目标检测(Object Detection)学习笔记(二)Anchor-Based经典检测模型(Faster R-CNN、YOLO、SSD)
本文是我的目标检测笔记的第二部分:Anchor-Based经典检测模型分析,包括对以下经典的目标检测模型的个人总结和理解:
- Faster R-CNN
- YOLO 系列
- SSD
总述
下图显示了不同算法的基本框架图,对于Faster R-CNN,其先通过CNN得到候选框,然后再进行分类与回归,而Yolo与SSD可以一步到位完成检测。
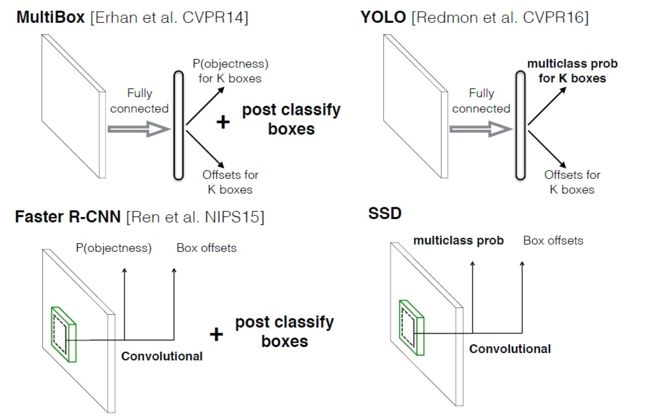
Faster R-CNN
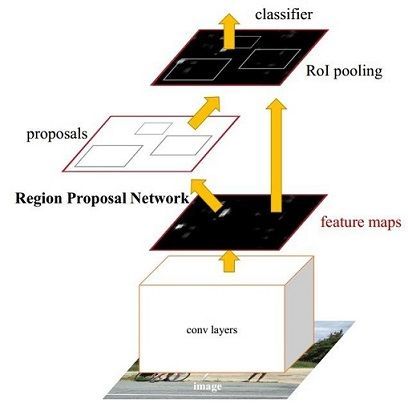
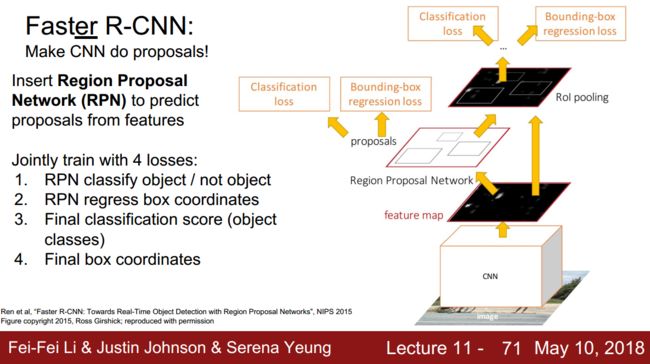
Faster R-CNN是two-stage检测框架的代表作,在各大竞赛的排行榜上,以它为基础的变体都占据着统治地位。Faster R-CNN的网络结构图如下图:
按照流程来说,Faster R-CNN的整体架构可以看下图(以VGG为例):
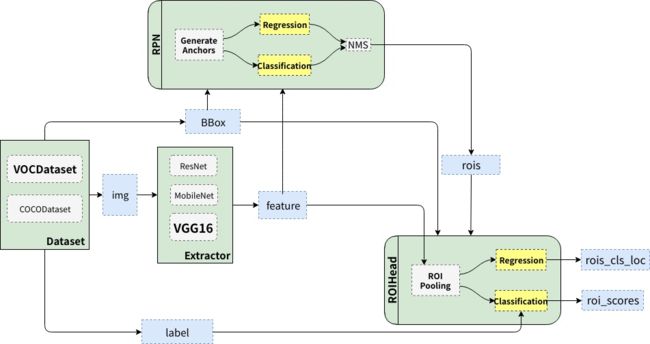
Faster R-CNN的检测流程是:首先使用深度卷积网络作为Backbone,从原始图像中抽取一张特征图;随后根据RPN输出的候选区域截取主干网络输出的特征图;之后通过RoI pooling得到最终的Head,并进行bounding box regression&classification;最后一个后处理过程NMS则搜索局部极大值、抑制非极大值元素。
它的几个突出贡献点如下:
- 提出了RPN网络,用来生成region proposal;
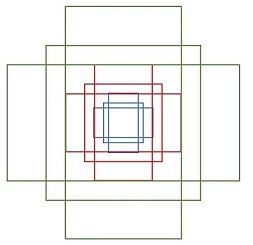
- 在RPN中引入了anchor,通过对anchor进行二分类(background/foreground)初步筛选Proposal。Anchor即大小和尺寸固定的候选框。论文中用到的anchor有三种尺寸和三种比例,如下图所示,三种尺寸分别是小(蓝128)中(红256)大(绿512),三个比例分别是1:1,1:2,2:1。3×3的组合总共有9种anchor。
- RPN网络和后续分类/回归网络共享卷积层特征,即将region proposal和 整合到一个网络中,大大提高了生成候选区域的速度(2s -> 0.01s);
- 使用ROI pooling将不同的proposal转化到同一尺寸,从而实现卷积层特征共享。
- 采用 4-Step Alternating Training 和multi-task loss进行训练。
论文和代码的细节不在这里多费笔墨,可以参考一文读懂Faster RCNN -白裳和从编程实现角度学习Faster R-CNN(附极简实现)-陈云,他们的解析对我的理解帮助很大。
YOLO系列
YOLO-v1
YOLO全称You Only Look Once: Unified, Real-Time Object Detection,它是一种one-stage、end to end的检测方法。
简单来说,YOLO将整个检测问题整合为一个回归问题,使得网络结构简单,检测速度大大加快;由于网络没有分支,所以训练也只需要一次即可完成。这种“把检测转化为回归问题”的思路非常有效,之后的很多检测算法(包括SSD)都借鉴了此思路。
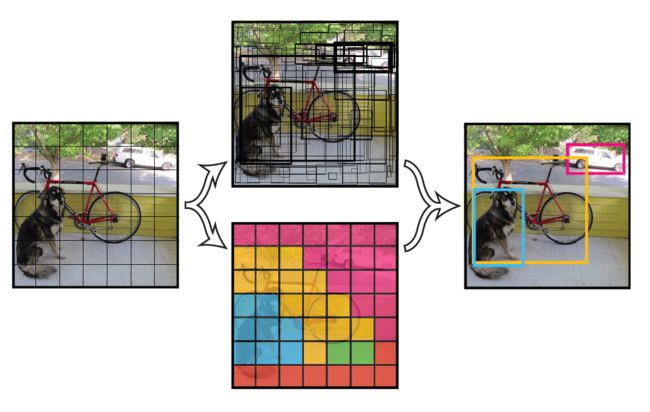
如上图所示,YOLO的检测流程简单概述如下:
- 将原图划分为S*S的网格。如果一个目标的中心落入某个格子,这个格子就负责检测该目标;
- 每个网格要预测B个bounding boxes,以及C个类别概率Pr(class|object)Pr(class|object);
