【读点论文】SQUEEZENET: ALEXNET-LEVEL ACCURACY WITH 50X FEWER PARAMETERS AND <0.5MB MODEL SIZE
SQUEEZENET: ALEXNET-LEVEL ACCURACY WITH 50X FEWER PARAMETERS AND <0.5MB MODEL SIZE
ABSTRACT
- 最近对深度卷积神经网络(CNN)的研究主要集中在提高准确性上。对于给定的精度水平,通常可以识别出多个达到该精度水平的CNN架构。
- 在同等精度的情况下,较小的CNN架构至少提供了三个优点:
- (1)较小的CNN在分布式训练期间需要较少的跨服务器通信。
- (2)较小的CNN需要较少的带宽来从云中向自动驾驶汽车导出新模型。
- (3)更小的CNN更适合部署在FPGAs等内存有限的硬件上。
- 为了提供所有这些优势,本文提出了一个名为SqueezeNet的小型CNN架构。SqueezeNet在ImageNet上实现了AlexNet级别的精度,参数减少了50倍。此外,通过模型压缩技术,本文能够将SqueezeNet的模型文件压缩到0.5MB以下(比AlexNet小510倍)。
- SqueezeNet架构可从这里下载:https://github.com/DeepScale/SqueezeNet
INTRODUCTION AND MOTIVATION
-
最近对深度卷积神经网络(CNN)的许多研究都集中在提高计算机视觉数据集的准确性上。对于给定的精度水平,通常存在多个CNN架构来实现该精度水平。给定同等精度,具有较少参数的CNN架构具有几个优点:
-
更高效的分布式训练。服务器之间的通信是分布式CNN训练的可扩展性的限制因素。对于分布式数据并行训练,通信开销与模型中参数的数量成正比。简而言之,小模型训练更快,因为需要更少的交流。
-
向客户端导出新模型时开销更少。对于自动驾驶,特斯拉等公司会定期将新模型从服务器复制到客户的汽车上。这种做法通常被称为over-the-air update(空中下载更新,无线更新)。《消费者报告》发现,特斯拉Autopilot半自动驾驶功能的安全性随着最近的over-the-air update而逐步提高(《消费者报告》,2016年)。然而,当今典型的CNN/DNN模型的空中更新可能需要大量的数据传输。对于AlexNet,这将需要从服务器到汽车的240MB通信。较小的模型需要较少的流量传输,使得频繁更新更加可行。
-
over-the-air update:无线 (OTA) 更新是向移动设备无线传输新软件、固件或其他数据。
- 就像IT软件和操作系统如何从供应商那里接收定期更新一样,车辆也从其制造商那里接收软件更新。软件更新是整体用户体验不可或缺的一部分,因为它们包含重要的功能增强和关键的安全补丁。
- 传统上,软件更新是在服务中心亲自执行的。但是,随着当今汽车的互联程度越来越高,原始设备制造商正在尝试一种新方法,通过无线(互联网)直接向汽车发送和安装软件更新,就像智能手机和计算机接收更新一样。此类软件更新称为无线 (OTA) 汽车更新。
- OTA汽车更新通常应用于车辆内的两种主要系统:驾驶控制和信息娱乐。驱动控制系统的更新包括与ADAS、动力总成和底盘相关的功能升级和安全补丁。信息娱乐系统的更新包括地图更新和应用程序增强功能。尽管信息娱乐系统不会直接影响驾驶,但它仍然是必须更新和保护的关键组件,因为它包含敏感的个人数据。
- OTA更新的另一个重要作用是它们可以防止车辆贬值。由于现代车辆本质上是车轮上的计算机,因此它们的折旧速度比传统车辆快得多。如果不定期更新,支持软件的功能可能会在几年后恶化并变得缓慢且无法使用。OTA更新可防止这种情况发生,并保持机上体验的新鲜感。
- 为了启用OTA更新,汽车必须配备远程信息处理控制单元(TCU),这是一个包含移动通信接口(例如LTE,5G)和存储器以存储驾驶和车辆数据的硬件。TCU 还必须能够恢复数据,以防万一需要删除更新。每当有可用的更新时,OEM 都会从基于云的服务器将软件包交付给其车辆。
- 第一个成功执行OTA更新的OEM是特斯拉。通用汽车和福特等其他制造商也迅速跟进。能够提供OTA更新对于电动汽车制造商来说尤其重要,因为它使他们能够尽早将车辆推向市场以获得早期优势,同时在销售后致力于质量保证和改进。
