论文阅读笔记--3D human pose estimation in video with temporal convolutions and semi-supervised training -1
前言
读了一篇利用视频做姿态估计的比较经典的论文, 3D human pose estimation in video with temporal convolutions and semi-supervised training.
论文地址: https://arxiv.org/pdf/1811.11742.pdf
CVPR 2019收录论文

简单对论文的内容做一些自己的学习笔记, 然后再补充对于论文项目代码的笔记.
基于Video实现单目3D HPE(Human Pose Estimation 人体姿态估计), 核心思想在于利用空洞卷积在多帧图像上做时序卷积, 充分利用视频中包含的时序信息+2D RGB 图像实现3D HPE.
性能数据:
| 2D Detections | BBoxes | Blocks | Receptive Field | Error (P1) | Error (P2) |
|---|---|---|---|---|---|
| CPN | Mask R-CNN | 4 | 243 frames | 46.8 mm | 36.5 mm |
| CPN | Ground truth | 4 | 243 frames | 47.1 mm | 36.8 mm |
| CPN | Ground truth | 3 | 81 frames | 47.7 mm | 37.2 mm |
| CPN | Ground truth | 2 | 27 frames | 48.8 mm | 38.0 mm |
| Mask R-CNN | Mask R-CNN | 4 | 243 frames | 51.6 mm | 40.3 mm |
| Ground truth | – | 4 | 243 frames | 37.2 mm | 27.2 mm |
1.简介
利用几乎完全由卷积层构成的神经网络, 将2D pose转换为3D pose 这一问题非常有意思, 由于3D比2D多一维, 2D Pose 投影到3D 必然存在多解性, 即一组2D pose可以对应到多种3D pose的情况, 那么如何充分利用视频这一带有时间信息的数据作为维度上的补充就显得非常重要了.
这篇论文主要贡献:
-
利用空洞卷积在时间纬度上做卷积运算, 提取前后帧信息, 用于辅助将2D joints(骨骼关键点)转换为3D joints(骨骼关键点), 最后直接输出3D 坐标而非 heatmap. 这在以往是利用RNN, LSTM等自然语言处理的常用方法.
-
