opencv案例实战之工业印刷品数字识别
一、环境准备
- Python语言包
- OpenCV-python开发包
- OpenCV DNN模块
- OpenCV ML模块
- pycharm2019
项目地址:https://github.com/zxinyang38/opencv-
二、结果预览
从给定的印刷品图像进行数字识别。

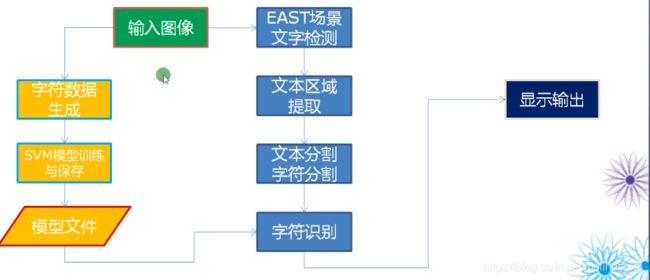
三、实验步骤
1、EAST TEXT对象检测模型(使用EAST网络模型实现文字区域检测)
- EAST网络架构
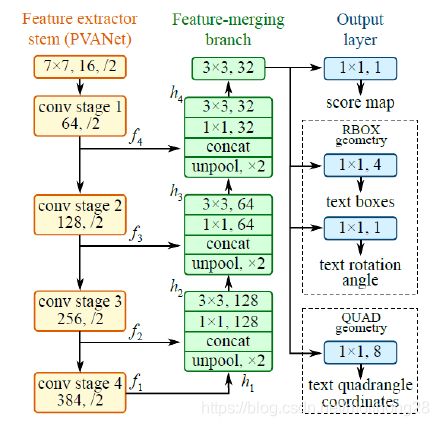
- 加载获取网络各层信息
east_text权重文件放在本人github地址:https://github.com/zxinyang38/opencv-
import cv2 as cv
import numpy as np
net = cv.dnn.readNet('C:/Program Files (x86)/pycharm/pycharm/PycharmProjects/ML/ocr_demo/frozen_east_text_detection.pb')
names = net.getLayerNames()
for name in names:
print(name)
以上代码可以输出每一层的名字:其中feature_fusion/Conv_7/Sigmoid对应的是EAST网络中score map部分
feature_fusion/concat_3对应的是EAST网络架构中最右边的RBOX geometry部分
- 使用网络
def detect(self,image):
(H,W) = image.shape[:2]
rH = H / float(320)
rW = W / float(320)
blob = cv.dnn.blobFromImage(image,1.0,(320,320),(123.68, 116.78, 103.94),swapRB=True,crop=False)
self.net.setInput(blob)
(scores, geometry) = self.net.forward(self.layerNames)
print(scores)
详见:text_area_detect.py函数
2、非最大抑制(NMS)
检测出来的图像可能时下图这种:

