Python入门篇之组合数据类型
简介
计算机不仅对单个变量表示的数据进行处理,更通常的情况是,计算机需要对一组 数据进行批量处理
例如:
(1) 给定一组单词 {python, data, function, list, loop},计算并输出每个单词的长度
(2) 给定一个学院的学生信息,统计男女生比例
(3) 一次实验产生了很多组数据,对这些大量数据进行分析
以单词统计问题为例,在计算一个单词长度之前,程序需要使用一个 变量表示这个单词,对于一组单词,需要很多个变量。有两个解决方案:
为每个单词分配一个变量,从变量命名上加以区分,例如,a01、 a02 分别存储第一个、第二个元素;或者采用一个数据结构存储这组数据,对每个元素采用索引加以区分,例如用 a 表示这组元素,那么a[0] 为该组第一个元素, a[1] 为第二个元素
两个方案哪个更好呢?
很显然,第二个方案更好。假定单词数量是 500 个而不是 5 个,使用第一种方法将是灾难。此外,对每个元素单独定义变量,不利于循环操作
我们学过数字类型,包括整数类型、浮点数类型和复数类型,这些类型仅能表示一个数据,这种表示单一数据的类型称为基本数据类型。 然而,实际计算中却存在大量同时处理多个数据的情况,这需要将多个数据有效组织起来并统一表示,这种能够表示多个数据的类型称为组合数据类型
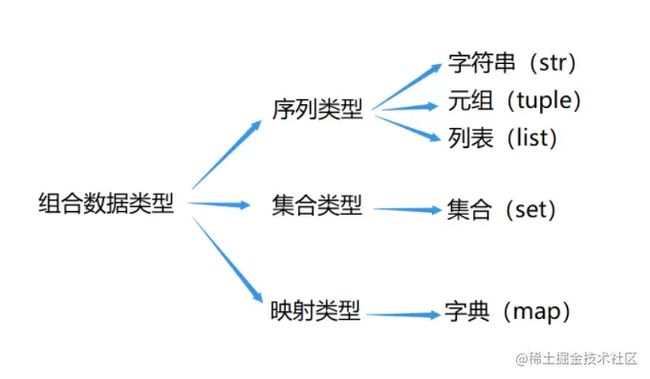
组合数据类型能够将多个同类型或不同类型的数据组织起来,通过单一的表示使数据操作更有序、更容易。根据数据之间的关系,组合数据类型可以分为 3 类:序列类型、集合类型和映射类型
序列类型是一个元素向量,元素之间存在先后关系,通过序号访问,元素之间不排它
集合类型是一个元素集合,元素之间无序,相同元素在集合中唯一存在
映射类型是 “键-值” 数据项的组合,每个元素是一个键值对 ,表示为 (key, value)。在 Python 中,每一类组合数据类型都对应一个或多个具体的数据类型
Python 支持的具体组合数据类型如下图所示:
序列类型
引入
序列类型是一维元素向量,元素之间存在先后关系,通过序号访问。序列的基本思想和表示方法均来源于数学概念。在数学中,经常给每个序列一个名字,例如,n 个数的序列 S,可以表示如下:
S = s0,s1,s2, ... ,sn-1
当需要访问序列中某个特定值时,只需要通过下标标出即可。例如,需要找到第 2 个元素,即可通过 s1 获得。这种采用集合名字和下标相结合的表示方法可以简洁地表示序列运算
由于元素之间存在顺序关系,所以序列中可以存在数值相同但位置不同的元素。序列类型支持成员关系操作符 (in)、 长度计算函数 (len())、 分片([]),元素本身也可以是序列类型
Python 语言中有很多数据类型都是序列类型,其中比较重要的是 str (字符串)、tuple (元组) 和 list (列表)。字符串 (str) 可以看成是单一字符的有序组合,属于序列类型。同时,由于字符串类型十分常用且单一字符串只表达一个含义,也被看作是基本数据类型。元组是包含 0 个或多个数据项的不可变序列类型。元组生成后是固定的,其中任何数据项不能替换或删除。列表则是一 个可以修改数据项的序列类型,使用也最灵活。无论哪种具体数据类型,只要它是序列类型,都可以使用相同的索引体系,即正向递增序号和反向递减序号,如下图所示

操作符和函数
序列类型有 12 个通用的操作符和函数,如下表所示:
| 操作符 | 描述 |
|---|---|
| x in s | 如果 x 是 s 的元素,返回 True,否则返回 False |
| x not in s | 如果 x 不是 s 的元素,返回 True,否则返回 False |
| s + t | 连接 s 和 t |
| s * n或 n * s | 将序列 s 复制 n 次 |
| s[i] | 索引,返回序列的第 i 个元素 |
| s[i:j] | 分片,返回包含序列 s 第 i 到 j 个元素的子序列(不包含第 j 个元素) |
| s[i:j: k] | 步骤分片,返回包含序列 s 第 i 到 j 个元素以 k 为间隔的子序列 |
| len(s) | 序列 s 的元素个数 (长度) |
| min(s) | 序列 s 中的最小元素 |
| max(s) | 序列 s 中的最大元素 |
| s.index(x[, i[, j]) | 序列 s 中从 i 开始到 j 位置中第一次出现元素 x 的位置 |
| s.count(x) | 序列 s 中出现 x 的总次数 |
元组
元组 (tuple) 是序列类型中比较特殊的类型,因为它一旦创建就不能被修改。元组类型在表达固定数据项、函数多返回值、多变量同步赋值、循环遍历等情况下十分有用。Python 中元组采用逗号和圆括号 (可选) 来表示,例如:
creature = "cat", "dog", "tiger", "human"
print(type(creature))
print(creature)
print(creature[2])
print("human" in creature)
color = ("red",0x001100,"blue",creature)
print(type(color))
print(color)
print(color[-1][2])
我们分别来看它们各个语句的效果:
creature = "cat", "dog", "tiger", "human"
print(type(creature))
print(creature)
print(creature[2])
('cat', 'dog', 'tiger', 'human') tiger
print("human" in creature)
True
color = ("red",0x001100,"blue",creature)
print(type(color))
print(color)
('red', 4352, 'blue', ('cat', 'dog', 'tiger', 'human'))
print(color[-1][2]) # 获取从右边开始数第 2 个元素
tiger
生成元组只需要使用逗号将元素隔离开即可,例如上例中的元组 creature,也可以增加圆括号,但圆括号在不混淆语义的情况下不是必需的。一个元组可以作为另一个元组的元素,可以采用多级索引获取信息,例如元组 color 中包含了元组 creature,可以用 color[-1][2] 获取对应元素值。元组除了用于表达固定数据项外,还常用于如下 3 种情况:函数多返回值、多变量同步赋值、循环遍历,例如:
def func(x): # 函数多返回值
return x, x ** 3
a, b = 'dog', 'tiger' # 多变量同步赋值
a, b = (b, a) # 多变量同步赋值,括号可省略
import math
for x, y in ((1, 0), (2, 5), (3, 8)): # 循环遍历
print(math.hypot(x, y)) # 求多个坐标点到原点的距离
集合类型
引入
集合类型与数学中集合的概念一致, 即包含 0 个或多个数据项的无序组合。集合中的元素不可重复,元素类型只能是固定数据类型,例如整数、浮点数、字符串、元组等,列表、字典和集合类型本身都是可变数据类型,不能作为集合的元素出现。Python 编译器中界定固定数据类型与否主要考察类型是否能够进行哈希运算。能够进行哈希运算的类型都可以作为集合元素。Python 提供了一种同名的具体数据类型集合 (set)
哈希运算
哈希运算可以将任意长度的二进制值映射为较短的固定长度的二进制值,这、个小的二进制值称为哈希值。哈希值是对数据的一种有损且紧凑的表示形式。Python 提供了一个内置的哈希运算函数 hash(),它可以对大多数数据类型产生一个哈希值,例如:
print(hash("PYTHON"))
-6820142343965525986
print(hash("IS"))
-7939342035718960313
print(hash("GOOD"))
8183822834223513593
print(hash("PYTHON IS GOOD"))
-8579536417096181466
这些哈希值与哈希前的内容无关,也和这些内容的组合无关。可以说,哈希是数据在另一个数据维度的体现
由于集合是无序组合,它没有索引和位置的概念,不能分片,集合中元素可以动态增加或删除。集合用大括号({}) 表示,可以用赋值语句生成一个集合,例如:
S = {425, "BIT", (10, "ABC"), 424}
print(S)
{424, 425, 'BIT', (10, 'ABC')}
T = {425, "BIT", (10, "ABC"), 424, 425, "BIT"}
print(T)
{424, 425, 'BIT', (10, 'ABC')}
是的,你没有眼花
从上例可以看到,由于集合元素是无序的,集合的打印效果与定义顺序可以不一致。由于集合元素独一无二,使用集合类型能够过滤掉重复元素
set(x) 函数可以用于生成集合,输入的参数可以是任何组合数据类型,返回结果是一个无重复且排序任意的集合,例如:
W = set("apple")
print(W)
{'e', 'l', 'a', 'p'}
V = set(("cat", "dog", "tiger", "human"))