提出back-projection , 可以用于未标注数据的半监督学习模块,一定程度上能缓解3D HPE训练过程中数据量不足的问题. 从2D到3D,再到2D, 3D到2D只要投影角度等参数固定, 解唯一, 那么就可以利用这个来实现半监督学习.
1.1 利用空洞卷积在时间纬度上提取信息
一想到时序信息,我们常将其想到NLP的经典方法, RNNs, LSTM , GRU等等. 其实在机器翻译, 语言建模, 对话生成等传统的NLP领域, CNNs也早就大放异彩了.
RNN等架构有一个比较明显的缺点, 即在时间唯独上处理时只能串行处理视频帧而不能并行处理, 这限制了处理的速度, 而空洞卷积因其结构的特点, 每次提取信息时都是多张一起读入, 因为空洞卷积是把多个视频帧当成了一个sample, 在时间纬度上直接提取信息.
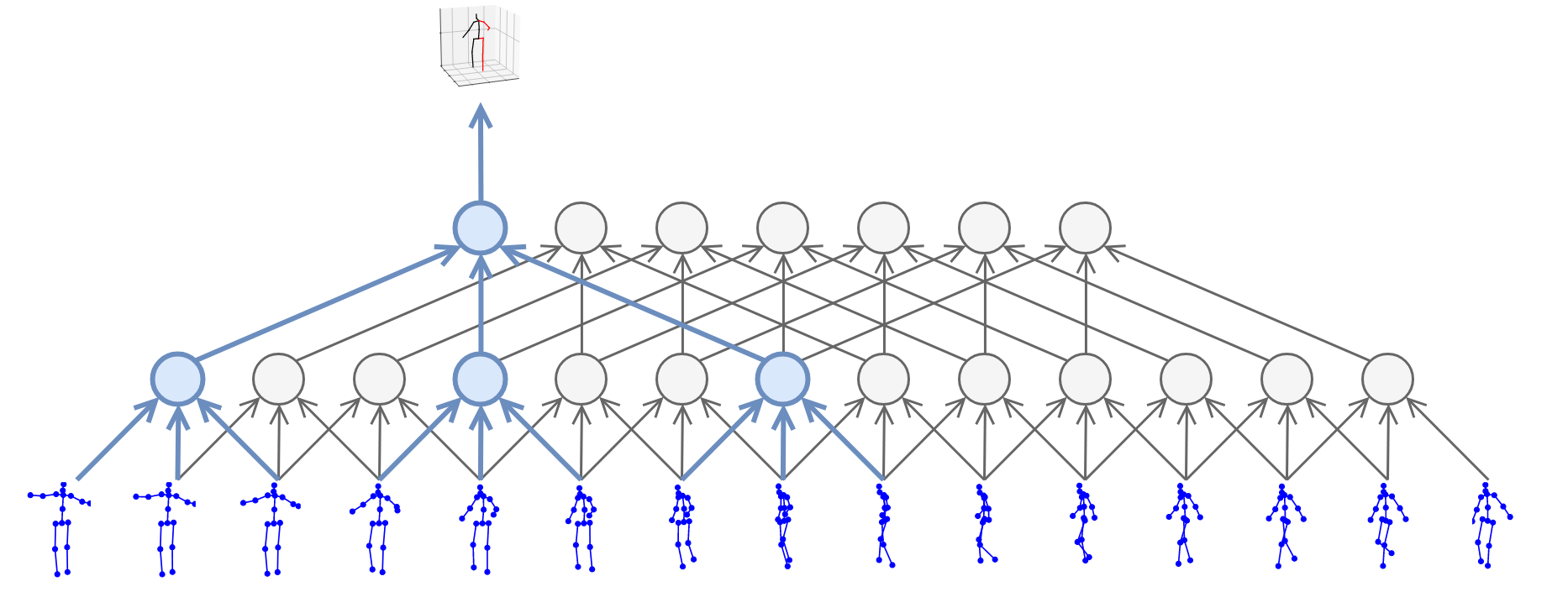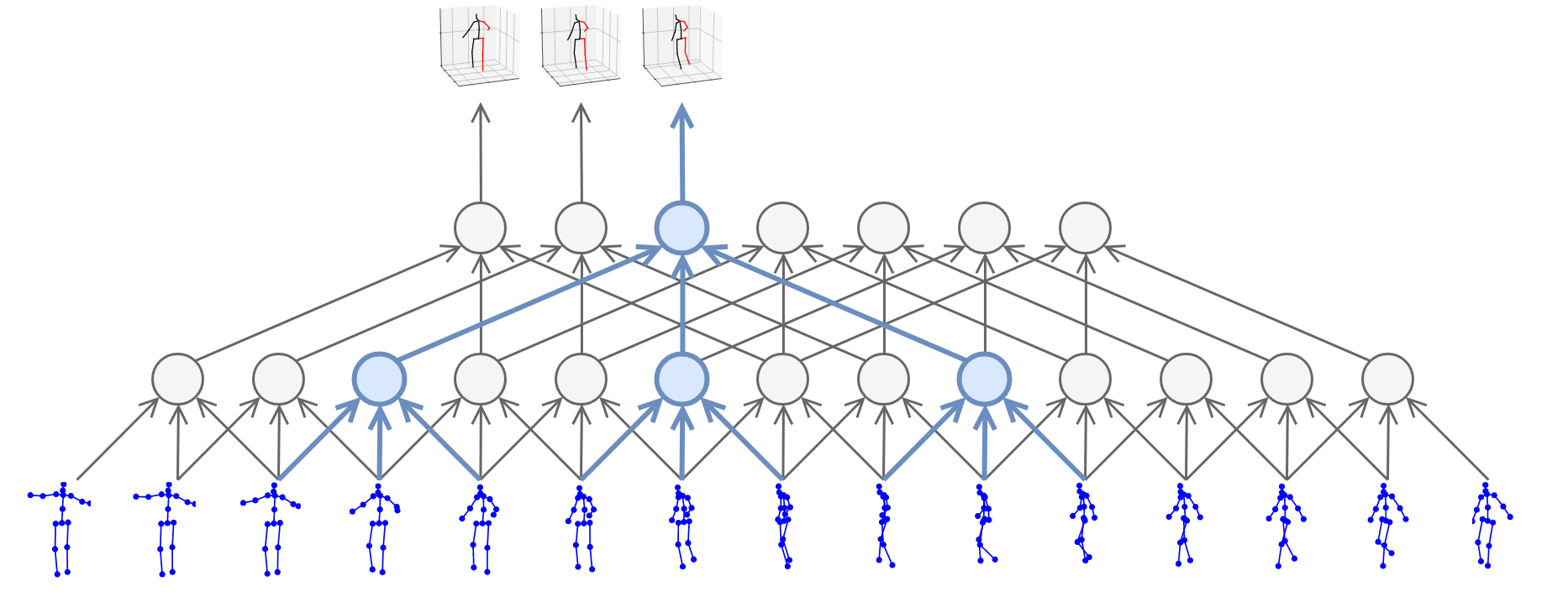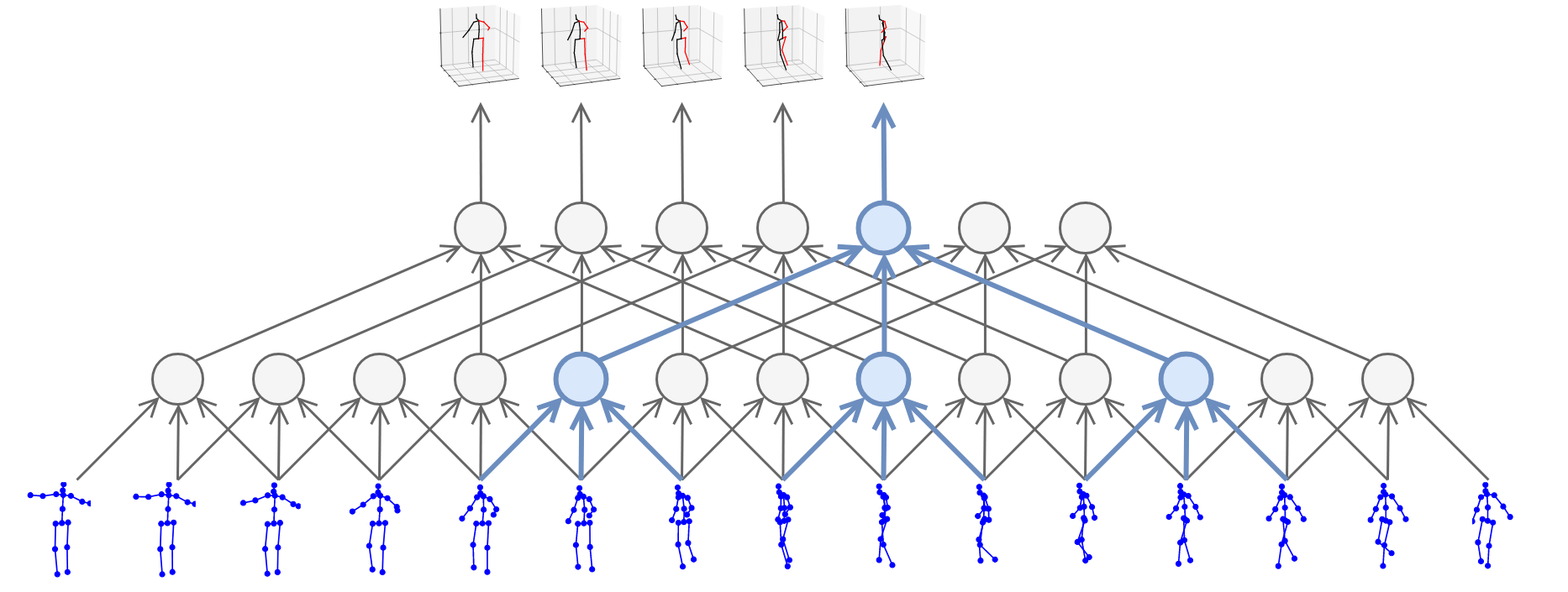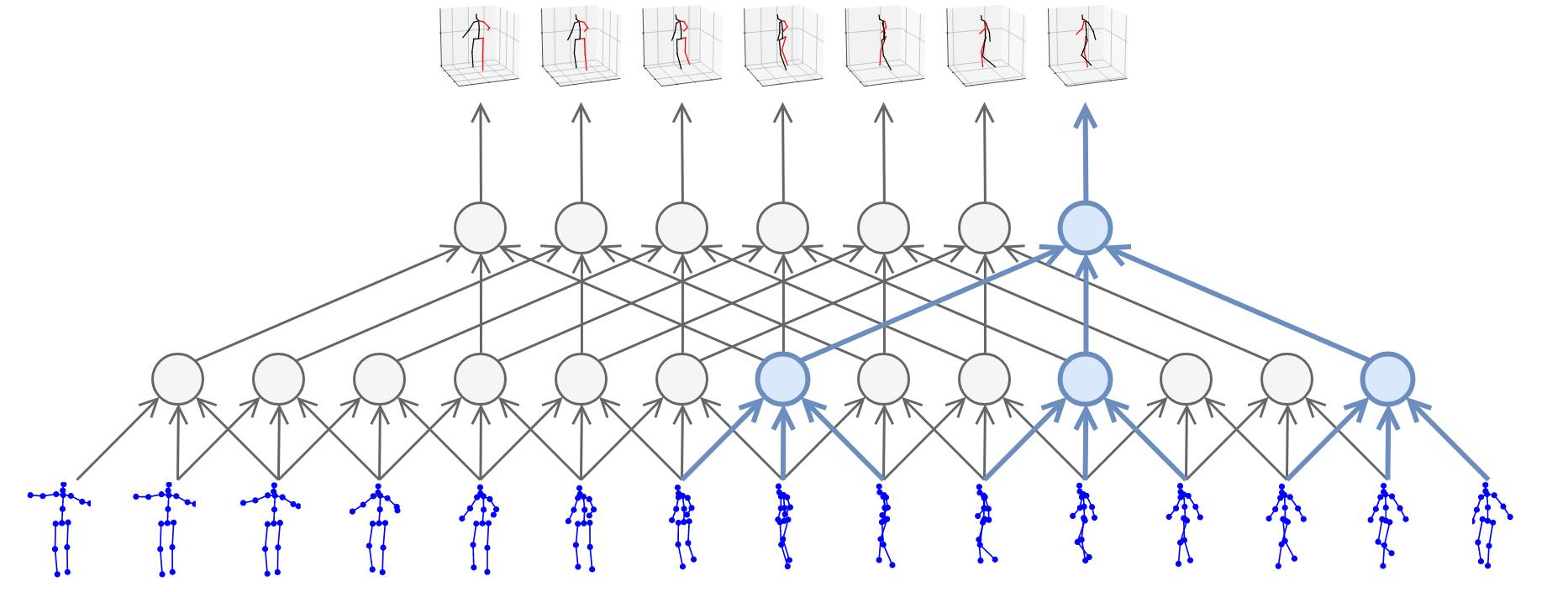
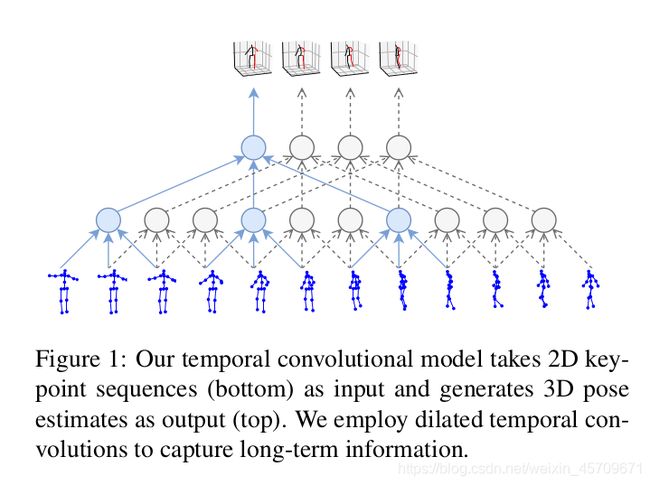
这里的并行处理所指的和以batch处理数据的概念还有些不同, 上图中蓝色的圆圈即是每次做卷积的位置.
