论文研读笔记(四)——通过分布式深度强化学习从具有挑战性的环境中学习人群感知机器人导航
通过分布式深度强化学习从具有挑战性的环境中学习人群感知机器人导航(Learning Crowd-Aware Robot Navigation from Challenging Environments via Distributed Deep Reinforcement Learning)
最近我在学习机器人人群环境中导航的论文,此篇文章为“Matsuzaki S, Hasegawa Y. Learning Crowd-Aware Robot Navigation from Challenging Environments via Distributed Deep Reinforcement Learning[C]//2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022: 4730-4736.”的论文学习笔记,只供学习使用,不作商业用途,侵权删除。并且本人学术功底有限,如果有思路不正确的地方欢迎批评指正!
摘要
本文提出了一种深度强化学习 (DRL) 框架,用于在拥挤的环境中安全高效地导航。在这里,机器人使用一种新的奖励功能来学习合作行为,该功能会惩罚干扰行人运动的机器人动作。此外,我们提出了一种模拟行人政策,反映了实际行人运动的数据。此外,我们引入了一种碰撞检测,该检测考虑了行人的个人空间以产生亲和力机器人行为。为了有效地探索这种模拟环境,我们建议使用 Ape-X [1] 进行分布式学习。我们将机器人部署在真实环境中,并在路径长度、行程时间和突然避让次数方面验证了其与实际人类相比的人群感知导航性能。
- 个人总结:
设计新的奖励函数,提出模拟行人的策略,引入一种碰撞检测,并进行分布式学习
一、介绍
随着机器人技术的最新发展,现在越来越多的机器人提供服务,包括在拥挤环境中的运输和引导。然而,像人类一样有效和安全地导航仍然是一个挑战 [2],因为行人正在移动障碍物,不断地做出决定和移动,从而使他们的下一步行动变得不可预测。此外,拥挤环境中行人之间的交互变得更加复杂,使导航更加困难(图片1)。

最近,已经研究了几种深度学习(DL)方法来应对这一挑战。使用 DL 的人群感知导航方法大致分为模仿学习 (IL) 和深度强化学习 (DRL)。 IL 方法使用广泛的专家演示优化策略。由于它直接学习行人的行为,因此显示出有希望的结果 [3]、[4]。此前,文中提出了一种 IL 方法,该方法在路径长度、行程时间以及在真实拥挤环境中的突然回避倾向方面实现了与人类等效的导航 [5]。然而,IL 方法需要多次和技术来收集和随后处理数据。此外,IL 不能应用于与人不同大小的机器人,也不适合使用学习策略控制机器人。因此,在使用比人大的机器人(例如工厂中的运输机器人)时,存在一个严重的限制。
然而,DRL 方法创建了对行人和机器人进行建模的模拟环境,并通过与环境交互来获取策略。因此,任何大小和机制的机器人都学会考虑它们的特征。DRL 方法显示出有希望的结果,但没有研究表明它们可以导航在拥挤的环境中比人类好或好。恰恰是一些研究已经在环境中[6-10]部署了该方法。据文中所知,没有任何 DRL 方法可以与人类进行定量比较,也没有在拥挤的环境中表现出可比的性能。因此,证明了文中的方法在模拟环境中的有效性,类似于传统的评估方法,并在拥挤的环境中与真实的人一起测量路径长度、旅行时间和类似于行人的突然避让的趋势。
以下是文中的主要贡献。 (1) 文中提出了一个结合了合作奖励、使用个人空间的碰撞检测和反映实际行人运动的行人策略的环境。 (2) 为了有效地探索这个环境,文中提出了一个使用 Ape-X 的训练过程。 (3) 文中的导航方法在实际拥挤的环境中进行了模拟和测试,并展示了可喜的结果。文中将基于 Ape-X 的导航方法称为 NAX。
二、相关工作
A.在拥挤的环境中导航