-
可行的FPGA和嵌入式部署。FPGAs通常具有小于10MB的片内存储器,并且没有片外存储器或存储。一个足够小的模型可以直接存储在FPGA上,而不是受到存储器带宽的限制,同时视频帧通过FPGA实时流动。此外,当在专用集成电路(ASIC)上部署CNN时,足够小的模型可以直接存储在芯片上,并且更小的模型可以使得ASIC能够安装在更小的管芯上。
-
-
如上所示,较小的CNN架构有几个优点。考虑到这一点,本文直接关注识别CNN架构的问题,与众所周知的模型相比,该架构具有更少的参数,但具有同等的精度。发现了这样一种架构,本文称之为SqueezeNet。此外,提出了本文的尝试,在一个更严格的方法来搜索新的CNN架构的设计空间。
-
从LeNet5到DenseNet,反应卷积网络的一个发展方向:提高精度。这里我们开始另外一个方向的介绍:在不大幅降低模型精度的前提下,最大程度的提高运算速度。
-
提高运算所读有两个可以调整的方向:
- 减少可学习参数的数量;
- 减少整个网络的计算量。
-
这个方向带来的效果是非常明显的:
- 减少模型训练和测试时候的计算量,单个step的速度更快;
- 减小模型文件的大小,更利于模型的保存和传输;
- 可学习参数更少,网络占用的显存更小。
RELATED WORK
MODEL COMPRESSION
- 本文工作的首要目标是确定一个模型,该模型具有很少的参数,同时保持准确性。为了解决这个问题,一个明智的方法是采用现有的CNN模型,并以有损的方式对其进行压缩。
- 事实上,围绕模型压缩的主题已经出现了一个研究团体,并且已经报告了几种方法。Denton等人的一种相当直接的方法是将奇异值分解(SVD)应用于预训练的CNN模型。Han等人开发了网络修剪,它从预训练的模型开始,然后用零替换低于某个阈值的参数以形成稀疏矩阵,最后在稀疏CNN上执行几次迭代训练。
- 最近,Han等人扩展了他们的工作,将网络剪枝与量化(8位或更少)和huffman编码相结合,创建了一种称为深度压缩的方法,并进一步设计了一种称为EIE的硬件加速器,它直接在压缩模型上操作,实现了显著的加速和节能。
CNN MICROARCHITECTURE
- 卷积已经在人工神经网络中使用了至少25年(论文写作于2016年);LeCun等人在20世纪80年代后期帮助普及了用于数字识别应用的CNN。在神经网络中,卷积滤波器通常是3D的,以高度、宽度和通道作为关键维度。
- 当应用于图像时,CNN滤波器的第一层(即RGB)通常有3个通道,在每个后续层Li中,滤波器的通道数与 L i − 1 L_{i-1} Li−1滤波器的通道数相同。LeCun等人的早期工作使用5×5通道滤波器,2014年的VGG 架构广泛使用3×3滤波器。Network-in-Network 和GoogLeNet系列架构在某些图层中使用1x1卷积。
- 随着设计非常深的CNN的趋势,手动选择每层的滤波器尺寸变得很麻烦。为了解决这个问题,已经提出了由具有特定固定组织的多个卷积层组成的各种更高级的构建块或模块。
- 例如,GoogLeNet论文提出了初始模块,它由许多不同维度的过滤器组成,通常包括1x1和3x3,有时加上5x5 ,有时是1x3和3x1 。许多这样的模块然后被组合,可能与附加的自组织层组合,以形成完整的网络。本文使用术语CNN微体系结构来指代各个模块的特定组织和维度。
CNN MACROARCHITECTURE
- 虽然CNN微体系结构指的是单独的层和模块,但我们将CNN宏体系结构定义为将多个模块组织成端到端CNN体系结构的系统级组织。
- 也许最近文献中最广泛研究的CNN宏观架构主题是网络中深度(即层数)的影响。Simoyan和Zisserman提出了具有12至19层的VGG 系列细胞神经网络,并报告了更深的网络在ImageNet-1k数据集上产生更高的准确性。K. He等人提出了多达30层的更深的CNN,提供了更高的ImageNet准确性。
- 跨多层或模块的连接选择是CNN宏观建筑研究的一个新兴领域。残差网络(ResNet) 和Highway Networks 均建议使用跳过多层的连接,例如将第3层的激活与第6层的激活相加连接。
- 本文将这些连接称为旁路连接。ResNet的作者提供了有和没有旁路连接的34层CNN的A/B比较;添加旁路连接使前5名的ImageNet精度提高了2个百分点。
