Hive优化
https://zhuanlan.zhihu.com/p/165343463?utm_source=wechat_session&utm_medium=social&utm_oi=1118145344197935104
目录
- 减少处理的数据量
- 合理的设置map、reduce数量
- 小文件合并
- Shuller过程优化
- join优化
- 数据倾斜优化
减少处理的数据量
分区裁剪
为了尽早的过滤掉数据,减少每个阶段的数据量,对于分区表要加分区
查询涉及分区表时,在where子句或on子句中限制分区范围
select * from table where ds='2020-07-29'
列裁剪
值读取需要的列,忽略其他不关心的列,避免全表扫描
select * from..... -------->select col1,col2 from .......
合理的设置map、reduce数量
增加map、reduce个数,增加并发数,可以提高计算速度,但是。。。
如果map、reduce数量过多会怎样
从单一任务角度看
- task overhead 过大
- 调度成本大
从客户资源角度看
- 抢占资源,造成任务拥堵
默认Map数的计算公式为
default_num=total_size/block_size
影响map的个数因素为:
- HDFS块的大小(默认为128M)
- 文件的大小
- 文件的个数
- splitSize的大小(mapred.max.split.size和mapred.min.split.size)决定每个map处理的最大最小的文件大小
splitSize=Math.max(minSize,Math.min(maxSize,blockSize))
mapred.max.split.size指的是数据最大分割单元大小(默认为256M)
mapred.min.split.size指的是数据最小分割单元大小(默认为1B)
可以通过参数mapred.map.tasks来设置期望的map个数,但是这个个数只有大于default_num的时候才生效
合理设置reduce的个数
reduce个数并不是越多越好
和map一样,启动和初始化reduce也会消耗时间和资源;
另外,有多少个reduce,就会有多少个输出文件,如果小文件过多,而这些小文件是下游的输入,则会造成小文件过多的问题
只有单一的reduce也不是很好,什么情况下会造成只有一个reduce呢?
很多时候你会发现不管任务中的数据量有多大,不管你有没有设置reduce的个数,任务总是只有一个reduce
其实,只有一个reduce的情况,除了数据量小于hive.exec.reducers.bytes.per.reducer的参数情况外,还有以下原因:
- 没有group by 的汇总
- 用了order by
- 有笛卡尔积
在未设置reduce个数的情况下,计算公式如下
reducers=Math.min(maxReducers,totalInputFileSize/bytesPerReduces)
maxReducers有参数hive.exec.reduces.max设置(默认999)
bytesPerReduces由参数hive.exec.reducers.bytes.per.reducer设置(默认是1G)
举个例子:
1、如果一个文件不超过1G,那么只有一个reduce
2、如果一个文件有8.2G,那么有9个reduce
3、如果一个文件有8.2G,调整hive.exec.reducers.bytes.per.reducer参数的值,比如set hive.exec.reducers.bytes.per.reducer=500000000;(500M)那么会有18个reduce产出
4、直接设置reduce个数
set mapred.reduce.tasks=15;就会有15个reduce产生
小文件合并
输入阶段合并(即在map前合并小文件)
1、执行map前进行小文件合并
需要更改Hive的输入文件格式,即参数hive.input.format,默认值是org.apache.hadoop.hive.ql.io.HiveInputFormat,我们改成 set org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
2、每个map最大输入大小,决定合并后的文件数
set mapred.max.split.size=256000000;
3、一个节点上split的至少的大小,决定多个data node 上的文件是否需要合并
set mapred.min.split.size.per.node=100000000;
4、一个交换机下split的至少的大小,决定多个交换机上的文件是否合并
set mapred.min.split.size.per.rack=100000000;
mapred.min.split.size.per.node和mapred.min.split.size.per.rack,含义是单节点和单机架上的最小split大小。如果发现有split大小小于这两个值(默认都是100MB),则会进行合并。具体逻辑可以参看Hive源码中的对应类。
输出阶段合并
直接将hive.merge.mapfiles和hive.merge.mapredfiles都设为true即可,前者表示将map-only任务的输出合并,后者表示将map-reduce任务的输出合并。