print(V)
{'cat', 'dog', 'tiger', 'human'}
注意:集合每次打印出来的顺序都是任意的
集合类型的操作符
集合类型有 10 个操作符,如下表所示:
| 操作符 | 描述 |
|---|---|
| S - T 或 S.difference(T) | 返回一个新集合,包括在集合 S 中但不在集合 T 中的元素 |
| S-=T 或 S.difference_update(T) | 更新集合 S,包括在集合 S 中但不在集合 T 中的元素 |
| S & T 或 S.intersection(T) | 返回一个新集合,包括同时在集合 S 和 T 中的元素 |
| S&=T 或 S.intersection_update(T) | 更新集合 S,包括同时在集合 S 和 T 中的元素 |
| S^T 或 s.symmetric difference(T) | 返回一个新集合,包括集合 S 和 T 中的元素,但不包括同时在其中的元素 |
| S^=T 或 s.symmetric_ difference update(T) | 更新集合 S,包括集合 S 和 T 中的元素,但不包括同时在其中的元素 |
| S | T 或 S.union(T) | 返回一个新集合,包括集合 S 和 T 中的所有元素 |
| S|=T 或 S.update(T) | 更新集合 S,包括集合 S 和 T 中的所有元素 |
| S<=T 或 S.issubset(T) | 如果 S 与 T 相同或 S 是 T 的子集,返回 True,否则返回 False,可以用 S |
| S>=T 或 S.issuperset(T) | 如果 S 与 T 相同或 S 是 T 的超集,返回 True,否则返回 False,可以用 S>T 判断 S 是否是 T 的真超集 |
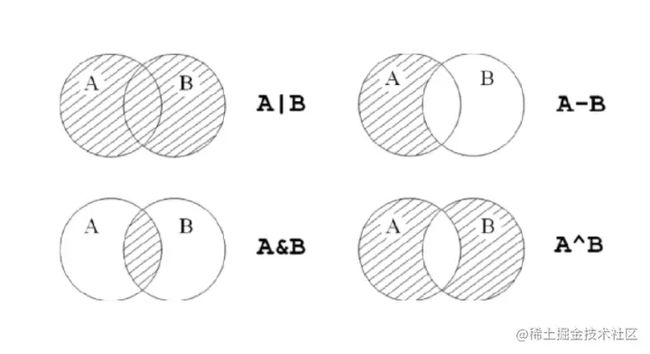
上述操作符表达了集合类型的 4 种基本操作:交集(&)、并集(|)、差集(-)、补集(^),操作逻辑与数学定义相同,如下图所示:
操作函数
集合类型有 10 个操作函数或方法,如下表所示:
| 操作函数或方法 | 描述 |
|---|---|
| S.add(x) | 如果数据项 x 不在集合 S 中,将 x 增加到 s |
| S.clear() | 移除 S 中的所有数据项 |
| S.copy() | 返回集合 S 的一个副本 |
| S.pop() | 随机返回集合 S 中的一个元素,如果 S 为空,产生 KeyError 异常 |
| S.discard(x) | 如果 x 在集合 S 中,移除该元素;如果 x 不在集合 S 中,不报错 |
| S.remove(x) | 如果 x 在集合 S 中,移除该元素;不在则产生 KeyError 异常 |
| S.isdisjoint(T) | 如果集合 S 与 T 没有相同元素,返回 True |
| len(S) | 返回集合 S 的元素个数 |
| x in S | 如果 x 是 S 的元素,返回 True,否则返回 False |
| x not in S | 如果 x 不是 S 的元素,返回 True,否则返回 False |
具体应用
集合类型主要用于 3 个场景:成员关系测试、元素去重和删除数据项,例如:
print("BIT" in {"PYTHON","BIT",123,"GOOD"}) #成员关系测试
True
tup = {"PYTHON","BIT",123,"GOOD",123} #元素去重
print(set(tup))
{'BIT', 'GOOD', 123, 'PYTHON'}
tup = {"PYTHON","BIT",123,"GOOD",123}
newtup = tuple(set(tup) - {"PYTHON"}) #去重同时删除数据项
print(newtup)
('BIT', 'GOOD', 123)
集合类型与其他类型最大的不同在于它不包含重复元素,因此,当需要对一维数据进行去重或进行数据重复处理时,一般通过集合来完成
映射类型
映射类型是 “键值” 数据项的组合,每个元素是一个键值对, 即元素是 (key,value),元素之间是无序的。键值对 (key, value) 是一种二元关系, 源于属性和值的映射关系,对应实例如下图所示:
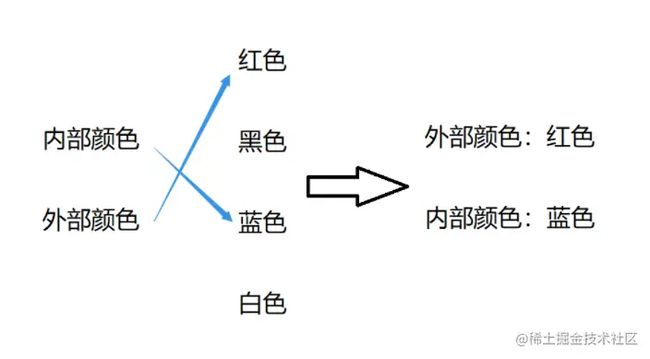
键 (key) 表示一个属性,也可以理解为一个类别或项目,值 (value) 是属性的内容,键值对刻画了一个属性和它的值。 键值对将映射关系结构化,用于存储和表达。在 Python 中,映射类型主要以字典 (dict) 体现