人群感知导航方法可分为两类,基于模型的方法和基于学习的方法。ORCA [12]、[13] 和 RVO [14] 是速度障碍物 [15] 的扩展,是基于模型的方法之一,以在互惠假设下找到最佳无碰撞速度。另一种称为社会力 [16] 的方法,使用排斥和吸引力来模拟人类互动。在这些基于模型的方法中,适当的参数随情况而变化,包括人口密度或目标距离.因此,很难找到适合拥挤环境的单个参数。随着 DL 的发展,基于学习的方法得到了积极的研究,使用 DRL 的方法已经显示出有希望的结果 [6]、[8]、[9], [11].这些研究使用模拟环境来收集机器人经验,然后使用这些经验更新价值函数或策略。但是,仿真环境中行人的策略与机器人相同(互惠假设),零速度,不合作(直奔目标),ORCA,以上一种和/或组合,没有模型反映真实采用行人的运动。因此,当在这个模拟环境中训练的价值函数或策略在真实环境中运行时,它的表现可能与模拟不同。因此,文中创建了一个反映真实行人运动的环境,并使用该环境训练状态-动作价值函数。
B.人类感知奖励函数
与行人一起导航是拥挤环境中机器人的一项基本功能[2]。机器人与行人协同导航,避免附近行人不适,减少不必要的避让,实现高效导航。在 DRL 框架中,可以通过惩罚违反行人的行为来获得行人可接受的策略。
SA-CADRL [6] 采用了一种方法,通过惩罚超车、超车和穿越三种行为来诱导社会规范。由于拥挤环境中的复杂人类交互,仅惩罚这三种行为不足以纠正机器人的干扰行为。 [17] 中的作者定义了一个社会安全区域,并采用了惩罚机器人区域和行人区域相交的方法。该方法考虑机器人动作相对于行人运动方向的影响,但不考虑运动方向以外的其他方向。提出了一种奖励功能,可以改变障碍物的安全半径和像行人一样移动障碍物以实现社交方式[18]。也经常使用基于与他人的距离来惩罚不适的奖励函数[10],[19]。然而,仅从障碍物和机器人之间的位置关系学习社交方式是困难的。因此,文中提出了一种新颖的奖励函数来惩罚违反行人运动的机器人动作,而不仅仅是在特定场景中。
C.深度强化学习的训练过程
在反映实际行人行为的模拟环境中,在不阻碍周围行人的情况下进行导航具有挑战性,因此有效的探索对于学习最优策略很重要。最近的 DRL 研究表明,分布式学习可以提高性能 [1]、[20]、[21 ].对于拥挤环境中的导航,[22] 表明通过结合分布式学习可以提高性能。具有共享策略的多个机器人被释放到一个环境中,它们独立收集经验。课程学习范式 [23] 被结合起来,并且提出了使用由两个阶段组成的训练过程来加速策略收敛的方法:阶段 1 和 2 分别有 20 个和 58 个机器人。与 [22] 相比,[24] 提出了一种在学习智能体之间的交互的同时加速收敛的方法通过将智能体的数量分为四:2、4、8 和 10 个智能体。这里,合适的机器人行为取决于智能体的数量,即在 10 智能体环境中,由于密度较高,碰撞前的避免增加,但是,在 2 智能体环境中,提前避免增加。因此,通过覆盖环境,出现了机器人学习仅针对最终环境的行为的问题。因此,文中提出了一个训练过程,允许机器人在使用课程学习的同时有效地探索不同数量的智能体。
三、方法
A.问题表述
在这项工作中,文中开发了人群感知导航作为部分可观察马尔可夫决策过程 (POMDP)。让 S T S_T ST和 a t a_t at分别是代理在时间 t 的状态和动作。这里,代理的状态是 s t = [ s t O , s t h ] s_t=[s^O_t , s^h_t] st=[stO,sth] ,由所有代理都可以观察到的状态 s t o s^o_t sto和只能由代理本身观察到的隐藏状态 s t h s^h_t sth组成。可观察状态是代理在 2D 坐标系中的位置和速度序列 s t o = [ p t x , p t y , v t x , v t y , … , p t − n x , p t − n y , v t − n x , v t − n y ] s^o_t=[p^x_t,p^y_t,v^x_t,v^y_t,\dots,p^x_{t−n},p^y_{t−n},v^x_{t−n},v^y_{t−n}] sto=[ptx,pty,vtx,vty,…,pt−nx,pt−ny,vt−nx,vt−ny],隐藏状态是代理的目标、首选速度和航向角 s t h = [ p t g x , p t g y , v t p r e f , ψ t , … , p t − n g x , p t − n g y , v t − n p r e f , ψ t − n ] s^h_t=[p^{gx}_t,p^{gy}_t,v^{pref}_t,ψ_t,\dots,p^{gx}_{t−n} ,p^{gy}_{t−n},v^{pref}_{t−n},ψ_{t−n}] sth=[ptgx,ptgy,vtpref,ψt,…,pt−ngx,pt−ngy,vt−npref,ψt−n]。