NEURAL NETWORK DESIGN SPACE EXPLORATION
- 神经网络(包括深度和卷积神经网络)具有很大的设计空间,有许多微体系结构、宏体系结构、解算器和其他超参数的选项。社区想要获得关于这些因素如何影响神经网络的准确性(即设计空间的形状)的直觉,这似乎是很自然的。
- 关于神经网络的设计空间探索(DSE)的大部分工作都集中在开发自动方法来寻找提供更高精度的神经网络结构。这些自动DSE方法包括贝叶斯优化、模拟退火、随机搜索和遗传算法。
- 值得称赞的是,这些论文中的每一篇都提供了一个案例,在该案例中,所提出的DSE方法产生了一种与代表性基线相比实现更高精度的NN架构。然而,这些论文没有试图提供关于NN设计空间形状的直觉。在本文的后面,本文避开了自动化方法——相反,本文以这样一种方式重构CNN,可以进行原则性的A/B比较,以调查CNN架构决策如何影响模型大小和准确性。
SQUEEZENET: PRESERVING ACCURACY WITH FEW PARAMETERS
- 首先概述本文的CNN架构的设计策略。然后,介绍Fire模块,这是本文用来构建CNN架构的新构件。最后,使用本文的设计策略构建了SqueezeNet,它主要由Fire模块组成。
ARCHITECTURAL DESIGN STRATEGIES
-
本文中的首要目标是确定CNN架构,这些架构具有很少的参数,同时保持有竞争力的准确性。为了实现这一点,本文在设计CNN架构时采用了三种主要策略:
-
策略一。用1x1过滤器替换3x3过滤器。给定一定数量卷积滤波器的预算,本文将选择使这些滤波器中的大多数为1x1,因为1x1滤波器的参数比3x3滤波器少9倍。
-
策略二。将输入通道的数量减少到3×3个滤波器。考虑一个完全由3×3过滤器组成的卷积层。这一层的参数总数为 (number of input channels) * (number of filters) * (3*3)。因此,为了保持CNN中的参数总数较少,不仅要减少3×3滤波器的数量,还要减少3×3滤波器的输入通道数量。本文使用squeeze 层将输入通道的数量减少到3×3滤波器。
-
策略三。在网络后期进行下采样,以便卷积图层具有较大的激活图。在卷积网络中,每个卷积层都会产生一个输出激活图,其空间分辨率至少为1x1,通常远大于1x1。这些激活图的高度和宽度由以下因素控制:
-
(1)输入数据的大小(例如256×256的图像),
-
(2)在CNN架构中选择要下采样的层。
-
最常见的是,通过在一些卷积或池层中设置(stride > 1 ),将下采样设计到CNN架构中。如果网络中的早期层具有大的跨度,那么大多数层将具有小的激活图。相反,如果网络中的大多数层的跨距为1,并且大于1的跨距集中在网络的末端,则网络中的许多层将具有大的激活图。
- 在本文的术语中,“早期”层靠近输入数据。网络的“末端”是分类器。
-
本文的直觉是,在其他条件相同的情况下,大的激活图(由于延迟的下采样)可以导致更高的分类精度。事实上,K. He和H. Sun将延迟下采样应用于四种不同的CNN架构,在每种情况下,延迟下采样都导致更高的分类精度。
-
-
-
策略1和2是关于明智地减少CNN中的参数数量,同时试图保持准确性。策略3是在有限的参数预算下最大限度地提高精度。接下来,描述Fire模块,它是CNN架构的构建模块,使本文能够成功地采用策略1、2和3。
THE FIRE MODULE
-
SqueezeNet是由若干个Fire模块结合卷积网络中卷积层,降采样层,全连接等层组成的。一个Fire模块由Squeeze部分和Expand部分组成(注意区分和Momenta的SENet的区别)。
-
Squeeze部分是一组连续的 1*1 卷积组成,Expand部分则是由一组连续的 1*1 卷积和一组连续的 3*3 卷积cancatnate组成,因此 3*3卷积需要使用same卷积。
-
Squeeze部分 1*1 卷积的通道数记做 s 1 ∗ 1 s_{1*1} s1∗1 ,Expand部分 1*1 卷积和 3*3 卷积的通道数分别记做 e 1 x 1 e_{1x1} e1x1和 e 3 x 3 e_{3x3} e3x3。
-
