DGP 论文阅读笔记
DGP 论文阅读笔记
论文题目:Exploiting Deep Generative Prior for Versatile Image Restoration and Manipulation
Exploiting Deep Generative Prior for Versatile Image Restoration and Manipulation-ReadPaper论文阅读平台
文章目录
- DGP 论文阅读笔记
-
- 论文结构
- 摘要
-
- 原文
- 核心
- 研究背景
-
- 图像反演
- 图像先验
- Adversarial Attack
- Adversarial Defense
- 研究意义
- 深度生成先验
-
- 深度生成先验
- 判别器的影响
- 渐进式重建
- 重建结果
- 图像修复
-
- 图像上色
- 图像补全
- 超分辨率
- 灵活性
- 泛化性
- 随机扰动
- 图像插值
- 类别转换
- 论文总结
论文结构
- Introduction
- Related Work
- Method
3.1 Deep Generative Prior
3.2 Discriminator Guided Progressive
Reconstruction
原文讲解 - Applications
4.1 Image Restoration
4.2 Image Manipulation - Conclusion
摘要
原文
Learning a good image prior is a long-term goal for image restoration and manipulation. While existing methods like deep image prior (DIP) capture low-level image statistics, there are still gaps toward an image prior that captures rich image semantics including color, spatial coherence, textures, and high-level concepts. This work presents an effective way to exploit the image prior captured by a generative adversarial network (GAN) trained on large-scale natural images. As shown in Fig.1, the deep generative prior (DGP) provides compelling results to restore missing semantics, e.g., color, patch, resolution, of various degraded images. It also enables diverse image manipulation including random jittering, image morphing, and category transfer. Such highly flexible restoration and manipulation are made possible through relaxing the assumption of existing GAN-inversion methods, which tend to fix the generator. Notably, we allow the generator to be fine-tuned on-the-fly in a progressive manner regularized by feature distance obtained by the discriminator in GAN. We show that these easy-to-implement and practical changes help preserve the reconstruction to remain in the manifold of nature image, and thus lead to more precise and faithful reconstruction for real images. Code is available at this https URL.
核心
- 深度图像先验(DIP)可以捕获低级的图像统计信息,但在捕获图像高级语义(包括颜色、空间一致性、
纹理和高级概念)方面仍不尽如人意 - 提出了一种有效的方法来利用被GAN捕获的图像先验信息,这个GAN是在大规模自然图像上训练的
- 深度生成先验(DGP)提供了令人信服的结果来恢复缺失的语义,如颜色、块、分辨率、各种退化图
像;它还支持各种图像操作,包括随机抖动、图像变形和类别变换 - 在进行GAN-inversion时,我们把生成器进行渐进式的finetune,这个过程是由判别器提取的特征间的距离来指引的
- 这些易于实现的策略有助于保留自然图像的流形,从而来更精确可信的重建真实图像
研究背景
图像反演
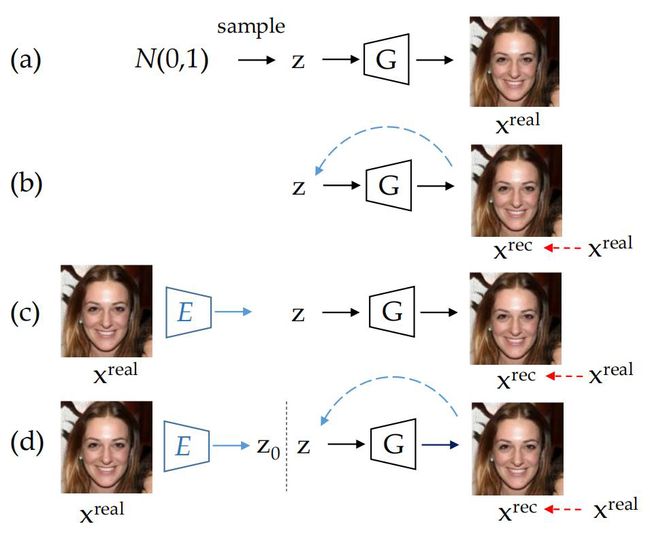