在真实环境中,检测失败取决于机器人中实现的人体检测器的准确性。使用顺序状态作为输入,机器人有望抵抗检测失败。从计算成本和这个优势之间的权衡,设置 n = 3 n=3 n=3。代理的动作由平移和旋转速度组成,即 a t = [ v t , ω t ] a_t=[v_t, ω_t] at=[vt,ωt]。这里,平移和旋转速度分别设置为 v t ∈ 0 , 0.3 , 0.6 , 0.9 , 1.2 vt∈{0, 0.3, 0.6, 0.9, 1.2} vt∈0,0.3,0.6,0.9,1.2和 ω t ∈ − π / 12 , − π / 24 , 0 , π / 24 , π / 12 ωt∈{-π/12, -π/24, 0, π/24, π/12} ωt∈−π/12,−π/24,0,π/24,π/12。原因是文中之前的研究 [5] 表明,行人轨迹可以分别以 1.2 和 π/12 的最大平移速度和旋转速度近似再现。此外,从搜索空间大小和实际机器人运动之间的平衡(离散化越精细,越平滑),文中将平移和旋转速度分别分为五类。
设 γ γ γ为折扣因子,机器人通过找到策略 π : s t j n → a t π:s^{jn}_t→ a_t π:stjn→at 来最大化预期折现回报 C t = ∑ k = 0 ∞ γ t ( k ) r t + k + 1 C_t = \sum^{∞} _{k=0}γ^{(k)}_tr_{t+k+1} Ct=∑k=0∞γt(k)rt+k+1,其中 s t j n = [ s t , s ~ t o ] s^{jn}_t=[s_t,\tilde s^o_t] stjn=[st,s~to], s t s_t st 是智能体的状态, s ~ t o \tilde s^o_t s~to是其他智能体的可观察状态。在这里,机器人的策略是使用一种贪心策略 ε \varepsilon ε来构建的,该策略与深度神经网络近似的状态-动作值函数 q q q相关(参见 第三节-E部分)。
B.训练过程
为了解释 NAX,从训练过程开始。图 2 显示了训练过程。使用 Ape-X [1] 中的方法训练状态-动作值函数 q。文中创建具有多个 CPU 的环境以有效地收集经验。这些体验是使用优先体验重放方法[25]进行采样的,并且网络的参数由学习者在单个 GPU 上更新。
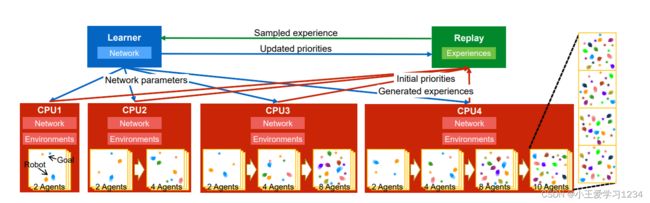
文中采用类似 [24] 和 [22] 的方法,将多个机器人放置在一个环境中以有效地收集更多经验。此外,如 [24] 中采用的将阶段智能体的数量从 2 个增加到 10 个。此外,正如 [22] 中提出的,实际上在单个 CPU 内创建了多个环境,以收集更多经验。与 [22] 中在单个 CPU 上创建各种环境的方法不同,文中的方法使用固定数量的智能体创建多个环境。这些环境的数量经过实验调整以获得 40 个智能体。即,对于每个 CPU,分别在 2、4、8 和 10 个智能体的学习过程中创建了 20、10、5 和 4 个虚拟环境。图 2 有四个 CPU,这意味着 160 个智能体同时运行。如 Ape-X 中所述,分布式学习中参与者(在文中的例子中是机器人)的数量会显着影响性能,因此文中采用这种方法来增加机器人的数量。