本文将Fire模块定义如下。一个Fire module包括:一个squeeze卷积层(只有1×1个滤波器),进入一个具有1×1和3×3个卷积滤波器混合的扩展层;本文在下图中对此进行了说明。
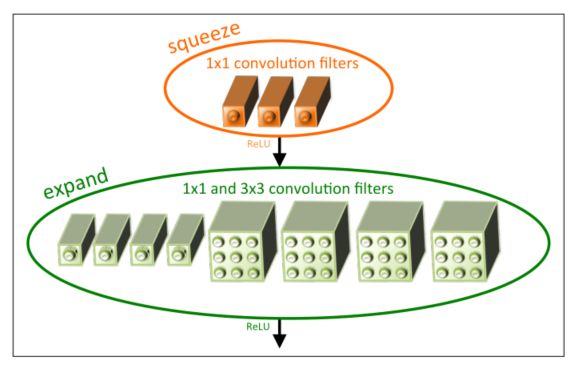
- Microarchitectural view: Fire模块中卷积滤波器的组织。在本例中, s 1 x 1 s_{1x1} s1x1= 3, e 1 x 1 e_{1x1} e1x1 = 4, e 3 x 3 e_{3x3} e3x3= 4。本文说明了卷积滤波器,但没有说明激活。
-
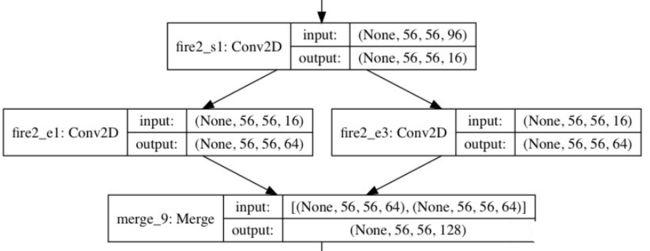
def fire_model(x, s_1x1, e_1x1, e_3x3, fire_name): # squeeze part squeeze_x = Conv2D(kernel_size=(1,1),filters=s_1x1,padding='same',activation='relu',name=fire_name+'_s1')(x) # expand part expand_x_1 = Conv2D(kernel_size=(1,1),filters=e_1x1,padding='same',activation='relu',name=fire_name+'_e1')(squeeze_x) expand_x_3 = Conv2D(kernel_size=(3,3),filters=e_3x3,padding='same',activation='relu',name=fire_name+'_e3')(squeeze_x) expand = merge([expand_x_1, expand_x_3], mode='concat', concat_axis=3) return expand -
在Fire模块中自由使用1x1过滤器是策略1的应用。本文在Fire模块中公开了三个可调维度(超参数): s 1 x 1 s_{1x1} s1x1、 e 1 x 1 e_{1x1} e1x1和 e 3 x 3 e_{3x3} e3x3。在Fire模块中, s 1 ∗ 1 s_{1*1} s1∗1是squeeze层中卷积核的数量(全是1x1), e 1 x 1 e_{1x1} e1x1是扩展层中1x1卷积核的数量, e 3 x 3 e_{3x3} e3x3是扩展层中3x3卷积核的数量。当本文使用Fire模块时,本文将 s 1 ∗ 1 s_{1*1} s1∗1设置为小于( e 1 x 1 e_{1x1} e1x1+ e 3 x 3 e_{3x3} e3x3),因此squeeze层有助于限制3x3滤波器的输入通道数量,如策略2所示。
-
-
-
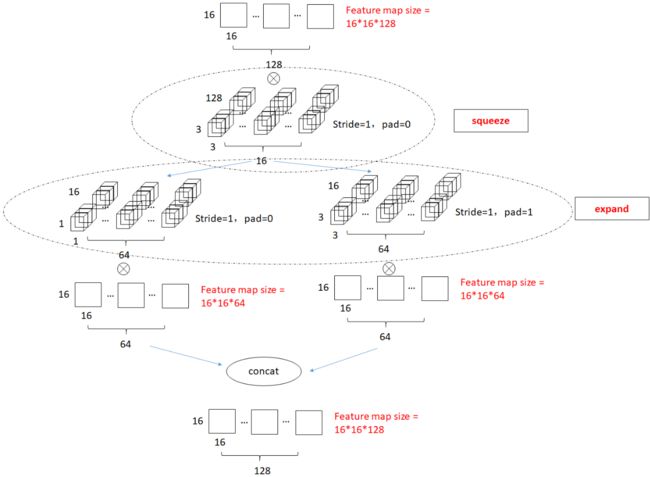
(1)squeeze模块:利用1*1卷积进行降维;
-
(2)expand模块:利用1*1卷积+3*3卷积组合升维;
-
(3)将pooling采样操作延后,可以给卷积层提供更大的激活图:更大的激活图保留了更多的信息,可以提供更高的分类准确率
-
(1)和(2)可以显著减少参数数量,(3)可以在参数数量受限的情况下提高准确率。
-
THE SQUEEZENET ARCHITECTURE
-
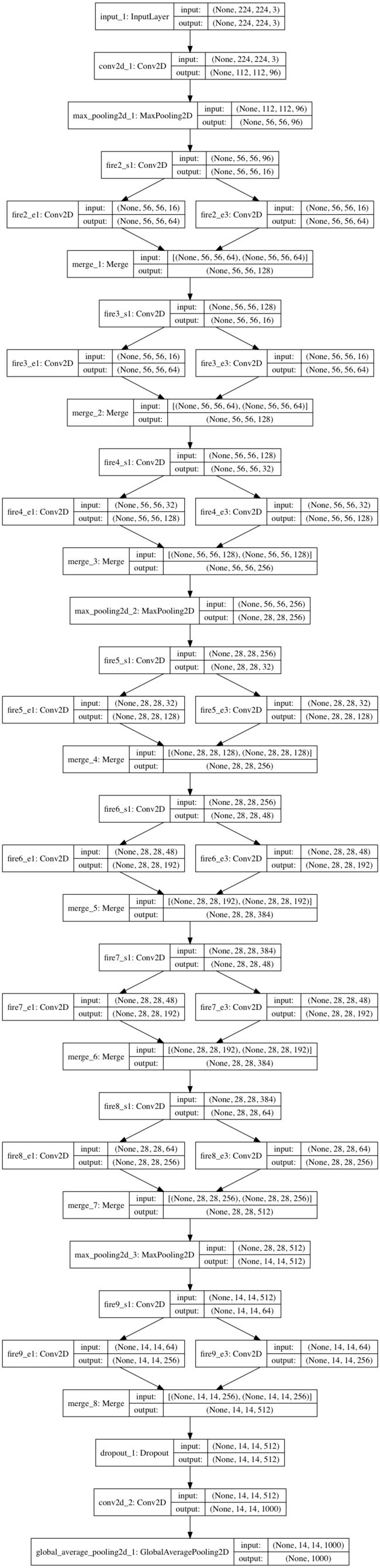
本文现在描述SqueezeNet CNN架构。在下图中展示了SqueezeNet从一个独立的卷积层(conv1)开始,然后是8个Fire模块(fire2-9),最后是一个conv层(conv10)。
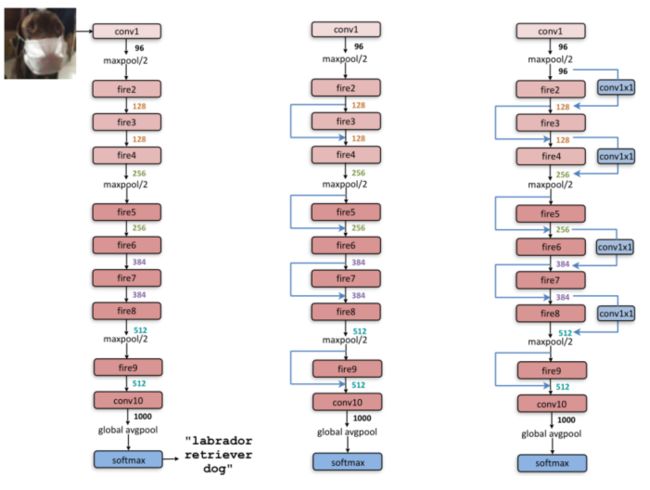
- 本文的SqueezeNet架构的宏观架构视图。左:SqueezeNet;中:带简单旁路的squeezenet;右:带复杂旁路的squeezenet。
- 激活函数默认都使用ReLU;
- fire9之后接了一个rate为0.5的dropout;
- 使用same卷积。
-
-