图中所示的就是kernel size=3, dilation factor=3的空洞卷积. 在时间纬度上做卷积运算, 考虑了前后帧的信息, 自然可以将2D pose转换为3D pose.
这篇论文中提出的方法, 利用CNNs处理时序信息,不仅提升了处理速度并降低了参数量, 还在当时拿到了SOTA (state-of-art).
1.2back-projection , 利用未标注数据实现半监督学习
虽然有Human3.6M这样的大型数据集和中型数据集Human-Eva I, 但是对于深度学习这种极度依赖数据的技术而言, 再多的数据也不嫌多.而且对于目前越来越复杂的网络结构而言, 数据集始终是一个模型能否有较强泛化能力的重要因素之一. 对于3D HPE, 获得一个优质的数据集并非易事.3D HPE的数据集标注工作往往需要昂贵的动作捕捉设备和专业的场地.
机器翻译(machine translation)在round-trip翻译过程中将A语言翻译成B语言,然后将B翻译成A, 然后尽量减少前后的A语言的差异, 实现了中间监督(intermediate supervision).
论文作者受此启发, 当利用现成的2D keypoints检测器检测2D keypoints时, 先升到3D然后投影回2D, 尽可能减少误差(以此设计损失函数).
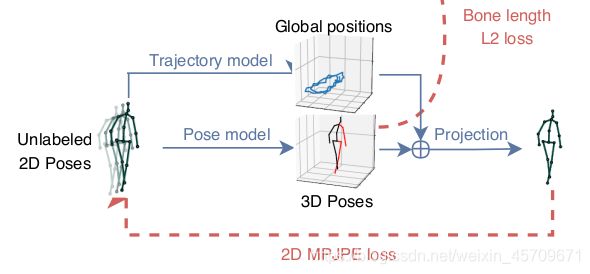
1.3 Related work
早期的3D HPE常利用特征工程以及对关键点的一些假设来实现的. 而早期的CNNs也多是利用单帧图像直接将2D RGB映射到3D Pose上, 缺乏中间层的监督(intermediate supervison).
而近年来的越来越多的研究工作在尝试利用包含时序信息的视频来辅助实现3D HPE, 减少抖动, 让predict出来的pose变得更丝滑.
下面是本论文实现的效果展示.
对于semi-supervised学习, 有些研究利用multi-view recordings作为3D Pose的预训练, 还有一些利用GANs区分2D Pose中真实的Pose和不切实际的Pose.更详细的可以参考原文中该段的叙述.
2.技术原理
2.1Temporal dilated convolutional model
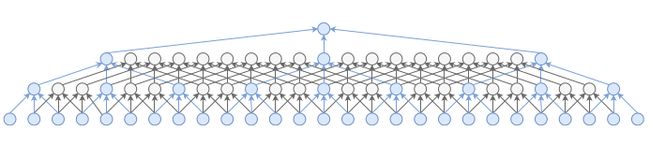
先把网络结构图上一下, 我们逐个分解:
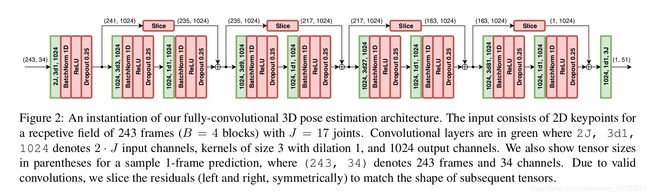
模型采用序列型的2D Pose作为输入, 最左边可以看到,(243,34) 其中243指的是输入243个2D Pose, 其中34 = 17 * 2, 即Human3.6M的17个关键点的skeleton.
2.1.1 空洞卷积 Temporal dilated convolutional layer:
利用参数为 2J 3d1 1024的卷积层提取信息, 其中J = 17, 即是输入的2D Pose的关键点个数, 也是输出的3D Pose的关键点个数. 3d1代表卷积核的kernel size = 3, d代表空洞卷积, 1为dilation factor, 当d = 1时和常规的31卷积核一样,当d=2时, 中间会有1个空洞, d=3有2个空洞. 1024指有1024个卷积核, 则提取出的通道数由217=34 变为 1024.