图像先验
不同的神经网络可以完成 图像去噪、去水印、消除马赛克等任务,但能否让一个模型实现上述所有
• 提出了一种通用的方法,来实现去噪、去水印、超分辨率等多种任务
• 让一个预训练的 CNN 网络去学习被破坏的图像(例如加入噪点的图像),发现这个网络可以自行学会如何重建图像
• 网络仅使用了输入的被破坏过的图像做为训练,它没有学习过未受破坏的正常图像,但最终恢复的效果依然很好,这说明自然图像的局部规律和自相似性确实很强
Adversarial Attack
• 白盒攻击 White-box attack,也称为open-box 对模型和训练集完全了解,这种情况比较简单
• 黑盒攻击 Black-box attack,对模型不了解,对训练集不了解或了解很少
• 定向攻击 targeted attack,对于一个多分类网络,把输入分类误判到一个指定的类上,通过改变一张图片中的某些
像素点的值,使改变后的图片和原图片肉眼看不出太大分别,但分类器结果发生改变
• 非定向攻击 non-target attack,只需要生成对抗样本来欺骗神经网络,可以看作是上面的一种特例
Adversarial Defense
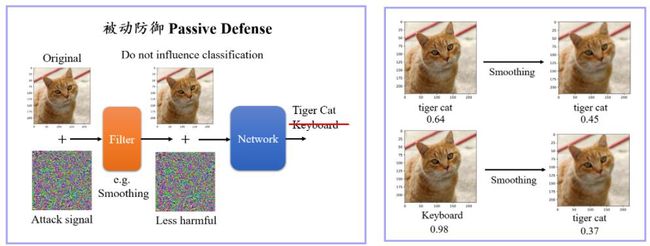
• 被动防御通过不修改原始模型来进行防御,主要方法有模型前加入filter,输入样本进行padding、伸缩变化等
• 主动防御,针对算法A训练的主动防御模型无法防守算法B训练出的攻击数据
研究意义
• 提出了一种挖掘GAN中图像先验的方式
• 在多个任务上揭示了GAN作为一种通用图像先验的潜力,首次将其应用于复杂图片的对抗防御,提出了同时插值隐变量和生成器的渐变式图像反演方法
• 实验中DGP所展现出的强大的像素间空间关系模拟能力也十分有趣

深度生成先验
深度生成先验
Deep Generative Prior
在实践中,仅仅通过优化隐向量z难以准确重建ImageNet这样的复杂真实图像
• DIP仅依靠输入图像的统计信息,无法应用于需要更一般的图像统计信息的任务,如图像上色和图像编辑
• 训练GAN的数据集(ImageNet)本身是自然图片中很少的一部分
• GAN受限于有限的模型性能和mode collapse,其模拟的图片分布与训练集图片分布也存在鸿沟

• 我们感兴趣的是研究一种更通用的图像先验,即在大规模自然图像上训练的GAN生成器用于图像合成
• 具体来说,是一个基于GAN-inversion的图像重构过程
• 即使存在以上限制,GAN仍然学习了丰富的图片信息,为了利用这些信息并且实现精确重建,我们让生成器online地适应于每张目标图片,即联合优化隐向量z和生成器参数
• 我们将此新的目标称为深度生成先验(DGP)
• DGP显著提高了图像重构的效果,因为生成器拟合单个图像比拟合一个数据流形更容易收敛
• 设计合适的距离度量和优化策略非常关键
• 在重建过程中,生成器原始的生成先验被修改了,输出真实自然图像的能力可能会下降
判别器的影响
Discriminator Matters
• 从 latent space Z 中随机抽取几百个候选的初始 latent code,并选择在度量L下重构效果最好的一个
• 在GAN重建中,传统的距离度量方法是 MSE 或 Perceptual loss
• 在允许优化生成器参数时,将这些传统距离度量用在图像恢复如上色任务中,常常无法准确恢复颜色,并且重建过程中图像会变得模糊,需要设计更好的优化方式来保留生成器的原有信息
• 我们在该工作中选择使用与该生成器对应的判别器来作为距离度量
• 与Perceptual loss所采用的VGGNet不同,判别器并非在一个第三方的任务上训练,而是在预训练时就与生成器高度耦合,它天然地适用于调整生成器的输出分布
• 使用这种基于判别器的距离度量时,重建的过程更加自然和真实,最终颜色恢复的效果也更好
渐进式重建
Progressive Reconstruction
 • 虽然改进的距离度量带来了更好的效果,但是图像复原的结果仍存在非自然痕迹,因为生成器在针对目标图片优化时,浅层参数匹配好图片整体布局之前,深层参数就开始匹配细节纹理了
• 虽然改进的距离度量带来了更好的效果,但是图像复原的结果仍存在非自然痕迹,因为生成器在针对目标图片优化时,浅层参数匹配好图片整体布局之前,深层参数就开始匹配细节纹理了
• 使用渐进式重建的策略,即在微调生成器时,先优化浅层,再逐渐过渡到深层,让重建过程“先整体后局部”
• 与非渐进策略相比,这种渐进策略更好地保留了缺失语义和现有语义之间的一致性
重建结果
Results
• 使用B i g G A N模型
• 基于I m a g e N e t进行训练
• 使用I m a g e N e t验证集中的1 0 0 0张图像进行实验,取每类的第一张
• 相比于其他方法,D G P取得了非常高的P S N R和S S I M
 • 视觉上的重建误差几乎难以察觉
• 视觉上的重建误差几乎难以察觉
图像修复
图像上色
Colorization
• 上色任务是将 灰度图 转换为对应的 彩图
• 彩图 通过提取亮度 可以得到对应的 灰度图
• 将生成图像转换到 Lab色彩空间,取ab维度;L是亮度,a 和b是两个颜色通道
• 没有采用基于特定任务的训练,视觉效果仍优于或者可以与自动上色的方法比较
• 使用ResNet50上的分类精度作为定量评估结果, 下列方法的精度分别为 51.5%, 56.2%, 56.0%, 62.8%

