(自变量X)和标签变量(因变量y)分成两个子数据框。一般标签变量放在数据框的最后一列,所以可以用如下语句生成:
y = qz_date[qz_date.columns[len(qz_date.columns)-1]]
那么其余变量就是特征变量,本文不考虑对特征变量进行筛选,所有变量直接入模。特征变量X就是第一列到倒数第二列,具体语句如下:
X = qz_date.iloc[:,0:-1]
2 区分训练集和测试集
根据数据的大小,可以自定义训练集和测试集的占比,由于数据中蕴含了比较多的信息,而在模型训练时想要多获取一些信息。所以一般训练集的数据要多于测试集。可以把训练集和测试集的比例划分成3:1或7:3或8:2,也可以自己尝试其它比例。具体语句如下:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
tran_test_split函数可以把数据按照一定的比例随机地划分成训练集和测试集。如果缺失test_size参数,表示按7:3的默认比例划分训练集和测试集。本文设置了test_size=0.2,所以测试集的数据占比为20%。
四、模型训练
接下来进入最关键的模型训练部分,不同的数据、不同的场景可以采用不同的模型。本文选用K近邻分类算法进行欺诈建模,对建模感兴趣的同学也可以看看之前的几篇建模文章:逻辑回归项目实战-附Python实现代码、孤立森林(Isolation Forest)、DBSCAN聚类。
具体建模语句如下:
from sklearn.neighbors import KNeighborsClassifier
estimator = KNeighborsClassifier() #采用默认参数
estimator.fit(X_train, y_train) #用训练集数据训练模型
这里采用默认参数对模型进行训练,感兴趣的同学可以自己研究调整参数对模型的影响。estimator就是我们训练好的模型,可以用这个模型来预测新企业是否存在欺诈风险。
五、效果评估
可以用简单的准确率来衡量模型的好坏,即模型在测试集上预测值和真实值相同的比例。具体语句如下:
y_predicted = estimator.predict(X_test) #用训练好的模型预测测试集数据
print(np.mean(y_test == y_predicted)) #判断预测值和真实值相等的比例
得到结果如下:
![]()
说明有97%左右的数据,预测值等于真实值。但是如果标签值的数据分布很不均匀,假设99%的企业是正常企业,1%的企业是欺诈企业,如果我把所有企业都预测成正常企业。
按照刚刚的准确率去衡量模型效果,发现准确率高达99%。但是我想要找的欺诈企业没有找出来,其实结果对于我而言是没有意义的。所以模型效果的评价不应单看准确率,还可以参考模型效果评价—混淆矩阵、模型评价指标—KS等等。感谢趣的同学可以看看本公众号以前的一些模型评价文章。
六、完整代码
至此,企业欺诈识别讲解完毕,全量代码如下:
import os
import numpy as np
import pandas as pd
from sklearn.impute import SimpleImputer
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
os.chdir(r'F:\公众号\3.企业欺诈识别\audit_data') #设置数据读取的文件夹
qz_date = pd.read_csv('audit_risk.csv') #读取数据
qz_date.LOCATION_ID = pd.to_numeric(qz_date.LOCATION_ID, errors = 'coerce') #把文本数据转换成数值型数据
qz_date = qz_date.fillna(0) #用0填充数据框中的空值
#imp = SimpleImputer(strategy='mean')
#qz_date = imp.fit_transform(qz_date) #用均值填充缺失数据
X = qz_date.iloc[:,0:-1] #特征变量
y = qz_date[qz_date.columns[len(qz_date.columns)-1]] #标签变量
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) #区分训练集和测试集
estimator = KNeighborsClassifier() #采用默认参数
estimator.fit(X_train, y_train) #用训练集数据训练模型
y_predicted = estimator.predict(X_test) #用训练好的模型预测测试集数据
print(np.mean(y_test == y_predicted)) #判断预测值和真实值相等的比例
现在如果有一批待评估欺诈风险的新企业,可以用训练好的模型estimator去预测这批企业的欺诈风险。具体语句如下:
y_predicted = estimator.predict(X_new)
得到结果如下:

其中1表示企业可能存在欺诈风险,0表示企业可能不存在欺诈风险。
你可能感兴趣:
用Python绘制皮卡丘
用Python绘制词云图
Python人脸识别—我的眼里只有你
Python画好看的星空图(唯美的背景)
【Python】情人节表白烟花(带声音和文字)
用Python中的py2neo库操作neo4j,搭建关联图谱
Python浪漫表白源码合集(爱心、玫瑰花、照片墙、星空下的告白)
