PyTorch-C++前端
PyTorch-C++前端
1、LibTorch与VS2017社区版配置
安装libtorch需要与自身pytorch版本以及CUDA版本对应,输入win+r打开终端输入以下命令依次检查对应版本。
pip list #查看pytorch版本
nvcc -V #查看CUDA版本

本机torch和CUDA版本分别为1.9.0和10.2,因此需要去官网下载对应版本的各个版本CUDA和各个版本CUDNN。
1.1、下载libtorch
libtorch主要用来部署pytorch的模型,是最近流行的C++部署框架。在Linux、Mac、Windows上都有对应的版本下载。同时也有release版本和debug版本,目前官网只提供最新的1.9.0版本。
Windows下各个版本下载
| LibTorch-Version | release-cpu | release-gpu | debug-cpu | debug-gpu |
|---|---|---|---|---|
| 1.0.0 | 1.0.0-CPU | 1.0.0-CUDA-80 1.0.0-CUDA-90 1.0.0-CUDA-100 |
失效 | 失效 |
| 1.0.1 | 1.0.1-CPU | 1.0.1-CUDA-80 1.0.1-CUDA-90 1.0.1-CUDA-100 |
失效 | 失效 |
| 1.1.0 | 1.1.0-CPU | 1.1.0-CUDA-90 1.1.0-CUDA-100 |
1.1.0-CPU | 1.1.0-CUDA-90 1.1.0-CUDA-100 |
| 1.2.0 | 1.2.0-CPU | 1.2.0-CUDA-92 1.2.0-CUDA-100 |
1.2.0-CPU | 1.2.0-CUDA-92 1.2.0-CUDA-100 |
| 1.3.0 | 1.3.0-CPU | 1.3.0-CUDA-92 1.3.0-CUDA-101 |
1.3.0-CPU | 1.3.0-CUDA-92 1.3.0-CUDA101 |
| 1.3.1 | 1.3.1-CPU | 1.3.1-CUDA-92 1.3.1-CUDA-101 |
1.3.1-CPU | 1.3.1-CUDA-92 1.3.1-CUDA-101 |
| 1.4.0 | 1.4.0-CPU | 1.4.0-CUDA-92 1.4.0-CUDA-101 |
1.3.1-CPU | 1.3.1-CUDA-92 1.3.1-CUDA-101 |
| 1.5.0 | 1.5.0-CPU | 1.5.0-CUDA-92 1.5.0-CUDA-101 1.5.0-CUDA-102 |
1.5.0-CPU | 1.5.0-CUDA-92 1.5.0-CUDA-101 1.5.0-CUDA-102 |
| 1.6.0 | 1.6.0-CPU | 1.6.0-CUDA-101 1.6.0-CUDA-102 |
1.6.0-CPU | 1.6.0-CUDA-101 1.6.0-CUDA-102 |
| 1.7.0 | 1.7.0-CPU | 1.7.0-CUDA-101 1.7.0-CUDA-102 1.7.0-CUDA-110 |
1.7.0-CPU | 1.7.0-CUDA-101 1.7.0-CUDA-102 1.7.0-CUDA-110 |
| 1.7.1 | 1.7.1-CPU | 1.7.1-CUDA-101 1.7.1-CUDA-102 1.7.1-CUDA-110 |
1.7.1-CPU | 1.7.1-CUDA-101 1.7.1-CUDA-102 1.7.1-CUDA-110 |
| 1.8.0 | 1.8.0-CPU | 1.8.0-CUDA-102 1.8.0-CUDA-111 |
1.8.0-CPU | 1.8.0-CUDA-102 1.8.0-CUDA-111 |
| 1.8.1(LTS) | 1.8.1(LTS)-CPU | 1.8.1(LTS)-CUDA-102 1.8.1(LTS)-CUDA-111 |
1.8.1(LTS)-CPU | 1.8.1(LTS)-CUDA-102 1.8.1(LTS)-CUDA-111 |
| 1.9.0 | 1.9.0-CPU | 1.9.0-CUDA-102 1.9.0-CUDA-111 |
1.9.0-CPU | 1.9.0-CUDA-102 1.9.0-CUDA-111 |
同时还有Ubuntu各个版本,后期补充。
下载与torch对应版本的libtorch后解压缩。将其放在任意位置,我的是放C盘下。
配置libtorch的环境变量。