故而引入NMSBoxes API(非最大信号抑制去掉差的区域):
import cv2 as cv
import numpy as np
class TextAreaDetector:
def __init__(self,model_path):
self.net = cv.dnn.readNet(model_path)
names = self.net.getLayerNames()
for name in names:
print(name)
self.threshold = 0.5
self.layerNames = ["feature_fusion/Conv_7/Sigmoid","feature_fusion/concat_3"]
def detect(self,image):
(H,W) = image.shape[:2]
rH = H / float(320)
rW = W / float(320)
blob = cv.dnn.blobFromImage(image,1.0,(320,320),(123.68, 116.78, 103.94),swapRB=True,crop=False)
self.net.setInput(blob)
(scores, geometry) = self.net.forward(self.layerNames)
print(scores)
(numRows, numCols) = scores.shape[2:4]
rects = []
confidences = []
# start to decode the output
for y in range(0, numRows):
scoresData = scores[0, 0, y]
xData0 = geometry[0, 0, y]
xData1 = geometry[0, 1, y]
xData2 = geometry[0, 2, y]
xData3 = geometry[0, 3, y]
anglesData = geometry[0, 4, y]
# loop over the number of columns
for x in range(0, numCols):
# if our score does not have sufficient probability, ignore it
if scoresData[x] < self.threshold:
continue
# compute the offset factor as our resulting feature maps will
# be 4x smaller than the input image
(offsetX, offsetY) = (x * 4.0, y * 4.0)
# extract the rotation angle for the prediction and then
# compute the sin and cosine
angle = anglesData[x]
cos = np.cos(angle)
sin = np.sin(angle)
# use the geometry volume to derive the width and height of
# the bounding box
h = xData0[x] + xData2[x]
w = xData1[x] + xData3[x]
# compute both the starting and ending (x, y)-coordinates for
# the text prediction bounding box
endX = int(offsetX + (cos * xData1[x]) + (sin * xData2[x]))
endY = int(offsetY - (sin * xData1[x]) + (cos * xData2[x]))
startX = int(endX - w)
startY = int(endY - h)
# add the bounding box coordinates and probability score to
# our respective lists
rects.append([startX, startY, endX, endY])
confidences.append(float(scoresData[x]))
# 非最大抑制
boxes = cv.dnn.NMSBoxes(rects, confidences, self.threshold, 0.8)
result = np.zeros(image.shape[:2], dtype=np.uint8)
#result = np.copy(image)
for i in boxes:
i = i[0]
box = rects[i]
startX = box[0]
startY = box[1]
endX = box[2]
endY = box[3]
startX = int(startX * rW)
startY = int(startY * rH)
endX = int(endX * rW)
endY = int(endY * rH)
# draw the bounding box on the image
cv.rectangle(result, (startX, startY), (endX, endY), (255), 2)
return result
if __name__ == "__main__":
text_detector = TextAreaDetector('C:/Program Files (x86)/pycharm/pycharm/PycharmProjects/ML/ocr_demo/frozen_east_text_detection.pb')
frame = cv.imread('C:/Program Files (x86)/pycharm/pycharm/PycharmProjects/ML/ocr_demo/1.jpg')
cv.imshow("input",frame)
result = text_detector.detect(frame)
cv.imshow("result",result)
cv.waitKey(0)
cv.destroyAllWindows()
输入图像:

最后的输出结果为下图
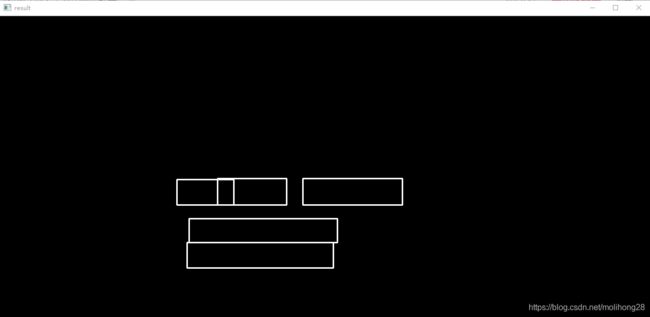
其中对矩形框进行非最大抑制代码为:boxes = cv.dnn.NMSBoxes(rects, confidences, self.threshold, 0.8)
- rects:矩形框
- confidences:各个矩形框得分
- self.threshold:confidence小于阈值抑制,大于confidence被保留
- 0.8:为交并比的值,值越大表示越相似,对大于0.8交并比的合并
详见:text_area_detect.py函数
3、形态学合并
#膨胀
se = cv.getStructuringElement(cv.MORPH_RECT,(45,1))
result = cv.morphologyEx(result, cv.MORPH_DILATE,se)

#发现轮廓
contours, hierachy = cv.findContours(result, cv.RETR_EXTERNAL, cv.CHAIN_APPROX_SIMPLE)
for c in range(len(contours)):
box = cv.boundingRect(contours[c])
if box[2] < 10 or box[3] < 10:
continue
cv.rectangle(frame,(box[0],box[1]),(box[0]+box[2],box[1]+box[3]),(0,0,255),2,8)