除了结合和修改传统方法之外,文中还提出了一种方法,通过改变每个 CPU 在最终环境中的代理数量来收集更多样化的体验。在图 2 中,使用了四个 CPU,而 2-、4 -、8 和 10 代理环境分别是第一个、第二个、第三个和最后一个 CPU 上的最终环境。这个数字是参考 [7] 设置的。此外,文中设置了环境中的代理数量当机器人在训练环境中的目标到达率超过 0.8 时增加。这样,环境会在所有 CPU 上同时更新。此外,当 CPU 更新的代理数量超过其最终环境时,其环境保持开放并不断收集经验在那个最终的环境中。这里,代理是指模拟的机器人和行人,并且该比率在每一集之间随机变化。此外,第 i 个机器人执行一个贪婪策略,其中 i = 1+ i N α = 0.4 , α = 7, 指Ape-X 参数。此外,环境的大小固定为 8 × 8。这种提出的方法可以防止网络过度拟合最终环境中的代理数量,并通过课程学习提高学习效率。因为可以进行探索有效地使用许多机器人,机器人即使在具有挑战性的环境中也能学习到合适的行为。
以下部分。

C.逼真的模拟行人
SFM [16] 是一种使用吸引力和排斥力来模拟人类运动的方法。很难使用 SFM 并设置适当的单个参数作为机器人的策略。相反,由于 SFM 通过更改其参数来生成各种运动,因此可以通过将 SFM 设置为行人策略来创建多个环境。 [27] 中的作者提出了从真实行人数据中估计 SFM 参数的方法。文中用它从文中之前的工作 [5] 中获得的行人流量数据中估计 SFM 参数。表 I 显示了估计参数的平均值和标准偏差。根据这些估计的参数,在模拟环境中生成行人。为了给每一集产生的行人分配不同的参数,文中使用正态分布设置每个参数。
D.学习合作行为
文中的奖励函数 r t r_t rt定义为:

r t g r^g_t rtg是朝着目标前进的奖励, r t s r^s_t rts是实现平稳运动的奖励, r t v r^v_t rtv是惩罚违反行人运动的动作的奖励。 r t g r^g_t rtg定义为:

其中 d t g d^g_t dtg是时间 t 时机器人到其目标的欧几里得距离。 r t s r^s_t rts定义为:

其中 j t j_t jt是机器人在全局坐标系中位置的三阶导数,称为 j e r k jerk jerk,通过最小化 jerk [28]、[29] 可以实现平滑的轨迹。
给定一个目标机器人,文中可以推导出奖励函数 r t v r^v_t rtv来惩罚机器人的干扰行为。图 3 显示了概览。目标机器人以黑色显示,机器人周围的环境充满了行人和其他机器人。让周围的第 i i i个智能体(行人和其他机器人)观察关节状态 s ~ i , t j n \tilde s^{jn}_{i,t} s~i,tjn 并采取行动 a ~ i , t \tilde a_{i,t} a~i,t。这个 r t v r^v_t rtv定义为:

其中 N 是环境中代理的数量, a ~ i , t \tilde a_{i,t} a~i,t是从 s ~ i , t w \tilde s^{w}_{i,t} s~i,tw映射的动作,不包括目标机器人,即 s ~ i , t j n = [ s ~ i , t w , s ^ t o ] \tilde s^{jn}_{i,t}=[\tilde s^{w}_{i,t},\hat s^o_t] s~i,tjn=[s~i,tw,s^to].这里, s ^ t o ] \hat s^o_t] s^to]是可以从第 i i i个智能体观察到的目标机器人的状态。由于干扰周围智能体的动作会受到惩罚,因此目标机器人会采取对周围智能体友好的动作。另外,没有采用不切实际的不可见设置(其中周围的行人在不考虑机器人的情况下移动)[8]-[10],[17],机器人在避免碰撞的同时学会向目标移动。引入了不可见的设置,因此机器人学会在避免碰撞的同时向目标前进周围的行人有像 ORCA 一样避开机器人的策略。因此,在没有隐形设置的情况下,周围的行人会避开机器人,因此机器人只会学习向目标推进。相反,文中的方法会因干扰行人而产生惩罚通过 r t v r^v_t rtv,以便机器人学会避开也避开机器人的行人。在几次初步实验中调整参数后,文中最终设置 r a r r i a v a l = 1.0 , w g = 0.1 , w w = − 0.1 , w j = − 0.2 r_{arriaval}=1.0,w_g=0.1,w_w=-0.1,w_j=-0.2 rarriaval=1.0,wg=0.1,ww=−0.1,wj=−0.2和 w v = − 0.2 w_v=-0.2 wv=−0.2。