同样的, 论文中给出的关于空洞卷积的解释如下:

2.1.2 以module的形式搭建神经网络
网络由Reset-style的Blocks堆叠而成, 每一个Block有一个kernel size = 3的卷积层, 还有一个kernel size = 1的卷积层.
其中 kernel size=3的dilated factor d = W^B, W在论文中设置是超参数为3. 而B指的是从右往左数有多少个kernel size=3的卷积层.
例如对于最右边的block, 从右往左4个block, 那么d=3 ^ 4=81. 即3d81,同理, 从右往左数有3个, 那么d=3 ^ 3 = 27, 即3d27.
最左边, b=0, 那么 d= 3 ^ 0 = 1, 即3d1, 而3d1就和常规的3*1的1D 卷积核一样了, 此时做卷积运算且不使用padding, 那么243的特征图就变为241 . (姑且称之为特征图, 其实和2D的意思是一样的, 2D的feature map为 l * h, 1D的就是l ).
因此在经过3d1,kernel num=1024的卷积层运算后,得到的为resolution=241,channel=1024的特征图.
这个特征图将被输入到下面的Reset-style的Blocks:
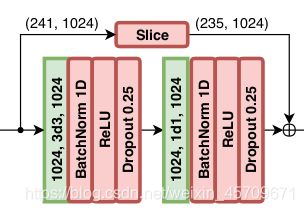
resolution=241,channel=1024, 经过1024 3d3 1024的卷积层运算,那么输出应该是:resolution=235,channel=1024
(前后的通道数因为卷积核的个数不变而保持不变)随后经过 1024 1d1 1024的卷积层, 即kernel size=1,d=1 , 那么这里的1d1就是常规的1卷积(对应于2D 中的1*1卷积), 作用在1D上.同样的,通道数不变.
这里的1d1卷积, 就个人理解主要是Res-block的常规操作, 同时继续增加一个非线性层,进一步提高模型的表现力. (这里可能理解有误,如有大佬看到有问题麻烦指正)
而上面的Slice是为了和经过3d3和1d1卷积运算的feature map实现对应位相加, 因此将一个1*241的向量以中心为轴去掉两边各3个,最后变成235的resolution. channel依然是1024.
后面的block操作基本上就是一样的了, 同时到最后一层就是resolution=1, channel=1024.然后经过3*17个卷积核运算后(卷积核参数为1d1), 即输出最终的3D Pose.
图3:

下面是原文给出的解释:

而前面的各种操作其实形象化的可以用下图来辅助理解, 构成的是一张树状的特征提取过程.
这样的过程在结构上也与RNNs的结构很类似, 但RNNs的"树"不能太深, 否则会出现梯度消失或者梯度爆炸等问题.而这个基于时序卷积的模型则可以充分利用resnet的思想来解决梯度问题.
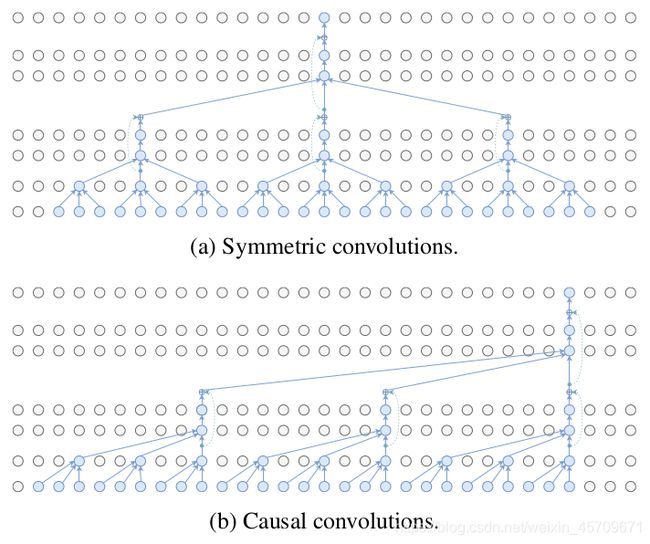
由于作者考虑到在实际应用场景使用这个模型, 但该模型使用时需要前后帧的信息(过去几帧和未来几帧)才能预测一帧,如下图(a) Symmetric convolutions, 而这是无法实时工作的.
考虑到这个问题, 还有一个变体就是如下图所示的(b) Causal convolutions, 即因果卷积, 即只计算过去几帧来预测当前帧:
2.2 Semi-supervised approach
利用现有的2D keypoints detector 和back-projection module将未标注的video产生的loss计算到总loss中, 以便加强监督学习.
作者将这一问题看成是一个自编码器问题: 即利用encoder(pose estimator)将2D Pose坐标转换为3D Pose 坐标, 而decoder则是将3D Pose坐标投影到2D Pose坐标. 在具体实现的过程中比较关键的两个点:
Trajectory model 和Bone length L2 loss .
在实现过程中, Trajectory model 和Bone length L2 loss同时进行优化, 其中标记数据占据前半部分,未标记数据占据后半部分。有3D Pose标记的数据使用Ground Truth(GT) 作为supervised loss, 而无标记的数据则计算自编码器loss, 即计算转换前2D Pose 坐标和转换后的2D Pose坐标的差异性.