- 每个bounding box除了要回归自身的位置之外,还要附带预测一个confidence值。这个confidence代表了所预测的box中含有目标的置信度和这个bounding box预测的类别准确率两重信息;
- 由于输入图像被分为SS网格,每个网格包括5个预测量:(x,y,w,h,confidence)(x,y,w,h,confidence)和一个C类,所以网络输出是$SS(5B+C)$大小;
- 在检测目标的时候,每个网格预测的类别条件概率和bounding box预测的confidence信息相乘,就得到每个bounding box的class-specific confidence score。
- 使用NMS过滤得到最终的检测框体。
YOLO有如下特点:
- 快。YOLO将物体检测作为回归问题进行求解,整个检测网络pipeline简单,可以端到端一次完成训练。
- 背景误检率(FP)低。YOLO在训练和推理过程中能“看到”整张图像的整体信息,而基于region proposal的物体检测方法在检测过程中,只“看到”候选框内的局部图像信息。因此,若当图像背景(非物体)中的部分数据被包含在候选框中送入检测网络进行检测时,容易被误检测成物体。
- 识别物体位置精准性(localization)差。
- 召回率(recall)低,尤其是对小目标。
YOLO-v2,v3
针对YOLO-v1中存在的问题,作者在v2中进行了改进,并在v3中进行了更多尝试。
YOLO-v2中的改进有以下几点:
- Batch Normalization
- High Resolution Classifier
- Convolutional With Anchor Boxes
- Dimension Clusters
- New Network: Darknet-19
- Fine-Grained Features
- Multi-Scale Training
此外,作者还同时提出了YOLO9000。
YOLO-v3中的改进有以下几点:
- Resnet
- FPN
SSD
SSD(Single Shot MultiBox Detector)是one-stage检测框架的一种,在准确度和速度上比同一时期同为one-stage的Yolo和two-stage的Faster R-CNN要好很多。SSD的网络结构图如下图所示: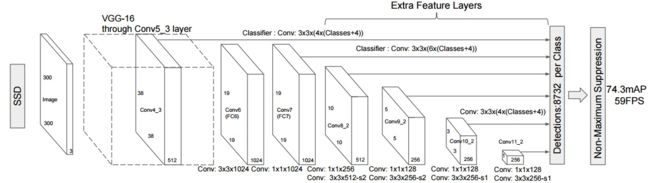
相比Faster R-CNN,SSD提取了不同尺度的特征图来做检测,大尺度特征图(较靠前的特征图)可以用来检测小物体,而小尺度特征图(较靠后的特征图)用来检测大物体;SSD中同样采用了不同尺度和长宽比的先验框(Prior boxes, Default boxes,在Faster R-CNN中叫做锚,Anchors);相比Yolo,SSD采用卷积来直接进行检测,而不是像Yolo那样在全连接层之后做检测。
SSD的几个特点详细描述如下:
- 网络结构
SSD中的特征提取主干网络使用的是VGG16,去除全连接层fc8,将fc6 和 fc7层转换为卷积层,pool5不进行分辨率减小。在fc6上使用dilated convolution弥补损失的感受野;并且增加了一些分辨率递减的卷积层(conv7-conv11),得到不同尺度的特征图。 - 设置先验框
在Yolo中,每个单元预测多个边界框,但是其都是相对这个单元本身(正方块),但是真实目标的形状是多变的,Yolo需要在训练过程中自适应目标的形状。SSD中使用位置和大小固定的Prior Boxes,即事先设置好的固定的proposal,相当于借鉴了Faster R-CNN中的Anchors概念,并有着自己的一套先验框匹配原则,具体可以参照原文和源码。 - 采用多尺度特征图用于检测