与以前的研究不同,文中没有为碰撞设置任何奖励。相反,文中引入了一种新的碰撞检测方法。人类有一个个人空间(PS)[30],它是蛋形的。每个人都持有、保存和更新 PS,并在被他人侵犯时做出反应。以前的研究使用完美圆进行碰撞检测,但通过考虑 PS 进行碰撞检测,学习了更多的协作行为,例如不在行人面前横穿。根据 Amaoka 的公式 [31],文中定义机器人碰撞概率 P c = e x p ( − 1 2 ( p i a − p r ) t Σ − 1 ( p i a − p r ) ) P_c={\rm exp}(-\frac{1}{2} (p^a_i-p^r)^tΣ^{-1}(p^a_i-p^r)) Pc=exp(−21(pia−pr)tΣ−1(pia−pr))以确定机器人与周围代理之间的碰撞。其中, p r = [ p t x , p t y ] p_r=[p^x_ t,p^y_t] pr=[ptx,pty], p i a p^a_i pia 是第 i i i 智能体的位置,以及

按照[31]的设置,文中设置 σ x x = 0.255 m σ_{xx}=0.255m σxx=0.255m。
E.网络结构
有几种嵌入观察状态的方法,包括 LSTM [7]、Conv2D [5] 和池化导数 [6]、[10]。文中选择 GCN [32] 导数 [9] 是因为它具有适应性,即使行人数量发生变化,输入维度也不会变大并且可以对特征进行卷积。此外,与 GAT [33] 方法一样,考虑了节点之间的关系。即,状态-动作值函数 q 用改进的 RGL [9] 近似。虽然原始 RGL 使用人类节点特征并采用基于模型的 DRL 方法,但文中仅使用机器人节点特征并应用无模型 DRL 方法来估计 q。与 Ape-X 一样,损失 l(θ) 是多步自举 [34]、双 Q 学习 [35] 和目标网络 [36] 的组合,即 l ( θ ) = 1 2 ( G t − q ( s t j n , a t , θ ) ) 2 l(θ)=\frac{1}{2} (G_t-q(s^{jn}_t,a_t,θ))^2 l(θ)=21(Gt−q(stjn,at,θ))2, 其中, G t = ∑ k = 1 n ^ γ k − 1 r t + k + γ n ^ q ( s t + n ^ j n , a r g m a x a t + n ^ q ( s t + n ^ j n , a t + n ^ , θ ) , θ ˉ ) G_t=\sum ^{\hat n}_{k=1}γ^{k−1}r_{t+k}+γ^{\hat n}q(s^{jn}_{t+ \hat n},{\rm argmax}_{a_{t+{\hat n}}}q(s^{jn}_{t+{\hat n}},a_{t+\hat n}, θ), \bar θ) Gt=∑k=1n^γk−1rt+k+γn^q(st+n^jn,argmaxat+n^q(st+n^jn,at+n^,θ),θˉ)。 θ ˉ \bar θ θˉ表示目标网络的参数。相关参数已根据机器规格和环境进行了调整,参考 Ape-X 参数。以下是具体的。学习者等到回放积累了超过 10000 次经验后才开始学习。文中使用居中的 RMSProp 优化器最小化多步损失(nˇ = 3),学习率为 0.00025 / 4,衰减为 0.95,epsilon 为 1.5 e − 7 1.5e^{-7} 1.5e−7且没有动量。梯度范数被裁剪为 40。目标网络每 2000 个训练批次从在线网络中复制一次。
四、实验结果
A.实验设置