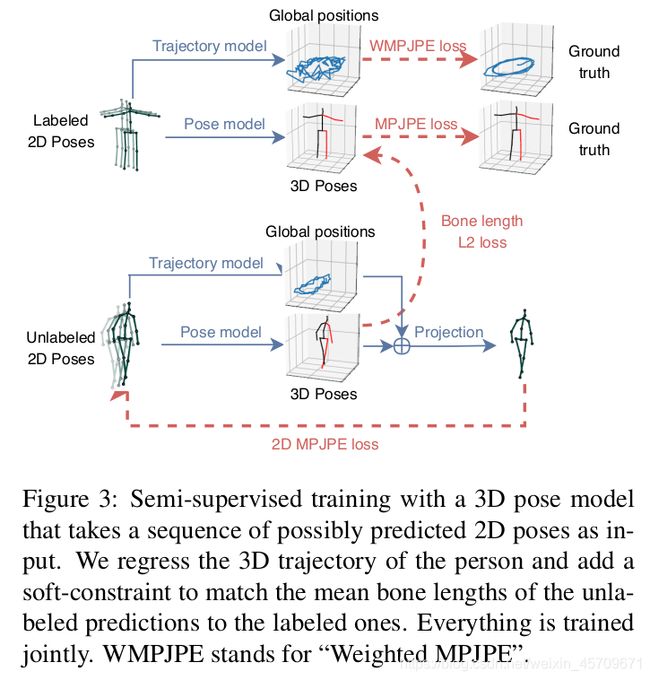
2.2.1 Trajectory model
根据透视投影的特点, 2D Pose在屏幕中的位置, 不仅依赖于轨迹(trajectory 即人体相对于基关键点root joint的全局位置, 基关键点可以是髋关节位置的关键点), 还依赖于各个关键点相对于 root joint的3维位置.
缺少全局位置,2D Pose将始终以固定比例重新投影到屏幕中心导致监督不足, 因此利用了一个Trajectory网络来回归人体的3D trajectory.此外还优化了第二个网络,该网络用于回归摄像机空间中的全局轨迹.
这两个网络结构相同,但是不共享任何参数(作者实验发现共享参数会使结果相互干扰).
另外当相机中的目标人体与相机距离较远, 预测一个精确的trajectory很有难度, 则采用的是加权 MPJPE, 即对每个sample使用距离Yz的倒数作为权重, 其中Yz会在相机的内置参数中给出.
E = 1 / Yz * |f (x) − y|
对于一个较远的目标预测出精确的trajectory没必要, 因为相关的2D keypoints往往落在一个比较集中的小范围内. 因此对于越远的目标, loss权重越低.
这一段的解释不是很清楚, 具体的实现还需要仔细阅读源代码的相应实现, 以便加深理解.
2.2.2 Bone length L2 loss
为了更好的实现监督信息, 以获得更准确合理的3D Pose, 作者实验发现添加软约束(soft constraint)可以有效地将未标记batch中subjects的平均骨长与有标记batch中subjects的平均骨长做近似匹配, 即计算Bone lenght L2 loss. 这里的骨长也就是各个骨骼关键点间的 L2 距离.
这也意味着一个好的Pose model产生的3D Pose应该能尽可能减少前后转换过程中的骨长变化的. 这一点在自监督学习中非常重要的.
2.3 小节
论文提出的用于提高数据使用效率的半监督方法, 只需要摄像机的固有参数,这通常已包含在了相机拍摄的视频流中了。
论文提出的Pose model不依赖于任何特定的网络结构,可以应用于任何以2D joint为输入的3D Pose检测器。在实现过程时,使用前述图3中描述的架构将2D姿势映射到3D。要将3D姿势投影到2D,使用一个简单的投影层,该层考虑线性参数(焦距、主点)以及非线性镜头畸变系数(切向和径向)。
作者发现在Human3.6M中使用的相机的镜头畸变对姿态估计度量的影响可以忽略不计,但是仍然考虑了这些项,因为它们能辅助提供真实相机投影, 以实现更精确模型 。
3.实验和结果分析
3.1 Dataset and Evaluation
作者在Human3.6M和Human Eva-I, 其中Human 3.6M包含3.6million个video frame, 分为11个子集.主要是使用S1, S5, S6,S7,S8这5个子集训练, 然后使用S9和S11作为测试集. 同时运用的是 17-joint skeleton, 前面介绍网络结构时也有提到.
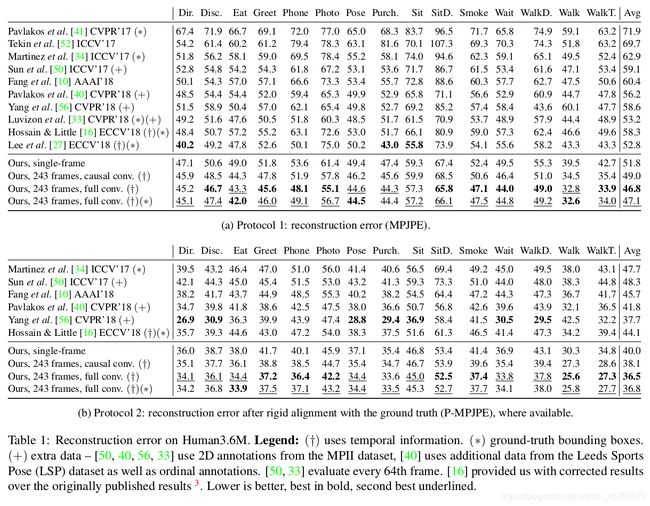
实验结果如下, 表1展示的是在MPJPE和P-MPJPE两种指标下的性能对比图, 具体的结果解释可以参考论文原文.
