Python自定义词频统计函数
前言:自定义编写了一个Python的词频统计代码,可以用来统计单词或者词语出现的次数。
代码思路:
整体思路:
前提:做词频统计的数据要是[(‘字符’,1)…]这样的格式。
编程思路:
1.原始数据是一个列表形式:[‘a’,‘b’,‘c’…],将此列表改成[(‘a’,1),(‘b’,1)…]的样式,可以采用zip()函数。
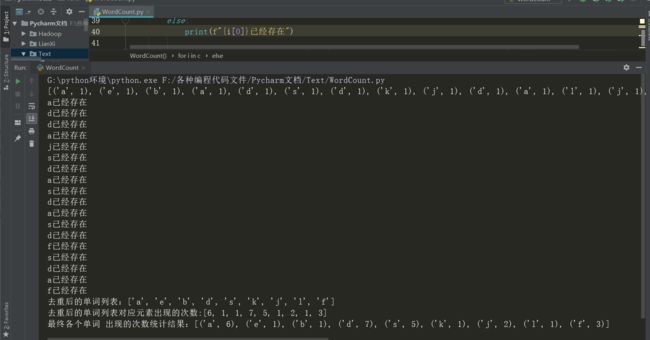
2.将得到的数据进行循环遍历,i[0]取出的是元祖里面下标为0的元素,例如:i[0]就是’a’,同理i[1]就是1。
3.然后将字符放到一个列表中,这里需要进行判断,如果该字符存在,我们就不放入,如果不存在则放入,再将i[1]放入到统计次数的列表中。
4.当出现重复的字符时解决办法:
(1)思考:如何将该字符所对应的次数相加
答:word_list列表中存放的是字符,count_list列表中存放的是出现的次数,他们有个相同点:
word_list列表中下标为0的元素,比如说是a,他的出现次数在count_list中对应的下标也是0(因为制造的数据中a是第一个元素)。
所以这样就可以将后来的重复的字符,将它们的次数相加。
代码编写:
count_list[word_list.index(元素名称)] ,列表.index(元素名称)返回的是对应元素的下标。
5.编写函数
代码如下:
# _*_ coding:utf-8 _*_
'''
@author:zzp
@date:2021/12/4
@purpose:词频统计代码
'''
def WordCount(data_list,word_list,count_list):
c = [*zip(data_list, list([1 for j in range(0, len(data_list))]))] # 组合两个列表
print(c)
# 循环遍历列表c中的元素
for i in c:
# 将列表元素元祖中的下标为0即字符添加到列表b中,在这里要判断列表b中是否已经存在该元素
if not i[0] in word_list:
word_list.append(i[0]) # i[0]:代表列表元素中下标为0的元素,例如:"a"
count_list.append(i[1]) # i[1]:代表列表元素中下标为1的元素,例如:1
# 如果存在了,就将后面的出现次数相加
else:
print(f"{i[0]}已经存在")
count_list[word_list.index(i[0])] = i[1] + count_list[word_list.index(i[0])] # 将出现次数相加
print(f"去重后的单词列表:{word_list}")
print(f"去重后的单词列表对应元素出现的次数:{count_list}")
finall_list = [*zip(word_list, count_list)]
print(f"最终各个单词 出现的次数统计结果:{finall_list}")
# return finall_list # 如果需要接收此数据可以使用return
data_list = list("aebadsdkjdaljsdasdfasdfsdaf")
word_list = [] # 定义存放单词的列表
count_list = [] # 定义存放单词出现次数的列表
# 接收数据的代码
# finall_list = WordCount(data_list,word_list,count_list)
# print(finall_list)
WordCount(data_list,word_list,count_list)
运行结果:
应用方面:可以处理需要作词频统计的数据
案例:下面演示在对大数据职业技能要求做词频统计时的应用。
将技能要求关键词都存放到一个列表中(material_lst ),如下图所示:

然后使用该自定义函数,将material_lst 作为data_list参数传到函数里面:

检验:为了正确性,我们将material_lst列表中的数据导入到DataFrame,使用value_counts()方法来再做一遍。
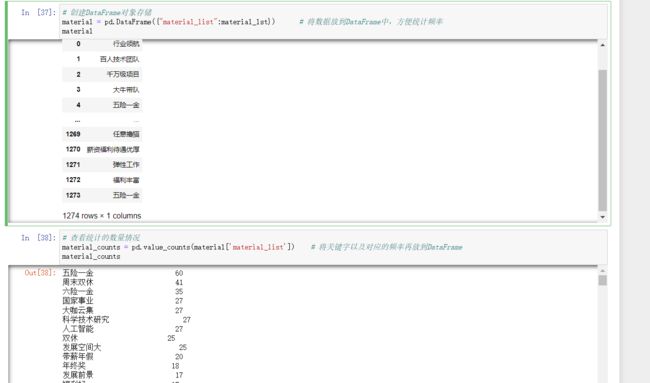
# 创建DataFrame对象存储
material = pd.DataFrame({"material_list":material_lst}) # 将数据放到DataFrame中,方便统计频率
material
# 查看统计的数量情况
material_counts = pd.value_counts(material['material_list']) # 将关键字以及对应的频率再放到DataFrame
material_counts
检验长度是否一致:
print("DataFrame的形状:",material_counts.shape)
print("列表的长度为:",len(finall_list))

随机抽取检验:
finall_list[:10]
material_counts["五险一金"],material_counts["行业领航"],material_counts["行业领航"]
