TensorFlow2.0自动求导机制(tf.GradientTape的用法)
文章目录
-
- 1 使用tf.GradientTape()计算 y = x 2 y=x^2 y=x2的导数
- 2 当使用常量tf.constant时
- 3 对多个数求导时
- 4 使用求导机制进行线性回归的案例
在机器学习中,我们经常需要计算函数的导数,Tensorflow提供了自动求导机制来计算导数。
1 使用tf.GradientTape()计算 y = x 2 y=x^2 y=x2的导数
计算当x为3时x平方的导数(注意,变量x要设置为浮点型,不能为整型)
import tensorflow as tf # tf为2.*版本 python版本为3.6
x = tf.Variable(initial_value = 3.0) # 定义变量x,初始化为3
with tf.GradientTape() as tape: # 在tf.GradientTape()的上下文中,所有的计算步骤都会被记录,用以求导
y = tf.square(x) # y = x的平方
y_grad = tape.gradient(y,x) # 计算y关于x的导数
print(y) # 输出3的平方 tf.Tensor(9.0, shape=(), dtype=float32)
print(y_grad) # 求出导数为6 tf.Tensor(6.0, shape=(), dtype=float32)
输出:
tf.Tensor(9.0, shape=(), dtype=float32)
tf.Tensor(6.0, shape=(), dtype=float32)
在这里定义了一个变量x,使用tf.variable()声明,与普通张量一样,该变量拥有形状、类型和值这3种属性。变量与普通张量的一个重要区别是,它默认能够被Tensorflow的自动求导机制求导,因此常用于定义机器模型的参数。
补充知识:tf.Variable () 将变量标记为“可训练”,被标记的变量会在反向传播中记录梯度信息。神经网络训练中,常用该函数标记待训练参数。
2 当使用常量tf.constant时
上面的例子中使用了tf.Variable()定义x,下面我们展示使用tf.constant()定义x,注意两者之间求导时的不同,需要tape.watch(x)
import tensorflow as tf # tf为2.x版本
x = tf.constant(3.0) # 定义常量x,初始化为3.0 (浮点型)
with tf.GradientTape() as tape:
tape.watch(x) # 当x为常量时,需使用watch方法
y = tf.square(x)
y_grad = tape.gradient(y,x)
print(y) # 输出3的平方 tf.Tensor(9.0, shape=(), dtype=float32)
print(y_grad) # 求出导数为6 tf.Tensor(6.0, shape=(), dtype=float32)
3 对多个数求导时
注意使用persistent=True
import tensorflow as tf
x = tf.constant(3.0)
with tf.GradientTape(persistent=True) as tape: # 注意使用persistent=True
tape.watch(x)
y = tf.square(x) # y = x的平方
z = tf.pow(x,4) # z = x的4次方
y_grad = tape.gradient(y,x)
Z_grad = tape.gradient(z,x)
print(y.numpy()) # 9.0, 我们将tensor类型转换为numpy类型
print(y_grad.numpy()) # 6.0
print(Z.numpy()) # 81.0
print(Z_grad.numpy()) # 108.0
4 使用求导机制进行线性回归的案例
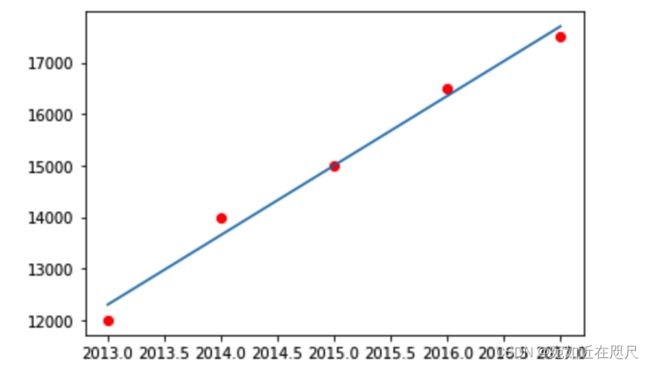
房间数据预测,某城市2013-2017年的房间如表所示
| 年份 | 房价 |
|---|---|
| 2013 | 12000 |
| 2014 | 14000 |
| 2015 | 15000 |
| 2016 | 16500 |
| 2017 | 17500 |
对数据进行回归处理,即使用线性模型y=ax+b拟合上述数据,因此,需要求出参数a和b。
我们使用求导机制计算线性回归
- 使用tape.gradient(ys,xs)自动计算梯度
- 使用optimizer.apply_gradients(grads_and_vars)自动更新参数模型。
其中,使用tf.keras.optimizers.SGD(learning=1e-3)声明一个梯度下降的优化器,其学习率为1e-3,优化器可以帮助我们根据计算出的求导结果更新模型参数,从而最小化某个特定的损害函数,具体使用方式是调用apply_gradients()方法。
更新模型参数的方法optimizer.apply_gradients()需要提供grads_and_vars,即更新的变量与损失函数关于这些变量的偏导数。具体来说,这里需要传入一个list,list的每一个元素是一个(变量的偏导数,变量)的元组,比如这里就是[(grad_a,a),(grad_b,b)]。使用zip()函数便可以使[grad_a,grad_b]与[a,b]进行对应拼装。
具体代码如下:
import tensorflow as tf # tf为2.0版本 python版本为3.6
import matplotlib.pyplot as plt
import numpy as np
# 定义原数据
X_raw = np.array([2013,2014,2015,2016,2017],dtype=np.float32)
Y_raw = np.array([12000,14000,15000,16500,17500],dtype=np.float32)
# 数据归一化
x = (X_raw - X_raw.min())/(X_raw.max() - X_raw.min())
y = (Y_raw - Y_raw.min())/(Y_raw.max() - Y_raw.min())
# 定义张量
X = tf.constant(x)
y = tf.constant(y)
# 定义参数
a = tf.Variable(initial_value=0.)
b = tf.Variable(initial_value=0.)
variables = [a,b]
num_epoch = 10000 # 定义迭代次数
optimizer = tf.keras.optimizers.SGD(learning_rate=1e-3) # 定义优化器,用以后续更新参数
for e in range(num_epoch): # 迭代多次,更新参数a与b
# 使用tf.GradientTape() 记录损失函数的梯度信息
with tf.GradientTape() as tape:
y_pred = a * X + b
loss = tf.reduce_sum(tf.square(y_pred - y)) # 通过预测值与实际值 求出误差
# Tensorflow 自动计算损失函数关于自变量(模型参数)的梯度
grads = tape.gradient(loss,variables) # 求损失关于参数a b的梯度
# Tensorflow 自动根据梯度更新参数,即利用梯度信息修改a与b,使得损失减小
optimizer.apply_gradients(grads_and_vars=zip(grads,variables))
print(a,b)
输出:
绘图查看线性回归结果:
# 用散点图画出原始数据,定义红色
plt.scatter(X_raw,Y_raw,c='r')
# 画出预测(用归一化后的数据计算a*(X_raw)+b,然后再还原)
plt.plot(X_raw,(a*((X_raw - X_raw.min())/(X_raw.max() - X_raw.min()))+b)*(Y_raw.max()-Y_raw.min())+Y_raw.min() )
输出:
参考文献:《简明的TensorFlow2》李锡涵、李卓桓、朱金鹏