1.2、配置libtorch和VS2017社区版
新建C++工程文件,根据自己的情况修改第三个步骤

新建完成后默认是x86的,需要改为X64的,因为libtorch是x64的,不支持32位的。我下载是release版本的,所以还要改为release模式。
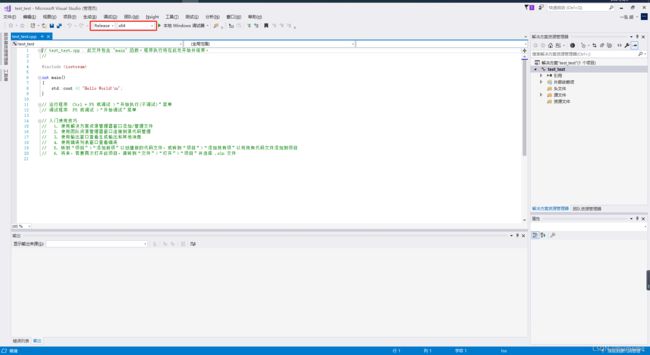
然后右键test_test项目,选择属性,配置libtorch环境

选择配置属性->调试->环境输入:
PATH=C:\libtorch\lib;%PATH%

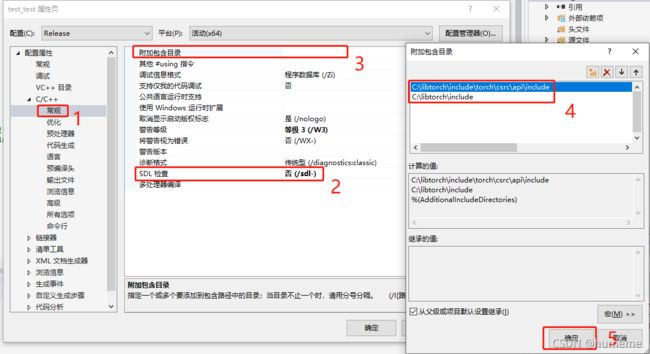
选择配置属性->C/C++ ->常规:将SDL检查设为否,将以下内容输入附加包含目录:
C:\libtorch\include
C:\libtorch\include\torch\csrc\api\include
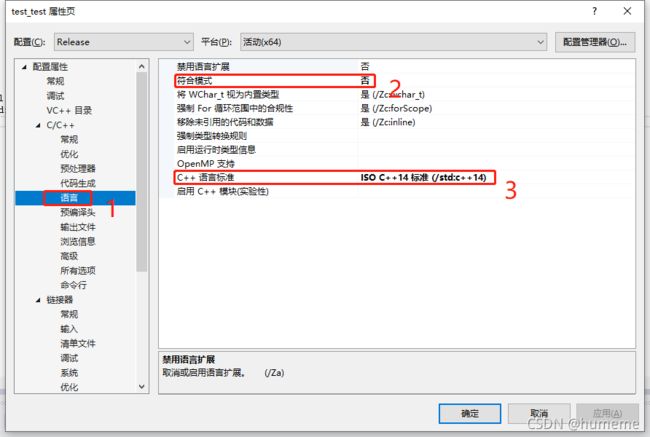
选择配置属性->C/C++ ->语言:将符合模式设为否,将C++语言标准设为C++14。
选择配置属性->链接器 ->常规:将以下内容添加到附加库目录:
C:\libtorch\lib

选择配置属性->链接器 ->输入:将以下内容添加到附加库目录:
asmjit.lib
c10.lib
c10_cuda.lib
c10d.lib
caffe2_detectron_ops_gpu.lib
caffe2_module_test_dynamic.lib
caffe2_nvrtc.lib
Caffe2_perfkernels_avx.lib
Caffe2_perfkernels_avx2.lib
Caffe2_perfkernels_avx512.lib
clog.lib
cpuinfo.lib
dnnl.lib
fbgemm.lib
fbjni.lib
kineto.lib
libprotobuf.lib
libprotobuf-lite.lib
libprotoc.lib
mkldnn.lib
pthreadpool.lib
pytorch_jni.lib
torch.lib
torch_cpu.lib
torch_cuda.lib
XNNPACK.lib