def squeezeNet(x): conv1 = Conv2D(input_shape = (224,224,3), strides = 2, filters=96, kernel_size=(7,7), padding='same', activation='relu')(x) poo1 = MaxPool2D((2,2))(conv1) fire2 = fire_model(poo1, 16, 64, 64,'fire2') fire3 = fire_model(fire2, 16, 64, 64,'fire3') fire4 = fire_model(fire3, 32, 128, 128,'fire4') pool2 = MaxPool2D((2,2))(fire4) fire5 = fire_model(pool2, 32, 128, 128,'fire5') fire6 = fire_model(fire5, 48, 192, 192,'fire6') fire7 = fire_model(fire6, 48, 192, 192,'fire7') fire8 = fire_model(fire7, 64, 256, 256,'fire8') pool3 = MaxPool2D((2,2))(fire8) fire9 = fire_model(pool3, 64, 256, 256,'fire9') dropout1 = Dropout(0.5)(fire9) conv10 = Conv2D(kernel_size=(1,1), filters=1000, padding='same', activation='relu')(dropout1) gap = GlobalAveragePooling2D()(conv10) return gap -
从网络的开始到结束,本文逐渐增加每个Fire模块的过滤器数量。SqueezeNet在层conv1、fire4、fire8和conv10之后以2的步幅执行最大池化;根据策略3,这些相对较晚的池放置。在下表中展示了完整的SqueezeNet架构。

- SqueezeNet architectural dimensions.
https://github.com/senliuy/CNN-Structures/blob/master/SqueezeNet.ipynb
OTHER SQUEEZENET DETAILS
- 为了使1x1和3x3过滤器的输出激活具有相同的高度和宽度,本文在扩展模块的3x3过滤器的输入数据中添加了一个1像素的零填充边界。
- ReLU适用于squeeze and expand 层的激活。
- 比率为50%的DropOut适用于fire9模块之后。
- 请注意SqueezeNet中缺少完全连接的层;这一设计选择的灵感来自NiN的架构。
- 当训练SqueezeNet时,本文从0.04的学习率开始,本文在整个训练过程中线性降低学习率。有关训练协议的详细信息(例如,批量大小、学习率、参数初始化),请参考https://github.com/DeepScale/SqueezeNet.的Caffe兼容配置文件
- Caffe框架本身不支持包含多个滤波器分辨率(例如1x1和3x3)的卷积层。为了解决这个问题,本文用两个单独的卷积层来实现扩展层:一个层使用1x1卷积,一个层使用3x3卷积。然后,本文在信道维度上将这些层的输出连接在一起。这在数值上等同于实现包含1x1和3x3滤波器的一个层。
- 本文以Caffe CNN框架定义的格式发布了SqueezeNet配置文件。然而,除了Caffe,还出现了其他几个CNN框架,包括MXNet 、Chainer 、Keras和Torch 。每一种都有自己的表示CNN架构的原生格式。也就是说,大多数这些库使用相同的底层计算后端,如cuDNN和MKL-DNN。研究社区移植了SqueezeNet CNN架构,以便与许多其他CNN软件框架兼容。
EVALUATION OF SQUEEZENET
- 本文现在将注意力转向评估SqueezeNet。在第前文回顾的每篇CNN模型压缩论文中,目标都是压缩AlexNet 模型,该模型使用ImageNet 数据集对图像进行分类。因此,本文在评估SqueezeNet时使用AlexNet和相关的模型压缩结果作为比较的基础。