文中展示了 NAX 方法的实验和结果。文中通过在模拟场景和实际环境中进行评估来证明 NAX 的有效性和安全性,并将其与最先进的 (SOTA) 方法,即 RGL [9] 进行比较和 HICA [5]。文中选择 RGL 作为基线,因为它显示了出色的导航性能在拥挤的环境中使用基于模型的 DRL 及其网络架构与文中的几乎相同。见 第三节-E部分对于网络架构的差异。 HICA是一种方法基于IL,并且由于它已经实现并验证了与拥挤的真实行人等效的导航环境,文中比较和验证的有效性真实环境中的 NAX。图 4(a) 显示了实验中使用的环境。机器人的开始和目标位置分别是(-8, 0)和(8, 0)。那里是环境中的 15 名行人以及起点和目标每个行人的位置随机设置在绿色图 4(a) 上的区域。文中定义开始和结束测量线分别为 x = -2.5 和 x = 2.5,并比较通过该区域时的测量结果。这个环境是在模拟和测试中创建和测试的真实环境。

B.仿真结果
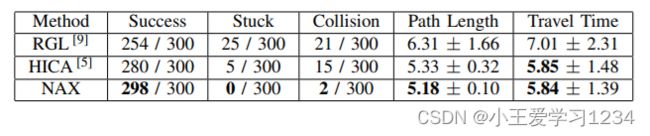
在仿真环境中,使用半径为 0.25 的正圆代替 PS 进行碰撞检测。文中使用 ORCA 进行行人策略,涉及以下参数:时间范围(用于计算无碰撞速度)、扩展的安全半径, 和最大速度。这些参数在 t i m e H o r i z o n ∈ [ 0.5 , 2.0 ] timeHorizon ∈ [0.5, 2.0] timeHorizon∈[0.5,2.0]、 e x p a n d e d R a d i u s ∈ [ 0.0 , 0.2 ] expandedRadius ∈ [0.0, 0.2] expandedRadius∈[0.0,0.2]和 m a x S p e e d ∈ [ 0.8 , 1.4 ] maxSpeed ∈ [0.8, 1.4] maxSpeed∈[0.8,1.4]范围内为每个行人和场景随机分配。不启用不可见设置ORCA 不是反映实际行人运动的模型,但由于文中不能将 SFM 用于周围行人的策略进行公平评估,因此文中采用了在模拟评估过程中使用的 ORCARGL 和 HICA。在这里,每种方法都测试了 300 次。表二显示了定量评估结果采用的评估指标、路径长度和行程时间比较导航的效率。还有碰撞率被用来比较安全程度导航。此外,评估的目标和停滞率任务(目标达成)成就的程度。
表二显示 NAX 方法在所有指标中都有最好的结果。为了进一步了解,图 4 显示了一个代表性场景的结果。红色轨迹表示机器人。行人由其他颜色表示。由于 RGL 策略是在不可见的环境下训练的,因此机器人有许多行为使其绕着一个大圆圈转。在图 4© 中,机器人试图大转弯,但行人 D 对机器人做出反应,因此他们相互避开,导致碰撞。如果行人 D 一直在隐形环境中移动,它可能不会与机器人发生碰撞,但由于行人和机器人在现实世界中相互影响,因此在考虑应用于真实环境时,在隐形环境中的评估是不合适的。因此,RGL 在所有指标中显示最差的结果。
HICA 显示出比 RGL 更好的结果。在图 4(d) 中,机器人到达了目标,但它的轨迹与行人 J J J和 O O O相交。在 HICA 方法中,IL 输出的最小平移速度设置为 0.8 m/s,并且减速和停止低于 DWA [37]。然而,由于 DWA 是一种自反式避障算法,它无法输出有效避开行人 J J J和 O O O所必需的停止和让路等预测行为,从而导致抑制他们的行为。然而,文中的 NAX 方法在 DRL 框架内处理减速和停止,因此在不干扰周围行人的情况下执行适当的避让和减速(图 4(b))。因此,NAX 方法具有最短的路径长度,因为机器人不需要避免不必要的轨迹。在图 4(d) 中,假设行人 J J J和 O O O是更具攻击性的角色,他们会发生碰撞。因此,不阻碍周围行人的运动导致更少的碰撞,因此文中的 NAX 方法实现了最低的碰撞率。
C.消融实验
由于 NAX 方法整合了几个想法,因此进行了消融研究以了解每个组件的贡献。在每次消融中,文中从完整的 NAX 组合中删除了一个组件。图 5 显示了完全 NAX 方法与四个消融变体的碰撞次数、路径长度和行程时间的比较。没有协作是在训练期间排除 r t v r^v_t rtv的配置,如 III-D 中所述。没有 SFM 是其中的配置行人有 90 % 90\% 90% 的策略来自机器人,剩下的 10 % 10\% 10%是零速度或不合作,参考 [24] 的设置,没有使用 III-C 中描述的方法。另外,No PS 是一种配置,其中,在训练过程中,碰撞检测是在一个完美的圆圈中进行的,而不是 III-D 中描述的 PS。此外,没有多 CPU 是一种配置,在该配置中,在训练期间,而不是使用 III-B 中描述的多个 CPU,仅图 2 中的 CPU4 和每个阶段的单一环境是使用,即与[24]中相同的多级配置。