此处的内容根据各个libtorch版本的不同而有所改变,这里的是libtorch-1.9.0的。
输入以下内容测试是否调用到CUDA:
#include
#include
using namespace std;
int main() {
torch::Tensor tensor = torch::rand({ 5,3 });
std::cout << tensor << std::endl;
std::cout << torch::cuda::is_available() << std::endl; // 测试CUDA是否可用
std::cout << torch::cuda::cudnn_is_available() << std::endl; // 测试CUDNN是否可用
}
显示如下:

如果没有正确调用CUDA将会显示为0。此时选择配置属性->链接器 ->输入,加入以下内容:
/INCLUDE:?searchsorted_cuda@native@at@@YA?AVTensor@2@AEBV32@0_N1@Z
/INCLUDE:?warp_size@cuda@at@@YAHXZ

点击调试->开始执行或者F5,显示为1则表示调用CUDA成功:

至此,libtorch配置VS2017完毕,另一个debug或者cmake形式的尚未研究(待补充)
2、PyTorch-C++前端新手入门
PyTorch-C++前端建立深度学习模型是完全基于C++语言重构网络结构并进行训练保存模型。这是一套全新的可用的C++的API。先宏观的感受下C++版的模型构建。
利用原生的python代码实现这样一个模型,如下:
import torch
class Net(torch.nn.Module):
def __init__(self, N, M):
super(Net, self).__init__()
self.W = torch.nn.Parameter(torch.randn(N, M))
self.b = torch.nn.Parameter(torch.randn(M))
def forward(self, input):
return torch.addmm(self.b, input, self.W)
现在C++实现的形式如下:
#include
struct Net : torch::nn::Module {
Net(int64_t N, int64_t M) {
W = register_parameter("W", torch::randn({N, M}));
b = register_parameter("b", torch::randn(M));
}
torch::Tensor forward(torch::Tensor input) {
return torch::addmm(b, input, W);
}
torch::Tensor W, b;
};
2.1、基于libtorch的LeNet5网络代码实现
按照上述步骤创建工程并配置好libtorch后
(1)输入相关的头文件,并定义相关参数
配置好libtorch后,导入torch相关的头文件,C++定义的网络结构函数都在头文件中有定义。
#include
#include
#include
#include
#include
#include
// Where to find the MNIST dataset.
const char* kDataroot = "D:/C_Plus/LeNet_Mnist/data";
// The batch size for training.
const int64_t kTrainBatchSize = 32;
// The number of epochs to train.
const int64_t kNumberOfEpochs = 10;
// After how many batches to log a new update with the loss value.
const int64_t kLogInterval = 10;
// After how many batches to create a new checkpoint periodically.
const int64_t kCheckpointEvery = 200;
(2)定义LeNet5网络结构