详见:text_area_detect.py函数
4、排序与块分割
#roi块区域的排序与分割
nums = len(text_boxes)
for i in range(nums):
for j in range(i + 1, nums, 1):
x1, y1, w1, h1 = text_boxes[i]
x2, y2, w2, h2 = text_boxes[j]
if y1 > y2:
temp = text_boxes[i]
text_boxes[i] = text_boxes[j]
text_boxes[j] = temp
for x,y,w,h in text_boxes:
text_roi = frame[y:y+h+5, x:x+w, :]
cv.imshow("text_roi", text_roi)
cv.waitKey(0)


详见:text_area_detect.py函数
5、行文本分割
对text_roi图像做二值化,对二值图像做Y-Projection图像投影

二值化之后,Y轴方向投影预览:
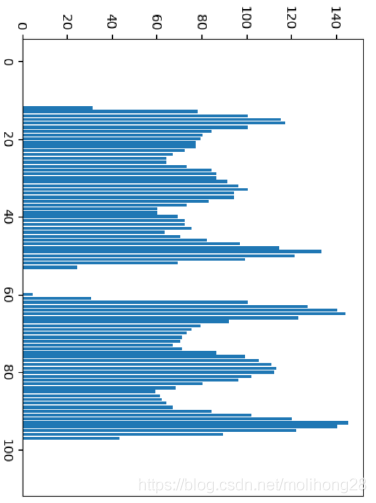
可以从投影的图像看出,中间有一部分断开,断开的地方可以用于行文本分割。
代码:
gray = cv.cvtColor(text_roi, cv.COLOR_BGR2GRAY)
ret, binary = cv.threshold(gray, 0, 255, cv.THRESH_BINARY_INV | cv.THRESH_OTSU)
print("threshold : %.2f" % ret)
cv.imshow("text_roi", gray)
text_lines = split_lines(binary)
if len(text_lines) == 1:
cv.imshow("line", binary)
cv.waitKey(0)
else:
for line in text_lines:
cv.imshow("line", line)
cv.waitKey(0)
详见:text_area_detect.py函数
其中text_lines = split_lines(binary)中的split_lines定义如下:
def split_lines(image):
print("start to analysis text layout...");
# Y-Projection
h, w = image.shape
hist = np.zeros(h, dtype=np.int32)
for i in range(h):
for c in range(w):
pv = image[i, c]
if pv == 255:
hist[i] += 1
# x = np.arange(h)
# plt.bar(x, height=hist)
# plt.show()
# find lines
hist[np.where(hist>5)] = 255
hist[np.where(hist<=5)] = 0
text_lines = []
found = False
count = 0
start = -1
for i in range(h):
if hist[i] > 0 and found is False:
found = True
start = i
count += 1
if hist[i] > 0 and found is True:
count += 1
if hist[i] == 0 and found is True:
found = False
text_lines.append(image[start-2:start+count+2, 0:w])
start = -1
count = 0
if found is True:
text_lines.append(image[start - 2:start + count + 2, 0:w])
print(len(text_lines))
return text_lines
详见:ocrutils.py函数
最后的结果就是text_roi区域被分割为两个line图像
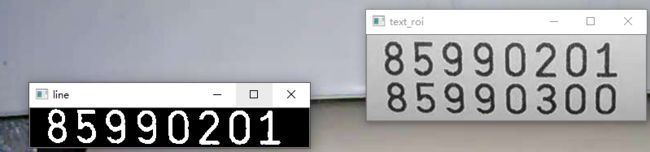
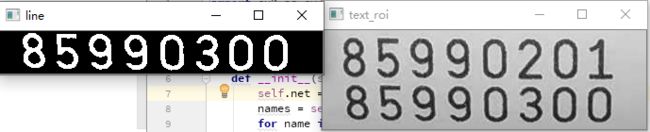
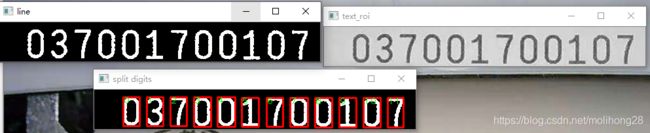
6、字符分割与提取
预期效果:

字符ROI与排序
- 获取字符ROI(findcontours轮廓发现)
def get_data_set(image):
print("generate dataset...")
contours, hireachy = cv.findContours(image, cv.RETR_EXTERNAL, cv.CHAIN_APPROX_SIMPLE)
# get all digits
rois = []
for c in range(len(contours)):
box = cv.boundingRect(contours[c])
if box[3] < 10:
continue
rois.append(box)
详见:ocrutils.py函数
- 排序ROI(对x进行排序)
# sort(box)
num = len(rois)
for i in range(num):
for j in range(i+1, num, 1):
x1, y1, w1, h1 = rois[i]
x2, y2, w2, h2 = rois[j]
if x2 < x1:
temp = rois[j]
rois[j] = rois[i]
rois[i] = temp
bgr = cv.cvtColor(image, cv.COLOR_GRAY2BGR)
index = 0
digit_data = np.zeros((num, 28*48), dtype=np.float32)
for x, y, w, h in rois:
cv.rectangle(bgr, (x, y), (x+w, y+h), (0, 0, 255), 2, 8)
cv.putText(bgr, str(index), (x, y+10), cv.FONT_HERSHEY_PLAIN, 1.0, (0, 255, 0), 1)
digit = image[y:y+h,x:x+w]
img = cv.resize(digit, (28, 48))
row = np.reshape(img, (-1, 28 * 48))
digit_data[index] = row
index += 1
cv.imshow("split digits", bgr)
详见:ocrutils.py函数
主函数代码:
gray = cv.cvtColor(text_roi, cv.COLOR_BGR2GRAY)
ret, binary = cv.threshold(gray, 0, 255, cv.THRESH_BINARY_INV | cv.THRESH_OTSU)
print("threshold : %.2f" % ret)
cv.imshow("text_roi", gray)
text_lines = split_lines(binary)
if len(text_lines) == 1:
cv.imshow("line", binary)
data, boxes = get_data_set(binary)
cv.waitKey(0)
else:
for line in text_lines:
cv.imshow("line", line)
data, boxes = get_data_set(binary)
cv.waitKey(0)
运行结果实现了对每个自取区域的分割与排序。
7、字符数据集生成与SVM训练数据集
下边是生成数据集然后对每个字符进行训练分类(基于ml模块的svm)
数据集生成:
- 每个字符为一行,大小为48(h)x28(w)
- 每一行对于label标签中一个数字