SSD使用不同深度的卷积层预测不同大小的目标,对于小目标使用分辨率较大的较低层,即在低层特征图上设置较小的Prior Boxes,高层的特征图上设置较大的Prior Boxes。 - 回归预测
SSD中使用3x3的卷积对每个Prior Box的类别和位置直接进行回归。
论文和代码的细节同样可以参考SSD 系列论文总结-方良骥与目标检测|SSD原理与实现-我是小将。
关于YOLO和SSD的详细区别,参考yolo-v3和SSD的一些对比
SSD的loss中,不同类别的分类器是softmax,最终检测目标的类别只能是一类。而在yolo-v3中,例如对于80类的coco数据集,对于类别进行判断是80个logistic分类器,只要输出大于设置的阈值,则都是物体的类别,物体同时可以属于多类,例如一个物体同时是person和woman。
Backbone network。ssd原版的基础网络就是VGG19,也可以用mobile-net、resnet等。yolo-v3的基础网络是作者自己设计的darknet-53(因为具有53个卷积层),借鉴了resnet的shortcut层,根据作者的话,以更少的参数、更少的计算量实现了接近的效果。
Anchor box。ssd从faster-rcnn中吸收了这一思想,采用的是均匀地将不同尺寸的default box分配到不同尺度的feature map上。例如6个feature map的尺度,default box的大小从20%到90%的占比,同时有aspect_ratios = [[2], [2, 3], [2, 3], [2, 3], [2], [2]] ,最终可以计算出不同default box大小。而yolo-v3延续了yolo-v2的方法:从coco数据集中对bouding box 的(width, height)进行聚类,作者聚出9类,每类中心点取出作为一个box_size, 将每三个box_size划分给一个feature map。例如总共有(10,13), (16,30), (33,23), (30,61), (62,45), (59,119), (116,90), (156,198), (373,326)共9组w,h, 作者将后三个(116,90), (156,198), (373,326)作为13 * 13 的gird cell上的anchor box size。图片输入。yolo-v3将输入图片映射到第一层feature map的固定比例是32。对于输入为416 * 416的图片,第一层feature map 大小为13 * 13。但是yolo-v3支持从300到600的所有32的倍数的输入。例如输入图片为320 * 320,这样第一层feature map就为10 * 10,在这样的gird cell中同样可以进行predict和match groudtruth。
Bounding Box 的预测方法。在不同的gird cell上,SSD预测出每个box相对于default box的位置偏移和宽高值。yolo-v3的作者觉得这样刚开始训练的时候,预测会很不稳定。因为位置偏移值在float的范围内都有可能,出现一个很大的值的话,位置都超出图片范围了,都是完全无效的预测了。所以yolov3的作者对于这位置偏移值都再做一个sigmoid激活,将范围缩为0-1 。b_x和b_y的值在(cell_x_loc, cell_x_loc+1), (cell_y_loc, cell_y_loc+1)之间波动。
————————————————
版权声明:本文为CSDN博主「MC-Zhang」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/BlowfishKing/article/details/80485006