第一层卷积输入通道为 3,输出通道为 6,size = 5,stride = 1,padding = 0,最大池化size = 2,stride = 2。
第二层卷积输入通道为 6,输出通道为 16,size = 5,stride = 1,padding = 0 ,最大池化size = 2,stride = 2。
Flatten(16 * 4 * 4);(这里4和图中5,是因为取整的方式不同导致)
第三层全连接输入通道为256(16 * 4 * 4),输出通道为120。
第四层全连接输入通道为120,输出通道为84。
由于MNIST数据集是单通道图像,因此LeNet5网络的输入通道为1,这里将flatten层进行改动。
此处代码的书写风格暂时只可意会不可言传,因此不做代码编程思路介绍
// 创建网络
struct LeNet5 : torch::nn::Module {
LeNet5()
: conv1(torch::nn::Conv2dOptions(1, 6, 5)
.stride(1)
.padding(2)),// 1 * 28 * 28 -> 6 * 28 * 28 -> 6 * 14 * 14
conv2(torch::nn::Conv2dOptions(6, 16, 5)
.stride(1)
.padding(0)),// 6 * 14 * 14 -> 16 * 10 * 10 -> 16 * 5 * 5
conv3(torch::nn::Conv2dOptions(16, 120, 5)
.stride(1)
.padding(0)),// 16 * 5 * 5 -> 120 * 1 * 1 (不需要池化)
fc1(120,84),
fc2(84,10)
//注册需要学习的模块
{
register_module("conv1", conv1);
register_module("conv2", conv2);
register_module("conv3", conv3);
register_module("fc1", fc1);
register_module("fc2", fc2);
}
torch::Tensor forward(torch::Tensor x) {
//conv1
x = torch::relu(torch::max_pool2d(conv1->forward(x),2));
//conv2
x = torch::relu(torch::max_pool2d(conv2->forward(x), 2));
//conv3
x = torch::relu(conv3->forward(x));
//数据格式转换
x = x.view({ -1,120 });
//全连接层
//fc1
x = torch::relu(fc1->forward(x));
//fc2
x = fc2->forward(x);
return torch::log_softmax(x, 1);
};
torch::nn::Conv2d conv1, conv2,conv3;
torch::nn::Linear fc1, fc2;
};
(3)数据集定义及加载
此处读取数据集的形式只是其中的一种,还有其他的形式,也支持自定义操作,待后续深入研究后完善
//加载数据集并进行批处理
//训练集
auto train_datasets = torch::data::datasets::MNIST(kDataroot, torch::data::datasets::MNIST::Mode::kTrain)
.map(torch::data::transforms::Normalize<>(0.1307, 0.3081))
.map(torch::data::transforms::Stack<>());
const size_t train_dataset_size = train_datasets.size().value();
auto train_dataloader = torch::data::make_data_loader(
std::move(train_datasets), kTrainBatchSize);
//测试集
auto test_datasets = torch::data::datasets::MNIST(kDataroot, torch::data::datasets::MNIST::Mode::kTest)
.map(torch::data::transforms::Normalize<>(0.1207, 0.3081))
.map(torch::data::transforms::Stack<>());
const size_t test_dataset_size = test_datasets.size().value();
auto test_dataloader = torch::data::make_data_loader(
std::move(test_datasets), kTrainBatchSize);
(4)定义训练函数
训练函数的结构类似于PyTorch结构,将模型调为训练模式,循环读取dataloader,对数据进行训练。
//定义训练函数
template
void train(
size_t epoch,
LeNet5& model,
torch::Device device,
DataLoader& data_loader,
torch::optim::Optimizer& optimizer,
size_t dataset_size
) {
model.train();
size_t batch_idx = 0;
for (auto& batch : data_loader) {
auto data = batch.data.to(device);
auto label = batch.target.to(device);
optimizer.zero_grad();
auto output = model.forward(data);
auto loss = torch::nll_loss(output, label);
AT_ASSERT(!std::isnan(loss.template item()));
loss.backward();
optimizer.step();
batch_idx++;
if (batch_idx % kLogInterval == 0) {
std::printf(
"\rTrain Epoch: %ld [%5ld/%5ld] Loss: %.4f",
epoch,
batch_idx * batch.data.size(0),
dataset_size,
loss.template item());
}
}
}
(5)定义测试函数
测试函数不再多阐述,跟PyTorch结构类似。
template
void test(
LeNet5& model,
torch::Device device,
DataLoader& data_loader,
size_t dataset_size) {
torch::NoGradGuard no_grad;
model.eval();
double test_loss = 0;
int32_t correct = 0;
for (const auto& batch : data_loader) {
auto data = batch.data.to(device), targets = batch.target.to(device);
auto output = model.forward(data);
test_loss += torch::nll_loss(
output,
targets,