def load_data():
images = []
labels = []
files = os.listdir("C:/Program Files (x86)/pycharm/pycharm/PycharmProjects/ML/ocr_demo/digits")
count = len(files)
sample_data = np.zeros((count, 28*48), dtype=np.float32)
index = 0
for file_name in files:
file_path = os.path.join("C:/Program Files (x86)/pycharm/pycharm/PycharmProjects/ML/ocr_demo/digits", file_name)
if os.path.isfile(file_path) is True:
images.append(file_path)
labels.append(file_name[:1])
img = cv.imread(file_path, cv.IMREAD_GRAYSCALE)
img = cv.resize(img, (28, 48))
row = np.reshape(img, (-1, 28*48))
sample_data[index] = row
index += 1
return sample_data, np.asarray(labels, np.int32)
详见train.py函数
下边是使用SVM训练:
- OpenCV ML模块介绍
- SVM训练与保存模型
- SVM使用模型预测
# load data stage
train_data, train_labels = load_data()
# train stage
svm = cv.ml.SVM_create()
svm.setKernel(cv.ml.SVM_LINEAR)
svm.setType(cv.ml.SVM_C_SVC)
svm.setC(2.67)
svm.setGamma(5.383)
svm.train(train_data, cv.ml.ROW_SAMPLE, train_labels)
svm.save("svm_data.yml")
svm = cv.ml.SVM_load("svm_data.yml")
result = svm.predict(train_data)[1]
print(result)
详见train.py函数
8、使用模型预测与显示预测结果
对给定image数据部分的提取
index = 0
digit_data = np.zeros((num, 28*48), dtype=np.float32)
for x, y, w, h in rois:
cv.rectangle(bgr, (x, y), (x+w, y+h), (0, 0, 255), 2, 8)
cv.putText(bgr, str(index), (x, y+10), cv.FONT_HERSHEY_PLAIN, 1.0, (0, 255, 0), 1)
digit = image[y:y+h,x:x+w]
img = cv.resize(digit, (28, 48))
row = np.reshape(img, (-1, 28 * 48))
digit_data[index] = row
index += 1
cv.imshow("split digits", bgr)
return digit_data, rois
详见:ocrutils.py函数
字符识别:
- 使用SVM预测
显示结果:
- 多行预测与显示
完整的main函数:
if __name__ == "__main__":
text_detector = TextAreaDetector('C:/Program Files (x86)/pycharm/pycharm/PycharmProjects/ML/ocr_demo/frozen_east_text_detection.pb')
frame = cv.imread('C:/Program Files (x86)/pycharm/pycharm/PycharmProjects/ML/ocr_demo/1.jpg')
cv.imshow("input",frame)
result = text_detector.detect(frame)
se = cv.getStructuringElement(cv.MORPH_RECT,(45,1))
result = cv.morphologyEx(result, cv.MORPH_DILATE,se)
text_boxes = []
contours, hierachy = cv.findContours(result, cv.RETR_EXTERNAL, cv.CHAIN_APPROX_SIMPLE)
for c in range(len(contours)):
box = cv.boundingRect(contours[c])
if box[2] < 10 or box[3] < 10:
continue
#cv.rectangle(frame,(box[0],box[1]),(box[0]+box[2],box[1]+box[3]),(0,0,255),2,8)
text_boxes.append(box)
nums = len(text_boxes)
for i in range(nums):
for j in range(i+1,nums,1):
x1, y1, w1, h1 = text_boxes[i]
x2, y2, w2, h2 = text_boxes[j]
if y1 > y2:
temp = text_boxes[i]
text_boxes[i] = text_boxes[j]
text_boxes[j] = temp
dr = DigitNumberRecognizer()
for x,y,w,h in text_boxes:
text_roi = frame[y:y+h+5, x:x+w, :]
gray = cv.cvtColor(text_roi, cv.COLOR_BGR2GRAY)
ret, binary = cv.threshold(gray,0,255,cv.THRESH_BINARY_INV | cv.THRESH_OTSU)
print("threshold : %.2f"%ret)
cv.imshow("text_roi", gray)
text_lines = split_lines(binary)
if len(text_lines) == 1:
cv.imshow("line", binary)
data, boxes = get_data_set(binary)
ocr_text = dr.predict(data)
cv.putText(frame, ocr_text, (x+w,y), cv.FONT_HERSHEY_SIMPLEX ,1.0, (0,0,255), 2)
cv.imshow("result", frame)
cv.waitKey(0)
else:
gap = 0
for line in text_lines:
cv.imshow("line", line)
data, boxes = get_data_set(line)
ocr_text = dr.predict(data)
cv.putText(frame, ocr_text, (x + w, y + gap), cv.FONT_HERSHEY_SIMPLEX, 1.0, (0, 0, 255), 2)
cv.imshow("result", frame)
cv.waitKey(0)
gap += 50
# cv.imshow("result",frame)
cv.waitKey(0)
cv.destroyAllWindows()
详见:text_area_detect.py函数
最后输出结果:

四、总结
附上完整代码:https://github.com/zxinyang38/opencv-