- 在下表中,本文在最近的模型压缩结果的上下文中回顾了SqueezeNet。基于SVDbased的方法能够将预训练的AlexNet模型压缩5倍,同时将top-1精度降低到56.0% 。网络修剪实现了模型大小的9倍缩减,同时在ImageNet上保持了57.2%的前1名和80.3%的前5名准确性的基线。深度压缩实现了模型大小的35倍缩减,同时仍保持基线精度水平。
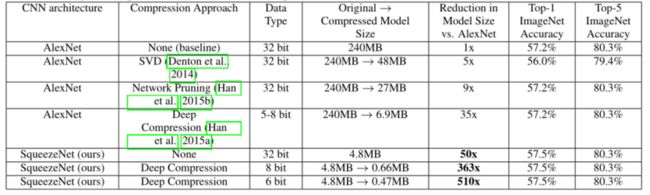
- Comparing SqueezeNet to model compression approaches 比较squeezenet和模型压缩方法。对于模型大小,本文指的是存储训练模型中所有参数所需的字节数。
- 现在,有了SqueezeNet,本文的模型尺寸比AlexNet缩小了50倍,同时达到或超过了AlexNet的前1名和前5名的精度。在上表中总结了所有上述结果。
- 本文似乎已经超越了模型压缩社区的最先进的结果:即使使用未压缩的32位值来表示模型,SqueezeNet的模型大小也比模型压缩社区的最佳结果小1.4倍,同时保持或超过了基线精度。
- 到目前为止,一个悬而未决的问题是:小模型适合压缩吗,或者小模型“需要”密集浮点值所提供的所有表示能力吗?为了找到答案,本文对SqueezeNet应用了深度压缩,使用了33%的稀疏度6和8位量化。这产生了一个0.66 MB的模型(比32位AlexNet小363倍),其精度与AlexNet相当。
- 此外,在SqueezeNet上应用具有6位量化和33%稀疏度的深度压缩,本文产生了具有同等精度的0.47MB模型(比32位AlexNet小510倍)。本文的小模型确实经得起压缩。
- 此外,这些结果表明,深度压缩不仅在具有许多参数的CNN架构(例如,AlexNet和VGG)上工作良好,而且还能够压缩已经紧凑的完全卷积SqueezeNet架构。深度压缩将SqueezeNet压缩10倍,同时保持基线精度。总之:通过将CNN架构创新(SqueezeNet)与最先进的压缩技术(深度压缩)相结合,本文实现了模型大小510倍的缩减,而与基线相比准确性没有降低。
- 最后,请注意,深度压缩使用码本作为其方案的一部分,用于将CNN参数量化为6位或8位精度。因此,在大多数商用处理器上,使用深度压缩中开发的方案,通过8位量化实现32/8 = 4倍的加速,或通过6位量化实现32/6 = 5.3倍的加速,都不是小事。
- 然而,Han等人开发了定制硬件——高效推理引擎(EIE)——可以更有效地计算码本量化CNN。此外,在本文发布SqueezeNet以来的几个月里,P. Gysel开发了一个名为Ristretto的策略,用于将SqueezeNet线性量化为8位。具体来说,Ristretto以8位进行计算,并以8位数据类型存储参数和激活。在SqueezeNet推理中使用Ristretto策略进行8位计算时,Gysel观察到当使用8位而不是32位数据类型时,准确性下降了不到1个百分点。
CNN MICROARCHITECTURE DESIGN SPACE EXPLORATION
- 到目前为止,本文已经提出了小模型的架构设计策略,遵循这些原则创建了SqueezeNet,并发现SqueezeNet比AlexNet小50倍,但精度相当。然而,SqueezeNet和其他模型存在于CNN架构的一个广阔的、很大程度上未被探索的设计空间中。本文将这种架构探索分为两个主要主题:微架构探索(每个模块层的维度和配置)和宏观架构探索(模块和其他层的高级端到端组织)。
- 在本节中,设计并执行实验,目的是针对本文提出的设计策略,提供关于微体系结构设计空间形状的直觉。请注意,本文的目标不是在每个实验中最大化准确性,而是理解CNN架构选择对模型大小和准确性的影响。
CNN MICROARCHITECTURE METAPARAMETERS
- 在SqueezeNet中,每个Fire模块都有本文定义的三维超参数: s 1 x 1 s_{1x1} s1x1、 e 1 x 1 e_{1x1} e1x1和 e 3 x 3 e_{3x3} e3x3。SqueezeNet有8个Fire模块,总共有24维超参数。为了对类似SqueezeNet的体系结构的设计空间进行广泛的扫描,本文定义了以下一组控制CNN中所有Fire模块尺寸的高级元参数。本文将 b a s e e base_e basee定义为CNN中第一个Fire模块中扩展过滤器的数量。
