Day05-《西瓜书》-支持向量机(DataWhale)
六、支持向量机
**来源:**https://www.bilibili.com/video/BV1Mh411e7VU?p=9
6.1 间隔与支持向量
训练样本集 D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x m , y m ) } , y i ∈ { − 1 , + 1 } D=\{(x_1,y_1),(x_2,y_2),...,(x_m,y_m)\},y_i\in\{-1,+1\} D={(x1,y1),(x2,y2),...,(xm,ym)},yi∈{−1,+1},分类学习的基本思想是:基于训练集D在样本空间中找到一个划分超平面,将不同类型的样本分开。
划分超平面的线性方程:
w T x + b = 0 w^Tx+b=0 wTx+b=0
其中, w = ( w 1 , w 2 , . . . , w d ) w=(w_1,w_2,...,w_d) w=(w1,w2,...,wd)为法向量,决定了超平面的方向; b b b 为位移项,决定了超平面与原点之间的距离。
划分超平面可被法向量 w w w 和位移 b b b 确定,记为 ( w , b ) (w,b) (w,b)。样本空间中任意点 x x x到超平面 ( w , b ) (w,b) (w,b) 的距离写成
r = ∣ w T x + b ∣ ∣ ∣ w ∣ ∣ r = \frac{|w^Tx+b|}{||w||} r=∣∣w∣∣∣wTx+b∣

假设超平面 ( w , b ) (w,b) (w,b)将训练样本正确分类,即对于 ( x i , y i ) ∈ D (x_i,y_i)\in D (xi,yi)∈D,若 y i = + 1 y_i=+1 yi=+1,则有 w T x i + b > 0 w^Tx_i+b>0 wTxi+b>0;若 y i = − 1 y_i=-1 yi=−1,则有 w T x i + b < 0 w^Tx_i+b<0 wTxi+b<0,令:
{ w T x i + b ≥ + 1 , y i = + 1 ( 6.3 ) w T x i + b ≤ − 1 , y i = − 1 \begin{aligned} \begin{cases} w^Tx_i+b &\geq +1,~~~ y_i=+1 ~~~~~~~~(6.3)\\ w^Tx_i+b &\leq -1,~~~y_i=-1 \end{cases} \end{aligned} {wTxi+bwTxi+b≥+1, yi=+1 (6.3)≤−1, yi=−1
则距离超平面最近的几个训练样本点使上式成立,称为”支持向量机“(support vector),两个异类支持向量机到超平面的距离之和【称为”间隔“(margin)】为:
γ = 2 ∣ ∣ w ∣ ∣ \gamma = \frac{2}{||w||} γ=∣∣w∣∣2
找具有”最大间隔“的划分超平面,即
m a x w , b 2 ∣ ∣ w ∣ ∣ s . t . y i ( w T x i + b ) ≥ 1 , i = 1 , 2 , . . . , m \begin{aligned} &\mathop{max}_{w,b} \frac{2}{||w||} \\ &s.t. ~~ y_i(w^Tx_i+b) \geq 1, ~~ i=1,2,...,m \end{aligned} maxw,b∣∣w∣∣2s.t. yi(wTxi+b)≥1, i=1,2,...,m
等价于最小化 ∣ ∣ w ∣ ∣ 2 ||w||^2 ∣∣w∣∣2
m i n w , b 1 2 ∣ ∣ w ∣ ∣ 2 ( 6.6 ) s . t . y i ( w T x i + b ) ≥ 1 , i = 1 , 2 , . . . , m \begin{aligned} &\mathop{min}_{w,b} \frac{1}{2}||w||^2 ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~(6.6)\\ &s.t. ~~ y_i(w^Tx_i+b) \geq 1, ~~ i=1,2,...,m \end{aligned} minw,b21∣∣w∣∣2 (6.6)s.t. yi(wTxi+b)≥1, i=1,2,...,m
上式是支持向量机(Support Vector Machine,SVM)的基础型。
推导:


6.2 对偶问题
对式(6.6)使用拉格朗日乘子法可得到其”对偶问题“(dual problem)
L ( w , b , α ) = 1 2 ∣ ∣ w ∣ ∣ 2 + ∑ i = 1 m α i ( 1 − y i ( w T x i + b ) ) ( 6.8 ) L(w,b,\alpha) = \frac{1}{2}||w||^2+\sum_{i=1}^m\alpha_i(1-y_i(w^Tx_i+b)) ~~~~~(6.8) L(w,b,α)=21∣∣w∣∣2+i=1∑mαi(1−yi(wTxi+b)) (6.8)
其中 α = ( α 1 , . . . , α m ) \alpha=(\alpha_1,...,\alpha_m) α=(α1,...,αm)。令 L ( w , b , α ) L(w,b,\alpha) L(w,b,α)对 w w w 和 b b b 的偏导为零,可得
$$
\begin{aligned}
w&=\sum_{i=1}^m\alpha_iy_ix_i ~~~~~(6.9) \
0 &= \sum_{i=1}^m\alpha_iy_i ~~~~~~~~(6.10)
\end{aligned}
KaTeX parse error: Can't use function '$' in math mode at position 17: …将(6.9)带入(6.8),将$̲L(w,b,\alpha)$ …
\begin{aligned}
&\mathop{max}\alpha ~ \sum{i=1}^m \alpha_i -\frac{1}{2}\sum_{i=1}m\sum_{j=1}m\alpha_i\alpha_j y_i y_j x_i^Tx_j\
& s.t~\sum_{i=1}^m \alpha_iy_i=0,\
&~~~~~\alpha_i \geq 0, ~~~i=1,2,…,m
\end{aligned}
KaTeX parse error: Can't use function '$' in math mode at position 6: 解出 $̲\alpha$ 后,求出 $w…
\begin{aligned}
f(x) &= w^Tx+b\
&=\sum_{i=1}m\alpha_iy_ix_iTx+b
\end{aligned}
上 述 过 程 需 要 满 足 K K T 条 件 ( K a r u s h − K u h n − T u c k e r ) , 上述过程需要满足KKT条件(Karush-Kuhn-Tucker), 上述过程需要满足KKT条件(Karush−Kuhn−Tucker),
\begin{cases}
\alpha_i \geq 0\
\
y_if(x_i)-1 \geq 0\
\
\alpha_i(y_if(x_i)-1) =0
\end{cases}
$$
使用拉格朗日函数:


6.3 核函数
原始样本空间内不一定存在一个正确划分两类样本的超平面。

针对这个问题,可将样本从原始空间映射到一个更高维的特征空间,使样本在这个特征空间内线性可分。【如果原始空间是有限维,即属性数有限,一定存在一个高维特征空间使样本可分】
常用核函数

【经验:文本数据通常使用线性核,情况不明时尝试高斯核】
(高斯核亦称为RBF核)
核函数还可以通过函数组合得到:
-
若 κ 1 \kappa_1 κ1 和 κ 2 \kappa_2 κ2 为核函数,对于任意正数 γ 1 、 γ 2 \gamma_1、\gamma_2 γ1、γ2 其线性组合 γ 1 κ 1 + γ 2 κ 2 \gamma_1\kappa_1+\gamma_2\kappa_2 γ1κ1+γ2κ2也是核函数
-
若 κ 1 \kappa_1 κ1 和 κ 2 \kappa_2 κ2 为核函数,则核函数的直积 κ 1 ⊗ κ 2 ( x , z ) = κ 1 ( x , z ) κ 2 ( x , z ) \kappa_1\otimes \kappa_2(x,z)=\kappa_1(x,z)\kappa_2(x,z) κ1⊗κ2(x,z)=κ1(x,z)κ2(x,z) 也是核函数
-
若 κ 1 \kappa_1 κ1 为核函数,则对于任意函数 g ( x ) g(x) g(x) , κ ( x , z ) = g ( x ) κ 1 ( x , z ) g ( z ) \kappa(x,z)=g(x)\kappa_1(x,z)g(z) κ(x,z)=g(x)κ1(x,z)g(z) 也是核函数
6.4 软间隔与正则化
之前一直假定训练样本在样本空间或特征空间中是线性可分的,即存在一个超平面将不同类的样本完成分开,但是实际很难确定合适的核函数使得训练样本在样本空间中线性可分。
缓解该问题的一个方法是:允许支持向量机在一些样本上出错。引入”软间隔“(soft margin)
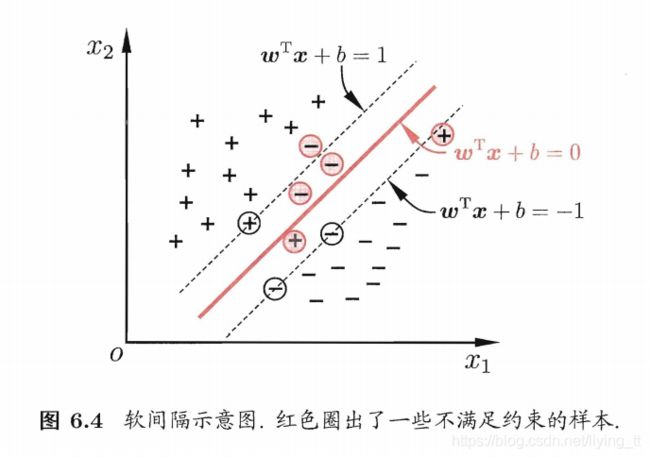
软间隔允许某些样本不满足约束
y i ( w T x i + b ) ≥ 1 y_i(w^Tx_i+b)\geq 1 yi(wTxi+b)≥1
在最大化间隔的同时,不满足约束的样本应尽可能少,优化目标可以写成
m i n w , b 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 m l 0 / 1 ( y i ( w T x i + b ) − 1 ) \mathop{min}_{w,b}~\frac{1}{2}||w||^2+C\sum_{i=1}^ml_{0/1}(y_i(w^Tx_i+b)-1) minw,b 21∣∣w∣∣2+Ci=1∑ml0/1(yi(wTxi+b)−1)
其中 C > 0 C>0 C>0 是一个常数, l 0 / 1 l_{0/1} l0/1 是”0/1损失函数“
l 0 / 1 ( z ) = { 1 , i f z < 0 ; 0 , o t h e r s l_{0/1}(z) = \begin{cases} 1, ~~~ if ~~z<0;\\ \\ 0, ~~~others \end{cases} l0/1(z)=⎩⎪⎨⎪⎧1, if z<0;0, others
常用的替代损失函数:
- hinge损失: l h i n g e ( z ) = m a x ( 0 , 1 − z ) l_{hinge}(z)=max(0,1-z) lhinge(z)=max(0,1−z)
- 指数损失(exponential loss): l e x p ( z ) = e x p ( − z ) l_{exp}(z)=exp(-z) lexp(z)=exp(−z)
- 对数损失(logistic loss): l l o g ( z ) = l o g ( 1 + e x p ( − z ) ) l_{log}(z)=log(1+exp(-z)) llog(z)=log(1+exp(−z))

推导:

6.5 支持向量回归