图像补全
Inpainting
• Image inpainting 的目标是恢复缺失的像素点
• 相应的退化变换是是将原始图像乘以一个二进制mask ,即 φ(x) = x * m
• DGP的性能大大优于其他反演方法


超分辨率
Super-Resolution
• 使用 Lanczos下采样
• 相比DIP和SinGAN,DGP的超分结果更锐利和拟真
• 通过在最后一个finetune stage中调节不同loss间的比例,可以实现PSNR和主观感知质量间的trade off

灵活性
Flexibility
• 此外,DGP可以有更加灵活的应用,例如下图中的条件上色和混合修复
• 条件上色即在灰度空间重建时对生成器输入不同的类别条件,最终恢复的颜色会呈现出不同的效果
• 混合修复即同时进行多种图像修复任务,例如下图(b)中同时进行上色,补全,和超分辨率(两倍放大)

泛化性
Generalization
• 在非ImageNet的数据集上测试泛化性
• 构建了一个18张图片的小数据集,除了(b)来自Places数据集,其它图片抓取自互联网
• 图d中,需要恢复部分的信息(横梁,窗户)在周围仅出现了几次,而生成器就能在重建的过程中“学过来”,可见相比较DIP,DGP更好地建模了像素的空间关系、
随机扰动
Random Jittering
• 由于改进的GAN inversion实现了精确的重建,可以通过操纵隐向量来编辑目标图片
• 通过对隐向量z加随机高斯噪声,可以对目标图片实现随机扰动效果
• SinGAN 做随机扰动时会保持原有的纹理,但丢失了狗的结构信息

图像插值
Image Morphing
• 两张不同的输入,finetune后会得到两个不同的生成器
• 对两张重建图片得到的隐向量和生成器参数都进行插值,用插值得到的网络和隐向量进行生成,可以实现图像渐变效果
• 使用ImageNet验证集每个类别中的每一对相邻图像进行插值,插值系数λ = 0.5
• 1000个类别的50k图像,最终生成了49k个插值图像进行测试,DIP的IS得分为3.1,DGP为59.9

类别转换
Category Transfer
原文讲解
• 将生成器的输入类别改变,还可以实现对图中物体类别的转换
• 将狗和鸟上进行了实验
• 类别转换的同时,不改变姿态、大小和图像特征

论文总结
• 本文提出了一种挖掘GAN中图像先验的方式,在多个任务上揭示了GAN作为一种通用图像先验的潜力
• 首次将其应用于复杂图片的对抗防御
• 提出了同时插值隐变量和生成器的图像渐变方法
• 实验中DGP所展现出的强大的像素间空间关系模拟能力也十分有趣