/*weight=*/{},
torch::Reduction::Sum)
.template item();
auto pred = output.argmax(1);
correct += pred.eq(targets).sum().template item();
}
test_loss /= dataset_size;
std::printf(
"\nTest set: Average loss: %.4f | Accuracy: %.3f\n",
test_loss,
static_cast(correct) / dataset_size);
}
(6)定义主函数
训练步骤也跟PyTorch的结构类似,调用GPU/CPU---->定义数据集函数---->定义优化器---->定义训练函数---->定义测试函数---->保存模型。
auto main(int argc, const char** argv) ->int{
torch::manual_seed(1);
//查询CUDA是否有用。否则在CPU上运行
torch::DeviceType device_type;
if (torch::cuda::is_available) {
std::cout << "CUDA is available,Training on GPU" << std::endl;
device_type = torch::kCUDA;
}
else {
std::cout << "Training on CPU" << std::endl;
device_type = torch::kCPU;
}
torch::Device device(device_type);
LeNet5 model;
//auto model = std::make_shared();
model.to(device);
//加载数据集并进行批处理
//训练集
auto train_datasets = torch::data::datasets::MNIST(kDataroot, torch::data::datasets::MNIST::Mode::kTrain)
.map(torch::data::transforms::Normalize<>(0.1307, 0.3081))
.map(torch::data::transforms::Stack<>());
const size_t train_dataset_size = train_datasets.size().value();
auto train_dataloader = torch::data::make_data_loader(
std::move(train_datasets), kTrainBatchSize);//此处有疑点,须后期认真研究
//测试集
auto test_datasets = torch::data::datasets::MNIST(kDataroot, torch::data::datasets::MNIST::Mode::kTest)
.map(torch::data::transforms::Normalize<>(0.1207, 0.3081))
.map(torch::data::transforms::Stack<>());
const size_t test_dataset_size = test_datasets.size().value();
auto test_dataloader = torch::data::make_data_loader(
std::move(test_datasets), kTrainBatchSize);
//优化器
torch::optim::SGD optimizer(model.parameters(), torch::optim::SGDOptions(0.01).momentum(0.5));
//开始训练
for (size_t epoch = 1; epoch <= kNumberOfEpochs; ++epoch) {
train(epoch, model, device, *train_dataloader, optimizer, train_dataset_size);
test(model, device, *test_dataloader, test_dataset_size);
}
printf("Finish training!\n");
torch::serialize::OutputArchive archive;
model.save(archive);
archive.save_to("mnist.pt"); //保存训练好的模型到文件,方便下次使用
printf("Save the training result to mnist.pt.\n");
}
完整训练代码:
#include
#include
#include
#include
#include
#include
// Where to find the MNIST dataset.
const char* kDataroot = "D:/C_Plus/LeNet_Mnist/data";
// The batch size for training.
const int64_t kTrainBatchSize = 32;
// The number of epochs to train.
const int64_t kNumberOfEpochs = 10;
// After how many batches to log a new update with the loss value.
const int64_t kLogInterval = 10;
// After how many batches to create a new checkpoint periodically.
const int64_t kCheckpointEvery = 200;
// 创建网络
struct LeNet5 : torch::nn::Module {
LeNet5()
: conv1(torch::nn::Conv2dOptions(1, 6, 5)
.stride(1)
.padding(2)),// 1 * 28 * 28 -> 6 * 28 * 28 -> 6 * 14 * 14
conv2(torch::nn::Conv2dOptions(6, 16, 5)
.stride(1)
.padding(0)),// 6 * 14 * 14 -> 16 * 10 * 10 -> 16 * 5 * 5
conv3(torch::nn::Conv2dOptions(16, 120, 5)
.stride(1)
.padding(0)),// 16 * 5 * 5 -> 120 * 1 * 1 (不需要池化)
fc1(120,84),
fc2(84,10)
//注册需要学习的模块
{
register_module("conv1", conv1);
register_module("conv2", conv2);
register_module("conv3", conv3);
register_module("fc1", fc1);
register_module("fc2", fc2);
}
torch::Tensor forward(torch::Tensor x) {
//conv1
x = torch::relu(torch::max_pool2d(conv1->forward(x),2));
//conv2
x = torch::relu(torch::max_pool2d(conv2->forward(x), 2));