- 每触发一个freq模块,本文就增加一个扩展过滤器的数量。换句话说,对于Fire模块i,扩展过滤器的数量为 e i = b a s e e + ( i n c r e ∗ ⌊ i f r e q ⌋ ) e_i = base_e+(incr_e*⌊\frac{i}{freq}⌋) ei=basee+(incre∗⌊freqi⌋)。在一个Fire模块的扩展层,有的卷积核是1x1,有的是3x3。
- 本文将 e i = e i , 1 x 1 + e i , 3 x 3 ei = e_{i,1x1 }+ e_{i,3x3} ei=ei,1x1+ei,3x3与 p c t 3 x 3 pct_{3x3} pct3x3(在范围[0,1]内,在所有Fire模块上共享)定义为3x3的扩展过滤器的百分比。换句话说, e i , 3 x 3 = e i ∗ p c t 3 x 3 , e i , 1 x 1 = e i ∗ ( 1 − p c t 3 x 3 ) e_{i,3x 3 }= e_i*pct_{3x3},e_{i,1x1} = e_i*(1-pct_{3x 3}) ei,3x3=ei∗pct3x3,ei,1x1=ei∗(1−pct3x3)。
- 最后,本文使用称为squeeze ratio(SR)的元参数来定义Fire模块的挤压层中的过滤器数量(同样,在范围[0,1]内,由所有Fire模块共享): s i , 1 x 1 = S R ∗ e i s_{i,1x1} = SR*e_i si,1x1=SR∗ei(或等价地 s i , 1 x 1 = S R ∗ ( e i , 1 x 1 + e i , 3 x 3 ) s_{i,1x1} = SR*(e_{i,1x1} + e_{i,3x3}) si,1x1=SR∗(ei,1x1+ei,3x3))。SqueezeNet(表SqueezeNet architectural dimensions)是本文用前面提到的元参数集生成的一个示例架构。具体来说,SqueezeNet有以下元参数: b a s e e = 128 , i n c r e = 128 , p c t 3 x 3 = 0.5 , f r e q = 2 , S R = 0.125 base_e = 128,incr_e = 128,pct_{3x3 }= 0.5,freq = 2,SR = 0.125 basee=128,incre=128,pct3x3=0.5,freq=2,SR=0.125。
SQUEEZE RATIO
- 本文建议通过使用squeeze层来减少3x3滤波器看到的输入通道数量,从而减少参数数量。本文将squeeze ratio(SR)定义为squeeze层中过滤器数量与膨胀层中过滤器数量之间的比率。本文现在设计一个实验来研究squeeze ratio对模型大小和精度的影响。
- 在这些实验中,本文使用SqueezeNet作为起点。如同在SqueezeNet中一样,这些实验使用以下元参数: b a s e e = 128 , i n c r e = 128 , p c t 3 x 3 = 0.5 , f r e q = 2 base_e = 128,incr_e = 128,pct_{3x3 }= 0.5,freq = 2 basee=128,incre=128,pct3x3=0.5,freq=2。本文训练多个模型,其中每个模型具有在范围[0.125,1.0]内的不同挤压比(SR)。在下图(a)中,本文展示了这个实验的结果,其中图上的每个点都是从头开始训练的独立模型。SqueezeNet是该图中的SR=0.125点。从该图中,本文了解到,将SR增加到0.125以上可以进一步将ImageNet top-5的准确性从4.8MB型号的80.3%(即AlexNet级别)增加到19MB型号的86.0%。当SR = 0.75(19MB模型)时,精度稳定在86.0%,设置SR=1.0会进一步增加模型大小,但不会提高精度。

- Microarchitectural design space exploration.
TRADING OFF 1X1 AND 3X3 FILTERS
- 本文建议通过用1x1滤波器替换一些3x3滤波器来减少CNN中的参数数量。一个悬而未决的问题是,空间分辨率在CNN滤波器中有多重要?