性能上最大的差异是在无多 CPU 中,机器人仅从单一环境中收集经验,导致探索效率低下,并阻止机器人在困难环境中学习合适的行为。紧随其后的是 N o S F M No \ SFM No SFM,由于训练是在互惠假设下进行的,因此机器人在 ORCA 中表现出与机器人策略不同的更差表现。增加非合作和零速度策略的行人比例有望提高性能,但增加比例可能会导致与 RGL 相似的结果,因为配置更接近于不可见设置。此外,在真正拥挤的环境中,在互惠假设下导航可能很危险,因为行人与机器人没有相同的策略。 N o P S No PS NoPS是唯一在路径长度和行程时间上都优于完全 NAX 的配置,因为碰撞检测比 PS 小,因此机器人学会了以在行人之间通过的方式行动。但是,它的碰撞量是完整 NAX 的 6.5 倍。在考虑将其应用于真实环境时,避免碰撞比稍微增加路径长度和旅行时间更重要。此外,在 N o P S No\ PS No PS配置中,可能没有考虑行人的运动方向,因此难以产生亲和力行为,包括不在行人面前横穿。在 N o c o o p e r a t i o n No\ cooperation No cooperation中,路径长度与完整 NAX 的路径长度相当,但经过的时间更短。也就是说,机器人的行为比完整 NAX 更激进,导致碰撞次数是完整 NAX 的三倍。从这些结果中,文中得出结论,完整的 NAX 在效率和安全性之间具有最佳平衡。
D. 真实世界实验
图 1 显示了真实世界实验的照片。本实验视频见附件。与模拟环境一样,创建了一个有 15 名行人的拥挤环境,并分别使用 NAX、RGL 和 HICA 进行了 50 次导航实验。为了将结果与行人的实际导航进行比较,文中随机选择行人并让他们导航 50 次。路径长度和旅行时间被用作评估指标来比较导航的效率。以下是用于比较导航安全程度的指标的描述。与仿真环境不同,实际环境中机器人与行人之间没有发生碰撞。实验表明,在模拟环境中,行人在可能导致碰撞的情况下,通过做出不合理的动作来避免碰撞。因此,将这种突然回避视为安全指标。不能通过过度加速或减速来判断突然回避,因为情况因相互作用而异。因此,手动计算了突然回避的次数,因为突然性是主观的。为了尽量减少观察者造成的偏差,两名工程师检查了实验视频,但没有被告知建议的方法是什么。每种方法的突然回避视频在附件中。
表III显示了定量评价的结果。在每种方法的结果与人类结果之间进行了 Mann-Whitney U 检验,p 值如表 III 所示。如果 U 检验的临界 p 值为 0.05,则 RGL 在路径长度和行驶时间方面不如行人结果。它将行人策略设置为 ORCA 并启用与真实行人运动不同的不可见设置。HICA 在路径长度和行驶时间方面显示出与人类相当的结果,因为它模仿了人类轨迹。对于突然回避的度量, HICA 的表现不如人类。对于机器人靠近行人的情况,HICA方法不进行预测性避让,因为DWA主导了输出速度,导致周围行人突然避让。然而,NAX 方法在旅行时间和突然回避的数量方面与人类一样好。此外,NAX 在构建的场景中实现了比人类路径长度更短的导航。
五、结论
本文提出了使用 DRL 的 NAX 框架,以在构建的场景中实现与人类等效的人群感知机器人导航。本文创建了一个环境,该环境结合了合作奖励、使用 PS 的碰撞检测和使用 SFM 的行人策略。本文提出了一个使用 Ape-X 的训练过程,以在这种环境中有效地训练 stateaction 值。 NAX 框架在基于模拟和真实世界的实验中优于 SOTA。在现实世界的实验中,NAX 方法显示出与真人相当的结果。未来,文中将考虑在真实环境中进行定量比较,例如商场和机场。