表1:
2D Pose => 3D Pose 的可视化结果如下图4所示:
图4
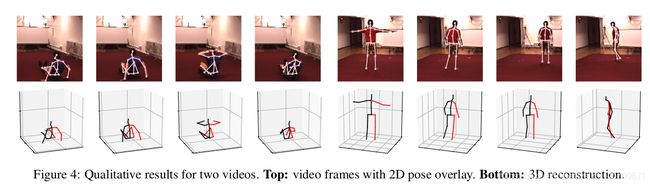
表2展示了单帧图像进行3D Pose预测和利用时序图像实现3D Pose预测的绝对位置误差对比, 由于绝对位置误差(Absolute position errors)会表现在video中, 误差越小, 图像越稳定越丝滑, 误差越大抖动越明显.
表2

前面提到利用现有的2D Pose Estimateor实现2D Pose标注, 以及2D->3D->2D的转换流程, 下面是利用不同Estimator的结果:
表3
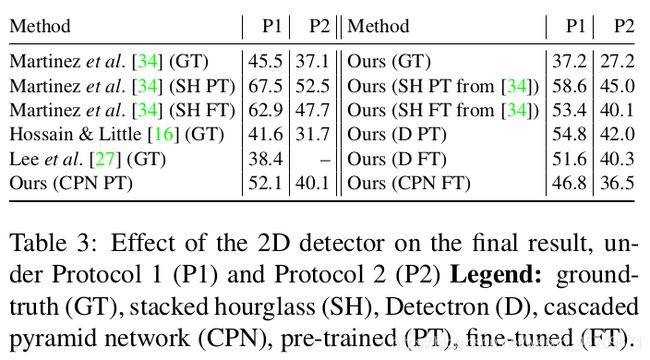
表4展示的是Human Eva-I中不同动作的结果对比:
表4
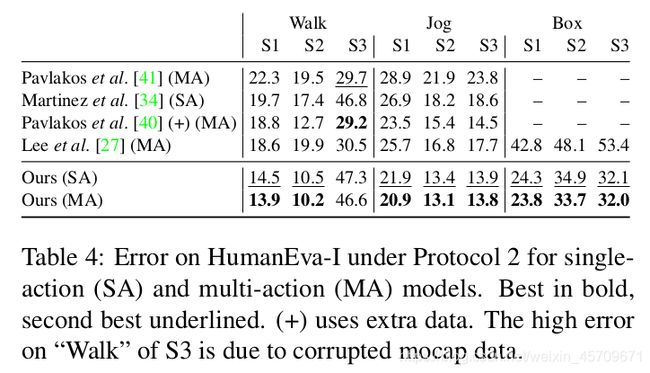
表5比较了基于LSTM的模型和本论文提出的基于时序卷积的模型在参数量浮点运算量和MPJPE的结果.表中后三行中的27f 81f 243f分别指的是利用27个frame预测一个3D Pose, 81个frame预测一个3D Pose等等.在论文中作者也同样将之类比为感受野, 时间维度上的感受野, 也是模型考虑利用时序信息的度量.
表5
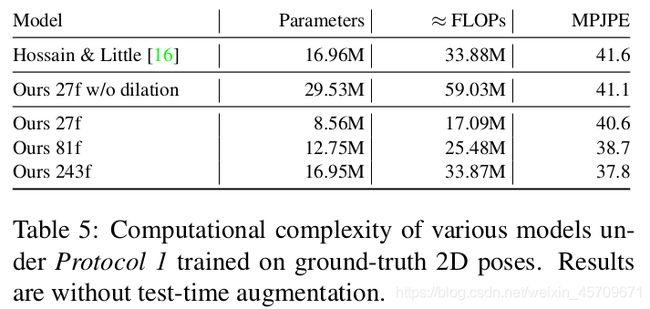
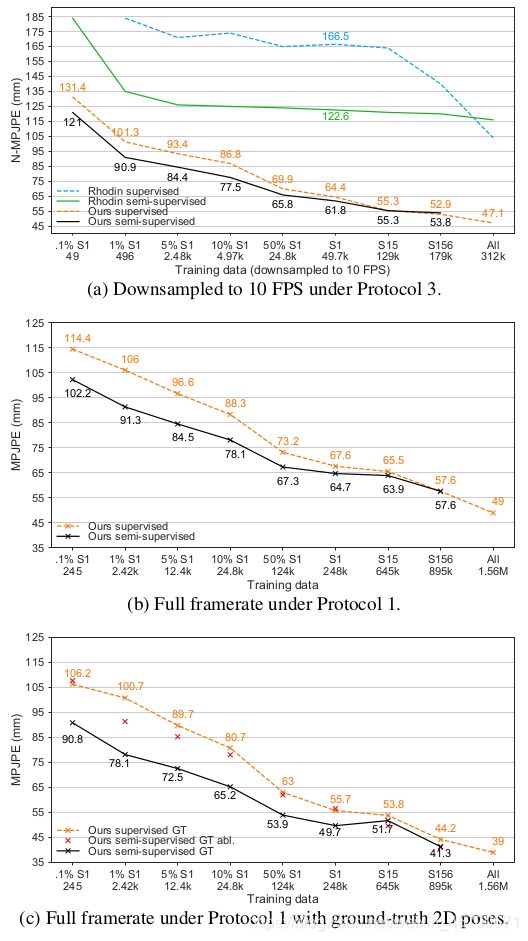
图5展示的是在各种评价指标下, 使用半监督学习和不是用半监督学习的性能对比图.