//conv3
x = torch::relu(conv3->forward(x));
//数据格式转换
x = x.view({ -1,120 });
//全连接层
//fc1
x = torch::relu(fc1->forward(x));
//fc2
x = fc2->forward(x);
return torch::log_softmax(x, 1);
};
torch::nn::Conv2d conv1, conv2,conv3;
torch::nn::Linear fc1, fc2;
};
//定义训练函数
template
void train(
size_t epoch,
LeNet5& model,
torch::Device device,
DataLoader& data_loader,
torch::optim::Optimizer& optimizer,
size_t dataset_size
) {
model.train();
size_t batch_idx = 0;
for (auto& batch : data_loader) {
auto data = batch.data.to(device);
auto label = batch.target.to(device);
optimizer.zero_grad();
auto output = model.forward(data);
auto loss = torch::nll_loss(output, label);
AT_ASSERT(!std::isnan(loss.template item()));
loss.backward();
optimizer.step();
batch_idx++;
if (batch_idx % kLogInterval == 0) {
std::printf(
"\rTrain Epoch: %ld [%5ld/%5ld] Loss: %.4f",
epoch,
batch_idx * batch.data.size(0),
dataset_size,
loss.template item());
}
}
}
template
void test(
LeNet5& model,
torch::Device device,
DataLoader& data_loader,
size_t dataset_size) {
torch::NoGradGuard no_grad;
model.eval();
double test_loss = 0;
int32_t correct = 0;
for (const auto& batch : data_loader) {
auto data = batch.data.to(device), targets = batch.target.to(device);
auto output = model.forward(data);
test_loss += torch::nll_loss(
output,
targets,
/*weight=*/{},
torch::Reduction::Sum)
.template item();
auto pred = output.argmax(1);
correct += pred.eq(targets).sum().template item();
}
test_loss /= dataset_size;
std::printf(
"\nTest set: Average loss: %.4f | Accuracy: %.3f\n",
test_loss,
static_cast(correct) / dataset_size);
}
auto main(int argc, const char** argv) ->int{
torch::manual_seed(1);
//查询CUDA是否有用。否则在CPU上运行
torch::DeviceType device_type;
if (torch::cuda::is_available) {
std::cout << "CUDA is available,Training on GPU" << std::endl;
device_type = torch::kCUDA;
}
else {
std::cout << "Training on CPU" << std::endl;
device_type = torch::kCPU;
}
torch::Device device(device_type);
LeNet5 model;
//auto model = std::make_shared();
model.to(device);
//加载数据集并进行批处理
//训练集
auto train_datasets = torch::data::datasets::MNIST(kDataroot, torch::data::datasets::MNIST::Mode::kTrain)
.map(torch::data::transforms::Normalize<>(0.1307, 0.3081))
.map(torch::data::transforms::Stack<>());
const size_t train_dataset_size = train_datasets.size().value();
auto train_dataloader = torch::data::make_data_loader(
std::move(train_datasets), kTrainBatchSize);//此处有疑点,须后期认真研究
//测试集
auto test_datasets = torch::data::datasets::MNIST(kDataroot, torch::data::datasets::MNIST::Mode::kTest)
.map(torch::data::transforms::Normalize<>(0.1207, 0.3081))
.map(torch::data::transforms::Stack<>());
const size_t test_dataset_size = test_datasets.size().value();
auto test_dataloader = torch::data::make_data_loader(
std::move(test_datasets), kTrainBatchSize);
//优化器
torch::optim::SGD optimizer(model.parameters(), torch::optim::SGDOptions(0.01).momentum(0.5));
//开始训练
for (size_t epoch = 1; epoch <= kNumberOfEpochs; ++epoch) {
train(epoch, model, device, *train_dataloader, optimizer, train_dataset_size);
test(model, device, *test_dataloader, test_dataset_size);
}
printf("Finish training!\n");
torch::serialize::OutputArchive archive;
model.save(archive);
archive.save_to("mnist.pt"); //保存训练好的模型到文件,方便下次使用
printf("Save the training result to mnist.pt.\n");
}
(7)模型推理
择良日完善!!!!