卷积核扩大到51x51,新型CNN架构SLaK反击Transformer

©作者 | 刘世伟
来源 | 机器之心
首先,先让我 brainstorm 一下。当你看到 neural network scaling 这个词的时候你能想到什么?先不要看下文,把你想到的东西记下来。说不定这个简单的 brainstorm 能让你找到绝妙的 idea。
我想大多数人想到的应该是模型大小(宽度 + 深度),数据大小,或者图片像素等等。有没有哪位小科学家曾经想过去 scale convolutional kernels?scale 卷积核同样能增大模型的参数,但能带来像宽度和深度一样的增益吗?我这篇文章从这个角度出发深入探究了超大卷积核对模型表现的影响。我发现现有的大卷积核训练方法的瓶颈:现有的方法都无法无损的将卷积核 scale 到 31x31 以上,更别说用更大的卷积来进一步获得收益。
我这篇文章的贡献可以总结为以下几点:
1. 现有的方法可以将卷积核增大到 31x31。但在更大的卷积上,例如 51x51 和 61x61,开始出现明显掉点的现象;
2. 经典的 CNN 网络,如 ResNet 和 ConvNeXt,stem cell 都采用了 4× 降采样。所以对典型的 224×224 ImageNet 来说,51×51 的极端核已经大致等于全局卷积。和全局注意力机制一样,我推测全局卷积也存在着捕捉局部低级特征的能力不足的问题。
3. 基于此观察,我提出了一套训练极端卷积核的 recipe,能够丝滑的将卷积核增大到 61x61,并进一步提高模型的表现。我的方法论主要是基于人类视觉系统中普遍存在的稀疏性提出来的。在微观层面上,我将 1 个方形大卷积核分解为 2 个具有动态稀疏结构的,平行的长方形卷积核,用来提高大卷积的可扩展性;在宏观层面上,我构建了一个纯粹的稀疏网络,能够在提升网络容量的情况下保持着和稠密网络一样的参数和 FLOPs。
4. 根据这个 recipe,我构造了一个新型网络结构 Sparse Large Kernel Network,简称 SLaK。SLaK 搭载着有史以来最大的 51x51 卷积核,能够在相似的参数量和 FLOPs 的条件下,获得比最新先进的 ConvNeXt,Swin Transformer 和 RepLKNet 更好的性能。
5. 最后,作者认为本文最重要的贡献是 sparsity,通常作为模型压缩的“老伙计”,can be a promising tool to boost neural network scaling。

论文标题:
More ConvNets in the 2020s: Scaling up Kernels Beyond 51 × 51 using Sparsity
论文链接:
https://arxiv.org/pdf/2207.03620.pdf
代码链接:
https://github.com/VITA-Group/SLaK

引言
随着 vison transformer 在各个领域的大放异彩,CNN 和 Vision Transformer 的竞争也愈演愈烈。在愈发强大的各类 attention 变种的推进下,ViT 取代 CNN 这个视觉老大哥的野心已经路人皆知。而 CNN 在全局和局部注意力的启发下也带着大卷积乘风破浪回来。前浪有 ConvNeXts 配备着 7x7 卷积核和 swin transformer 精巧的模型设计,成功的超越了后者的表现。
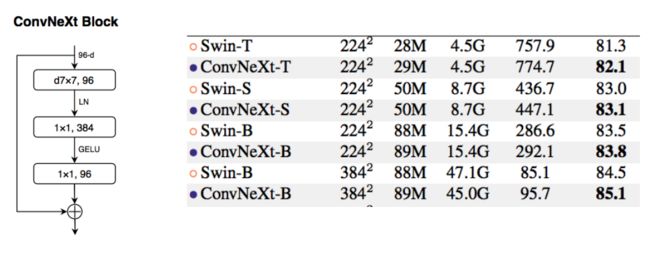
后浪中 RepLKNet 用结构再参数化成功的克服了大卷积在训练上的困难,一度将卷积增大到了 31x31,并达到了和 Swin Transformer 相当的表现。在下游任务上更是超过了后者。但与 Swin Transformer 等高级 ViT 的扩展趋势相比,随着卷积核的持续扩大,大卷积核有着明显的疲软趋势。
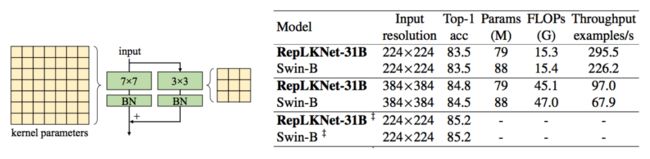