图5

3.2 2D Pose Estimation 实现细节
实现细节可以帮助我们在复现论文时得出(验证)作者的结果, 后面会尽可能补充一篇复现的博文作为笔记.
论文提出的方法不依赖于任何固定的2D Pose Estimator, 因此作者在多个现有的2D Pose Estimator 上进行实验验证方法的可行性.利用 Mask R-CNN和CPN时, 首先是使用在COCO经过预训练之后的模型, 然后在Human3.6M上进行fine-tune.
Mask R-CNN以ResNet-101作为backbone, 重置最后一层预测keypoint的参数, 以及反卷积层的参数, 随后利用4GPU训练, 步长衰减学习率.
在inference时, 使用soft-argmax, 即在输出的heatmap中使用softmax, 并提取得到的2D分布的期望值 . 这比直接使用argmax(即hard-argmax)得到2D分布的结果要更平滑和精确.
CPN则使用ResNet-50作为backbone, 并输入384*288分辨率的图像, 在finetune时重新学习最后一层的参数并将GlobalNet和RefineNet的参数都重新学习, 指数衰减学习率.
最后将Mask R-CNN和CPN的结果相互比较.
3.3 3D Pose Estimation 实现细节
通过根据摄像机变换旋转和平移地面真实姿态,而不是使用全局轨迹(半监督设置除外), 对摄像机空间中的三维姿态进行训练和评估。优化过程使用Amsgrad作为优化器, 使用指数衰减学习率.在实验中, 作者发现在时间维度上的感受野>1时, 例如前面提到的243, 对于输入的样本间的相互关系非常敏感.
-
作者对此给出的解释是进行batch normalization时, sample1和sample2的相关性太强, 这违背了batch normalization假定的各sample需要相互独立.
-
个人理解是样本间如果关联性太强, 例如前243个frame组成的sample1和相邻243个frame组成的sample2之间如果只是头尾有些差别, 中间的241个frame都一样, 那么预测过程本身就是基于信息增益非常少的两个样本间的学习, 同样的, 在短时间内两个3D Pose之间变化也比较小, 学习进度就比较慢.
为了解决这一问题, 我们通过从不同的视频片段中选取训练片段来降低各训练样本的相关性。剪辑集的大小被设置为我们架构的感受野的宽度,例如将243个frame所对应的2D Pose和正中间的3D Pose共同裁剪为一个训练样本,这样模型就可以预测每个新训练样本的一个3D Pose。这对于模型泛化很重要,作者在论文的附录A.5中对此进行了详细分析。
在代码实现空洞卷积时可以用步长设置为扩张因子的步长卷积代替空洞卷积,从而极大地优化这种单帧设置(作者在论文的附录A.6中对此进行了详细分析)。这避免了计算从未使用过的状态,且仅在训练期间应用此优化。在推理过程中,模型可以处理整个序列,并重用其他3D帧的中间状态,以加快推理速度。因为模型没有在时间维度上使用任何形式的池化操作使得这一想法具有可行性。
作者在实现过程中观察到batch normalization的默认超参数会导致测试误差(±1mm)的大幅波动,以及用于推断的运行估计值的波动。为了获得更稳定的运行统计数据,作者对batch normalization的动量β指数衰减:设置β=0.1开始,然后指数衰减β,以便在最后一个epoch时降低到 β=0.001。
4.总结
个人阅读这篇论文时的理解:
-
这篇时序空洞卷积利用空洞卷积的特点在时间维度上提取信息, 充分利用时序信息补充2D Pose, 使得所预测的3D Pose更平稳丝滑,且无需任何特定的2D Pose Estimator, 给我们拓展了新思路, 后面也有一些工作是基于该论文研究的, 有时间会补上相应的阅读笔记.
-
采用了一个back-projection作为对2D HPE Datasets的补充, 或者称为半监督学习, 也给3D HPE带来了启发, 即充分考虑2D Pose和3D Pose的转换过程中的不变量, 以此作为中间层的监督信息, 促进深层神经网络的训练工作; 此处就是利用 Bone length L2 Loss作为约束条件, 那么我们是否可以设计一个Bone angle L2 Loss作为约束条件, 限制异常情况的angle, 毕竟正常人的四肢是不会出现反折的情况的,事实上也确实在inference时出现了很诡异的预测结果, 但具体效果还有待实验 .
这是这篇论文阅读笔记的第一部分, 第二部分将是作为项目代码阅读后的注释和个人理解, 稍后补充, 这也是从工程实践层面加深自己对于论文思路理解.