另外,hive.merge.size.per.task可以指定每个task输出后合并文件大小的期望值,hive.merge.size.smallfiles.avgsize可以指定所有输出文件大小的均值阈值,默认值都是1GB。如果平均大小不足的话,就会另外启动一个任务来进行合并。
shuffle过程优化
什么事shuffle,shuffle就是map端输出到reduce输入的过程
可能存在的问题
- 磁盘IO
- 网络IO
优化思路
- 减少各种IO
优化方法
中间结果压缩(集群默认是开启的)
开启压缩中间结果
- set mapred.compress.map.output=true;
设置中间压缩算法
- set mapred.compress.output.compresssion.codec=com.hadoop.compression.lzo.LzoCodec
Join优化
利用map join特性
如果两张表关联,一张表非常大,一张表非常小,可采用mapjoin,小表叫build table,大表叫probe table
小表放左边,开启hive.auto.convert.join=true(默认是开启的)
select /*+mapjoin(a)*/ a.event_type,b.upload_time
from calendar_event_code a
inner join (
select event_type,upload_time from calendar_record_log
where pt_date = 20190225
) b on a.event_type < b.event_type;上面的语句中加了一条map join hint,以显式启用map join特性。早在Hive 0.8版本之后,就不需要写这条hint了。map join还支持不等值连接,应用更加灵活。
多表join时key相同
这种情况会将多个join合并为一个MR job来处理,例如:
select a.event_type,a.event_code,a.event_desc,b.upload_time
from calendar_event_code a
inner join (
select event_type,upload_time from calendar_record_log
where pt_date = 20190225
) b on a.event_type = b.event_type
inner join (
select event_type,upload_time from calendar_record_log_2
where pt_date = 20190225
) c on a.event_type = c.event_type;如果上面两个join的条件不相同,比如改成a.event_code = c.event_code,就会拆成两个MR job计算。
负责这个的是相关性优化器CorrelationOptimizer,它的功能除此之外还非常多,逻辑复杂,参考Hive官方的文档可以获得更多细节:https://cwiki.apache.org/confluence/display/Hive/Correlation+Optimizer。
数据倾斜优化
什么是数据倾斜,就是大量相同的key被分到了一个分区中,导致出现"一人累死,其他人闲死"的情况。
数据倾斜的表现,任务进度长时间维持在99%(或100%),查看任务监视页面,发现只有少量(1个或几个)子任务未执行,因为其他处理的数据量和其他reduce差异过大,单一的reduce记录数和平均记录数差异过大,通常可能达到3倍甚至更多。最长时长也远大于平均时长
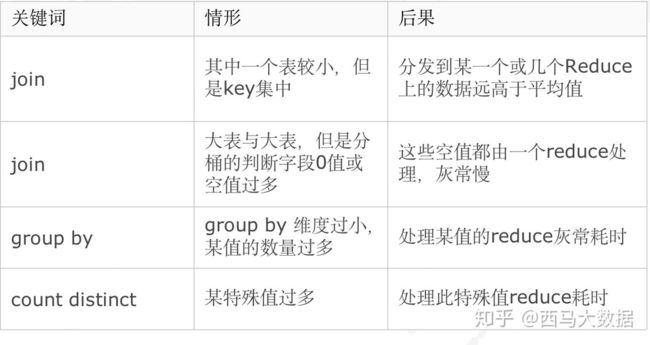
数据倾斜优化--group by
- 先不按group by字段分发,随机分发做一次聚合
- 额外启动一轮job,拿前面聚合过的数据按group by字段分发再算结果
空值或无意义值
这种情况很常见,比如当事实表是日志类数据时,往往会有一些项没有记录到,我们视情况会将它置为null,或者空字符串、-1等。如果缺失的项很多,在做join时这些空值就会非常集中,拖累进度。
因此,若不需要空值数据,就提前写where语句过滤掉。需要保留的话,将空值key用随机方式打散,例如将用户ID为null的记录随机改为负值:
select a.uid,a.event_type,b.nickname,b.age
from (
select
(case when uid is null then cast(rand()*-10240 as int) else uid end) as uid,
event_type from calendar_record_log
where pt_date >= 20190201
) a left outer join (
select uid,nickname,age from user_info where status = 4
) b on a.uid = b.uid;不同数据类型
这种情况不太常见,主要出现在相同业务含义的列发生过逻辑上的变化时。
举个例子,假如我们有一旧一新两张日历记录表,旧表的记录类型字段是(event_type int),新表的是(event_type string)。为了兼容旧版记录,新表的event_type也会以字符串形式存储旧版的值,比如'17'。当这两张表join时,经常要耗费很长时间。其原因就是如果不转换类型,计算key的hash值时默认是以int型做的,这就导致所有“真正的”string型key都分配到一个reducer上。所以要注意类型转换:
select a.uid,a.event_type,b.record_data
from calendar_record_log a
left outer join (
select uid,event_type from calendar_record_log_2
where pt_date = 20190228
) b on a.uid = b.uid and b.event_type = cast(a.event_type as string)
where a.pt_date = 20190228;
数据倾斜优化
join时存在数据倾斜,优化分为两大方面:
- skew join
- 重写业务逻辑
skew join
- set hive.Optimize.skewjoin=true
记录数超过参数hive.skewjoin.key(默认为100000)设置大小就是特殊值
如何排查任务是否正常
- map个数
- reduce个数
- hdfs读数据量,扫全表
- 每个task读数据量:数据倾斜
- 长尾task
- 业务查询分析
常见问题
涉及到分区表时,未设置分区限制
内存不足发生阶段,找到是在哪个阶段发生的并处理,map阶段,shuffle阶段,reduce阶段
map阶段:
- 一般存在mapjoin
- 通过设置参数hive.auto.convert.join=false转为reduce端 common join
shuffle阶段:
- 由于map端输出较大,但shuffle端选择的是拷贝map输出到内存导致
- 降低单个shuffle能够消耗占reduce所有内存占比(set mapreduce.reduce.shuffle.memory.limit.precent=0.10)使shuffle阶段拷贝map输出时选择落磁盘
reduce阶段
- 单个reduce处理数据量过大
- 通过设置参数mapred.reduce.tasks或mapreduce.job.reduces修改reduce的个数
- 如果存在数据倾斜,单纯修改reduce个数没有用
解决方案
- 参数调节
- set hive.map.aggr=true (用于设置是否在map端聚合,默认为true)
- set hive.groupby.skewindata=true(决定group by 是否支持数据倾斜)
2.增加jvm内存
- 这适用于唯一值非常少,极少数值有非常多的记录值的情况,通过增加硬件资源进行调优
3.增加reduce的个数
- 这适用于唯一值非常多,这个字段的某些值有远远多于某些记录数,大量相同的key被partition到一个分区了,从而一个reduce执行了大量工作,而增加了reduce个数,相对来说会好一点,毕竟节点多了,就算工作了还是不均匀,那还是会好一点
4.自定义分区
- 需要用户继承partition类,指定分区策略,分区策略弄的号,效果会比较显著。
5.重新设计key
- 有一种方案是map时在key前面加一个随机数,避免造成热点问题。这样就不会大量的key都往一个节点,到了reduce端再把随机数去掉
如果还是出现数据倾斜。可以做以下处理
- set hive.exec.reduces.max=200
- set mapred.reduces.tasks=200;增大reduce个数
- set hive.groupby.mapaggr.checkinterval=100000----这个是group 的健对应记录条数超过这个值会进行分拆,值根据具体数据量进行决定
- set hive.groupby.skewindata=true ,如果group by 出现数据倾斜,应该设置为true。
- set hive.skewjoin.key=100000 ,这个是join的健对应的记录条数如果超过这个值,会进行拆分,值根据具体数据量进行决定
- set hive.Optimize.skewjoin=true,如果join出现数据倾斜,应该设置为true
- 启动一个job应该多做事情,一个job能完成的事,不要两个job来做。
- 合理设置reduce个数,不宜多,也不宜少,看自己的数据量和资源决定
- 使用 hive.exec.parallel 参数控制同一个sql中不同的job是否可以同时运行,提高作业并发
前面主要讲的是一些hive参数的设置,和集群方面的设计,下面主要讲下从sql层面上怎么进行优化,因为对于一个业务方来说,只需要写sql。而且sql的优化往往会大大的提高任务的执行效率
sql优化
1.使用相同的连接健
- 当对三个或者更多表进行join的时候,如果每个on条件都采用相同的条件,那么只会产生一个MapReduce job
2.尽量原子化操作
- 尽量避免一段sql包含复杂逻辑,可以采用中间表来完成复杂逻辑
3.用insert into 代替union all
- 如果union all 的部分大于2,或者每个union all的表数据量过大,应该拆分多个inset,测试表明,效率能提升50%
insert overwrite table tablename partition(ds=.....)
select * from (select ... from A
union all select .... from B
union all select .... from C)R
where ....