超越31x31超大卷积核的训练recipe
本文主要想探究的问题是:是否可以通过采用极致大卷积核(超过 31x31)来进一步提高 CNNs 的表现?为了回答这个问题,我在最近大火的 ConvNeXt 上对大卷积进行了系统的研究。我采用了和 ConvNeXt 一模一样的训练设定和超参并将卷积核放大到 31x31,51x51 和 61x61。受限于计算资源,我这里将模型训练到 120 个 epoch,仅仅用来观察卷积增大的趋势,得到了如下 3 个主要结论。
结论 1:现有的技术无法无损的将卷积核扩展到 31x31 以上
现有的大卷积核技术主要有两个,一是直接暴力 scale up 卷积核的 ConvNeXt,二是增加一个额外的小卷积层来辅助大卷积的训练,训练完成之后再用结构化再参数将小卷积核融入大卷积核里,即 RepLKNet。我分别测试了这两种方法在极致大卷积上的表现,如下表所示:
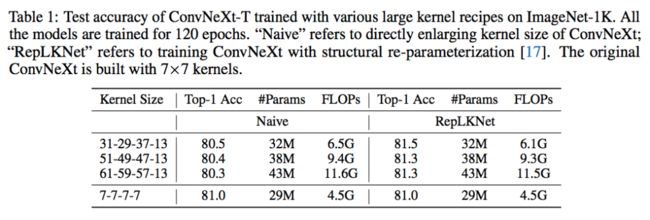
原始 ConvNeXt 采用的是 7x7 卷积核,ImageNet 上能达到 81.0% 的 top1 精度。但是当卷积逐渐增大的时候,ConvNeXt 出现了明显的掉点。相比之下,RepLKNet 成功的把卷积核增大到 31x31 并带来了超过 0.5 个点的可观提升。但是当卷积核增大到 51x51 甚至是 61x61 的时候,RepLKNet 也逐渐乏力。尤其是在 61x61 上,RepLKNet 的 FLOPs 增加了两倍,精度却反而降低了 0.2%。
如果仔细分析 ConvNeXt 模型的特点,51x51 和 61x61 卷积核带来的精度下降是可以理解的。如下图所示,现阶段最先进的模型的 stem cell 都不约而同的采用了 stride=4 的结构将输入图片的分辨率缩减到了原来的 1/4。那么对经典的 224x224 iamgenet 来说,通过 stem cell 之后,feature 的大小就只有 56x56 了。所有 51x51 和 61x61 规模的卷积核就已经是全局水平的卷积核。一种合某些理想的特性,比如有效的局部特性。同样的现象我在 ViTs 的类似机制中也观察到过,即局部注意力通常优于全局注意力。在此基础上,我想到了通过引入局部性来解决这个问题的机会。

结论 2:用两个平行的,长方形卷积来代替方形大卷积可以丝滑的将卷积核扩展到 61x61
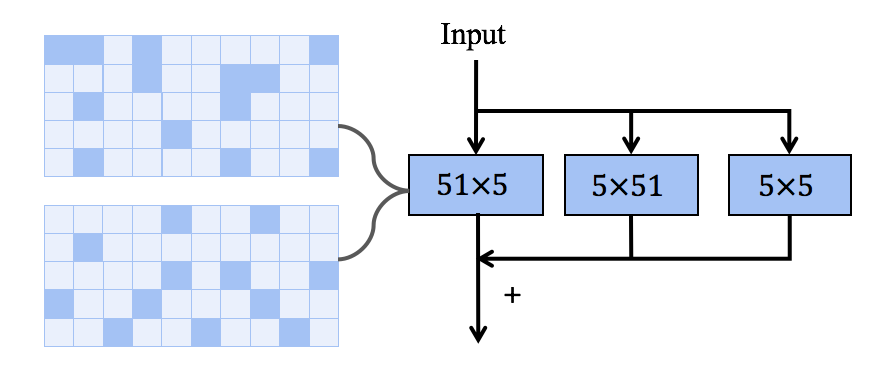
这里我采用的方法是将一个常用的 MxM 方形卷积核分解为两个平行的 MxN+NxM 长方形卷积核。如下图最右边所示。这里经验性的设置 N=5。
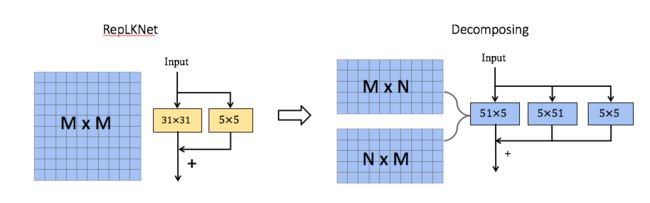
这种分解不仅继承了大卷积捕获远程依赖关系的能力,而且可以利用短边来提取局部上下文特征。我选用了两个 parallel 卷积核相加而不是以往的两个 sequential 卷积核相叠是因为先进行 MxN 卷积再进行 NxM 卷积可能会因为 N 过小而丢失一部分长距离的信息(有待于去验证)。果然与预想的一样,这样分解可以让我逆转大卷积带来精度下降的趋势。由于该分解减少了 FLOPs,相比不分解(即 RepLKNet)在 31x31 卷积上会牺牲掉少量的精度 (0.2%)。但是,随着卷积大小增加到全局卷积,它可以惊人地将 Kernel-size 扩展到 61x61 并带来更好的性能指标。