- VGG架构在大多数图层的过滤器中具有3×3的空间分辨率;GoogLeNet 和网络中的网络(NiN)在某些层中具有1x1滤波器。在GoogLeNet和NiN的文章中,作者简单地提出了1x1和3x3过滤器的具体数量,而没有进一步的分析。在这里,本文试图阐明1x1和3x3过滤器的比例如何影响模型大小和准确性。
- 本文在这个实验中使用以下元参数: b a s e e = 128 , i n c r e = 128 , f r e q = 2 , S R = 0.500 base_e = 128,incr_e = 128,freq = 2,SR = 0.500 basee=128,incre=128,freq=2,SR=0.500,本文将pct3x3从1%变化到99%。换句话说,每个Fire模块的扩展层都有一个预定义数量的过滤器,在1x1和3x3之间划分,这里本文将这些过滤器的旋钮从“主要是1x1”旋转到“主要是3x3”。与前面的实验一样,这些模型有8个Fire模块,遵循与squeezenet结构图相同的层组织。本文在上图(b)中显示了这个实验的结果。注意,上图(a)和上图(b)中的13MB型号是相同的架构:SR = 0.500,pct3x3 = 50%。本文在上图(b)中看到,使用50%的3x3过滤器时,前5名的精确度稳定在85.6%,进一步增加3x3过滤器的百分比会导致更大的模型大小,但不会提高ImageNet的精确度。
CNN MACROARCHITECTURE DESIGN SPACE EXPLORATION
-
到目前为止,本文已经探索了微架构级别的设计空间,即CNN各个模块的内容。现在,本节在宏观架构层面上探讨与Fire模块之间的高层连接相关的设计决策。受ResNet 的启发,本文探索了三种不同的架构:
- Vanilla SqueezeNet(按照前面的章节)。
- 一些Fire模块之间的简单旁路连接SqueezeNet。
- 其余Fire模块之间带有复杂旁路连接的SqueezeNet。
-
本文的简单旁路架构在Fire模块3、5、7和9周围增加了旁路连接,要求这些模块学习输入和输出之间的残差函数。和在ResNet中一样,为了实现Fire3周围的旁路连接,本文将Fire4的输入设置为等于(Fire2的输出+Fire3的输出),其中+运算符是元素加法。这改变了应用于这些Fire模块的参数的正则化,并且根据ResNet,可以提高训练整个模型的最终精度和/或能力。
-
一个限制是,在简单的情况下,输入通道的数量和输出通道的数量必须相同;结果,只有一半的Fire模块可以具有简单的旁路连接,如【SqueezeNet架构的宏观架构视图】的中间图所示。当无法满足“相同数量的通道”要求时,将使用复杂的旁路连接,如【SqueezeNet架构的宏观架构视图】右侧所示。虽然简单旁路“只是一根线”,但本文将复杂旁路定义为包含一个1x1卷积层的旁路,滤波器数量等于所需的输出通道数量。请注意,复杂的旁路连接会向模型添加额外的参数,而简单的旁路连接则不会。
-
除了改变正则化之外,对本文来说,增加旁路连接将有助于缓解由squeeze层引入的表示瓶颈。在SqueezeNet中,squeeze ratio(SR)为0.125,这意味着每个挤压层的输出通道比相应的扩展层少8倍。由于这种严重的维度缩减,有限量的信息可以通过squeeze层。然而,通过给SqueezeNet增加旁路连接,本文为信息在挤压层之间流动开辟了途径。
-
本用三种宏架构训练了SqueezeNet,并在下表中比较了精度和模型大小。

- 使用不同宏架构配置的squeezenet精度和模型尺寸
-
在整个宏架构探索过程中,本文修复了微架构以匹配表SqueezeNet architectural dimensions中描述的SqueezeNet。复杂和简单的旁路连接都比普通的SqueezeNet架构有了更高的精度。有趣的是,简单旁路比复杂旁路能够实现更高的精度。在不增加模型尺寸的情况下,增加简单的旁路连接使前1名精度提高了2.9个百分点,前5名精度提高了2.2个百分点。
CONCLUSIONS
- 在这篇论文中,本文提出了一个更有规则准则的方法来探索卷积神经网络的设计空间的步骤。为了实现这个目标,本文提出了SqueezeNet,这是一种CNN架构,其参数比AlexNet少50倍,并在ImageNet上保持AlexNet级别的准确性。
- 本文还把SqueezeNet压缩到了0.5MB以下,比没有压缩的AlexNet小了510倍。自从本文在2016年将这篇论文作为技术报告发布以来,韩松老师和他的团队对SqueezeNet和模型压缩进行了进一步的实验。使用一种称为密集-稀疏-密集(DSD)的新方法,Han等人在训练期间使用模型压缩作为正则化器来进一步提高准确性,产生一组压缩的SqueezeNet参数,在ImageNet-1k上比本文在表Comparing SqueezeNet to model compression approaches中的结果精确1.2个百分点,还产生一组未压缩的SqueezeNet参数,比本文在表Comparing SqueezeNet to model compression approaches中的结果精确4.3个百分点。
- 在本文开头提到过,小型模型更适合在FPGAs上实现片内应用。自从我们发布了SqueezeNet模型以来,Gschwend已经开发了SqueezeNet的变体,并在FPGA上实现了它。正如本文预期的那样,Gschwend能够将类似SqueezeNet的模型的参数完全存储在FPGA中,并且不需要片外存储器访问来加载模型参数。
- 在本文的上下文中,本文将ImageNet作为目标数据集。然而,将经过ImageNet训练的CNN表示应用于各种应用(如细粒度的对象识别)已成为惯例,图像中的logo识别,生成关于图像的句子。经过图像网络训练的CNN也已经应用于许多与自动驾驶相关的应用,包括图像中的行人和车辆检测和视频,以及分割道路形状。本文认为SqueezeNet将是各种应用的一个很好的候选CNN架构,特别是那些小模型尺寸很重要的应用。
- SqueezeNet是本文在广泛探索CNN架构的设计空间时发现的几个新CNN之一。希望SqueezeNet将激励读者考虑和探索CNN架构设计空间的广泛可能性,并以更系统的方式进行探索。