改为
insert overwrite table tablename partition(ds=.....) select ... from A
insert overwrite table tablename partition(ds=.....) select ... from B
insert overwrite table tablename partition(ds=.....) select ... from C4.空值或无意义值
这种情况很常见,比如当事实表是日志类数据时,往往会有一些项没有记录到,我们视情况会将它置为null,或者空字符串、-1等。如果缺失的项很多,在做join时这些空值就会非常集中,拖累进度。
- 过滤掉null值不连接
select * from log a join b on a.userId is not null and a.userId=b.userId
union all
select * from log where a.userId is null- 函数过滤null
select * from log a join b on case when a.userId is null then cancat('hive',RAND())
else a.userId End =b.userId 方案一job数为2,方案2job数为1
5.不同数据类型
这种情况不太常见,主要出现在相同业务含义的列发生过逻辑上的变化时。
举个例子,假如我们有一旧一新两张日历记录表,旧表的记录类型字段是(event_type int),新表的是(event_type string)。为了兼容旧版记录,新表的event_type也会以字符串形式存储旧版的值,比如'17'。当这两张表join时,经常要耗费很长时间。其原因就是如果不转换类型,计算key的hash值时默认是以int型做的,这就导致所有“真正的”string型key都分配到一个reducer上。所以要注意类型转换:
select a.uid,a.event_type,b.record_data
from calendar_record_log a
left outer join (
select uid,event_type from calendar_record_log_2
where pt_date = 20190228
) b on a.uid = b.uid and b.event_type = cast(a.event_type as string)
where a.pt_date = 20190228;6.消灭子查询的group by
select * from(select * from A group by col1,col2
union all select * from B group by col1,col2)
group by col1,col2)
改为
select * from(select * from A
union all select * from B)
group by col1,col2)sort by代替order by
HiveQL中的order by与其他SQL方言中的功能一样,就是将结果按某字段全局排序,这会导致所有map端数据都进入一个reducer中,在数据量大时可能会长时间计算不完。
如果使用sort by,那么还是会视情况启动多个reducer进行排序,并且保证每个reducer内局部有序。为了控制map端数据分配到reducer的key,往往还要配合distribute by一同使用。如果不加distribute by的话,map端数据就会随机分配到reducer。
举个例子,假如要以UID为key,以上传时间倒序、记录类型倒序输出记录数据:
select uid,upload_time,event_type,record_data
from calendar_record_log
where pt_date >= 20190201 and pt_date <= 20190224
distribute by uid
sort by upload_time desc,event_type desc;
- distribute by 控制map的数量
- sort by 不是全局排序,只是会保证每个reduce有序
- order by全局排序,但是只会有一个reduce
- cluster by col1 等价于 distribute by col1 sort by col1
总结
观察hadoop的处理过程,有几个显著的特征:
- 不怕数据多,就怕数据倾斜
- 对job数比较多的任务,运行效率相对比较低,比如即使是一张只有几百行表的数据,多次关联汇总,产生十几个job,每半个小时是跑不完的。主要的map reduce作业初始化时间比较长
- 对于sum count这些函数,不存在数据倾斜
- 对count(distinct ),效率较低,数据一多,准出问题,特别是多个count(distinct) 效率更慢
优化可以从这几个方面入手
- 解决数据倾斜问题
- 减少job数
- 合理设置map reduce task的个数,能够提升效率(比如10W+的表,用120个reduce,相当浪费,用一个就够了)
- 尽量手写sql解决数据倾斜。set hive.groupby.skewindata=true是通用手法,有时候没有改进sql带来的效率提升大
- 不用count(distinct) 语法
- 小文件进行合并
- 优化时把握整体,单个作业最优不如整体最优
优化后的任务,效率提升不止提升了一点点。。。
开发过程中还是需要注意下语句使用的。。。
套用公司大佬的一句话。优化其实就是一个思路。需要计算的内容提前把数据量缩小。。
文章灵感主要来自是公司内部的分享,可能还有不足的点,欢迎大佬指点改进
共勉。。。。。