更重要的是,随着卷积核的增大,现有的大卷积训练技术的内存和计算开销会呈现二次方的增长。这种分解方式保持了线性增长的趋势并且可以极大的减少大卷积核带来的开销。如下图所示。在中等卷积 31x31 上,参数量和计算量基本豆差不多。但是继续增大卷积核的时候,RepLKNet 的计算量二次方的增长,而我的方法能基本保持不变。
不要小看这一点,因为现在已经有很多工作指明了一个明显的趋势:高分辨率训练(Swin Transfermor V2 使用了高达 1536x1536 的像素)能够带来明显的增益。这种极大分辨率上,51x51 分辨率明显已经不足以去获得足够大的感受野。我很可能需要 100 + 的卷积核去获得足够大的感受野。

结论 3:拥有动态稀疏性的卷积核极大的提高了模型的容量同时又不增加模型大小
最近提出的 ConvNeXt 重新访问了 ResNeXt 中 “use more groups, expand width” 的准则,使用增加宽度的 depth-wise 卷积来增加 model capacity。在本文中,我用 dynamic sparsity 进一步扩展的这一原则,即“use sparse groups, expand more”。关于 dynamic sparsity 的介绍,请移步看我之前的分享:
https://zhuanlan.zhihu.com/p/376304225
具体来说,我首先用稀疏卷积代替密集卷积,其中每一层的稀疏度是基于 SNIP 的稀疏比率提前决定的。构建完成后,我采用了动态稀疏度方法来训练模型。具体来说就是在模型训练一段时间后我会采用参数剪枝的方法去 prune 掉一部分相对不重要的参数,紧接着去随机的涨同样数量的参数来保证总体训练参数的固定。
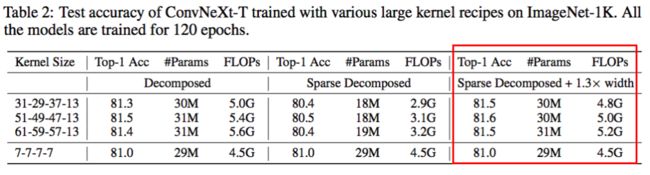
这样做可以动态地适应稀疏权值,从而获得更好的局部特征。由于在整个训练过程中模型都是稀疏的,相应的参数计数和训练 / 推理 FLOPs 只与模型的稀疏度成比例。为了评估,这里以 40% 的稀疏度稀疏化分解后的 kernel,并将其性能报告为 “稀疏分解” 组。可以在表 2 的中间一列中观察到,动态稀疏性显著降低了模型的 FLOPs(超过 2.0G),并导致了暂时的性能下降。

接下来,我展示了动态稀疏性的 high efficiency 可以有效地转化成 high scalability。例如,使用相同的稀疏性(40%),我可以将模型宽度扩展 1.3 倍,但是总体的模型参数和 FLOPs 却仍然和稠密网络一样,并显著涨点。在极端的 51×51 卷积下,性能可以从 80.5% 直接提高到 81.6%。值得注意的是,配备了 61×61 的内核之后,我的模型可以超越 RepLKNet 的精度,同时还节省了 55% 的 FLOPs。

Sparse Large Kernel Network - SLaK
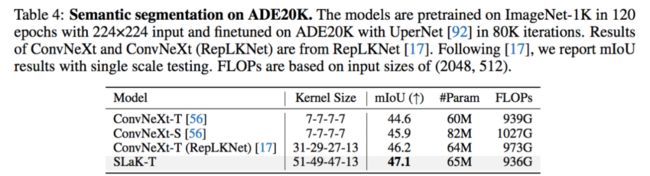
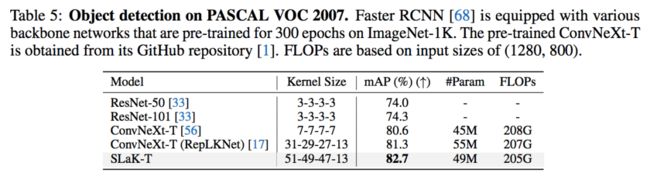
我利用上面发现的 recipe 在 ConvNeXt 上直接加载了 51x51 的卷积核,得到了 SLaK-T/S/B 模型。在不改变任何 ConvNeXt 原有的训练设置和超参的情况下,SLaK 在 ImageNet-1K 分类数据集,ADE20K 分割数据集、PASCAL VOC 2007 检测数据集,都超过了 Swin Transformer,ConvNeXt,和 RepLKNet 的表现。实验结果突出了极致卷积核在下游视觉任务中的关键作用。


感受野分析
前面我猜测新方法既能够保证对远距离相关性的获取,又能够捕捉到近距离重要的特征。接下来通过对感受野的分析来证明这种想法。我计算了输入图片的像素对不同模型决策的贡献度,并把贡献度加加回到 1024x1024 的图片上。我可以发现原始的 ConvNeXt 用 7X7 卷积只用了中间很小一部分的像素来做决策;RepLKNet 用 31x31 的卷积把感受野扩大了许多;而 SLaK 进一步用 51x51 的卷积核几乎达到了全局感受野。值得注意的在大的感受野之上,能明显的看到一个小的正方形堆叠着,证明了我能捕捉小范围的低级特征的猜想。

更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
