技术分享 | 遥感影像中的旋转目标检测系列(一)
基于 Transformer 的旋转目标检测框架 D2Q-DETR
01 背 景
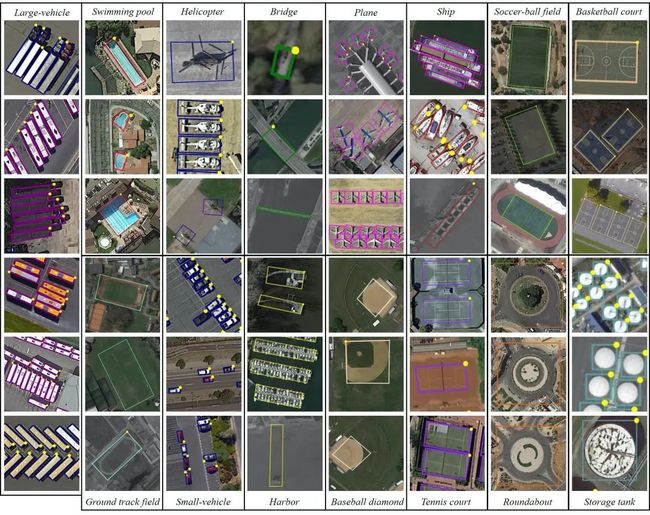
图 1:遥感影像中的目标检测
与自然影像数据集不同,遥感影像中的目标通常以任意角度出现,如图 1所示。自然影像常用的水平框目标检测方法,在遥感影像上的效果通常不够理想。一方面,细长类目的待检测目标(比如船舶、卡车等),使得水平框检测的后处理很困难(因为相邻目标的水平框的重合度很高)。另一方面,因为目标的角度多变,水平框不可避免引入过多的背景信息。针对这些问题,遥感目标检测更倾向于检测目标的最小外接矩形框,即旋转目标检测。旋转目标检测最近因其在不同场景中的重要应用而受到越来越多的关注,包括航空图像、场景文本和人脸等。特别是在航空图像中,已经提出了许多设计良好的旋转目标检测器,并在大型数据集上(比如 DOTA-V1.0)获得了较好的结果. 与自然图像相比,航拍图像中的物体通常呈现密集分布、大纵横比和任意方向。这些特点使得现有的旋转对象检测器变得复杂。我们的工作重点是简化旋转对象检测,消除对复杂手工组件的需求,包括但不限于基于规则的训练目标分配、旋转 RoI 生成、旋转非最大值抑制 (NMS) 和旋转 RoI 特征提取器。
我们的方法基于 DETR,一个最近提出的使用 Transforemer 的端到端对象检测框架。与我们最相关的工作是 O2DETR,它为 DETR 添加了额外的角度回归,从而用于旋转对象检测。角度的直接回归会导致两个问题:一是角度周期性导致的边界不连续;另一个是角度(以弧度为单位)和目标框尺寸(以像素为单位)之间的单位不匹配。与 O2DETR 直接回归角度不同,我们提出的方案是,为每个旋转框预测一组点,预测的这组点的最小外接矩形框将用来表示待预测的旋转目标。点的学习更加灵活,并且一组点的分布可以反映目标旋转框的角度和框的大小。据我们所知,与直接角度回归相比,我们是第一个将点预测与 Transformer 相结合,并在旋转目标检测方面取得了卓越的性能。
我们的主要贡献如下:
-
我们提出一个新型端到端旋转对象检测框架,命名为 DQ-DETR。据我们所知,我们是第一个将点预测与 Transformer 结合起来进行旋转目标检测的工作。
-
我们提出了一种新颖的动态查询设计,它在不牺牲模型性能的情况下减少了对象查询数量。
-
我们首次在解码器层将查询特征解耦为分类和回归特征,显著提高了检测性能。
-
我们提出一种有效的标签重新分配策略以获得更好的性能。
-
与现有的 NMS-based 和 NMS-free 的旋转对象检测方法相比,我们在具有挑战性的 DOTA-v1.0 和 DOTA-v1.5 数据集上实现了新的 SOTA。COCO 数据集的扩展实验也证明了我们的新设计对通用目标检测的有效性。
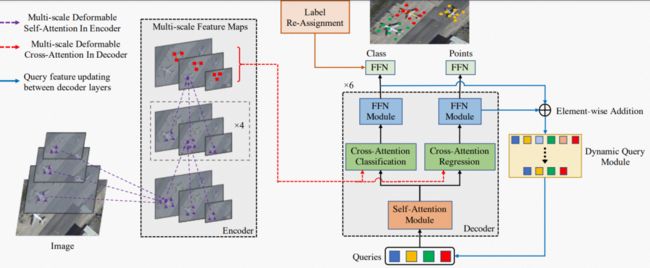
图 2:DQ-DETR总体架构包括四个和主要部分:点预测头、查询特征解耦、动态查询和标签重新分配。
02 方 法
在本节中,我们首先介绍DQ-DETR 的基础版本,包括设计的点预测头和损失函数。然后,我们详细阐述了我们在模型精度和效率方面的进一步改进,包括查询特征解耦、动态查询设计和标签重新分配。
2.1 基础模型
我们的 DQ-DETR 基于最近提出的 Deformable DETR。DQ-DETR和 Deformable DETR 之间的主要区别在于点预测头和损失函数,它们是专门为旋转目标检测而设计的。
2.1.1 点预测头
对每个query, 通用目标检测DETR的box预测分支预测一个4-D矢量,代表预测的水平检测框的中心坐标和框的长宽。 相比DETR,最近提出的ODETR预测一个5-D矢量,通过增加一个角度预测来支持旋转框的预测。 如我们在背景章节所述,直接预测框的角度,会遇到角度不连续的问题。为了避免这个问题,本文提出的{DQ-DETR}不会直接预测旋转框的角度。 具体地,为每个query,我们预测一组点,如图2所示。表示为每个query预测的点的数目,默认设置为9。 点集的学习更灵活,并且预测的点集的分布能够表示待预测的旋转目标框的位置、角度和大小。 在推理时,对每个query,我们将预测的点集通过OpenCV的minAreaRect函数转为旋转矩形框(也即点集的最小外接矩形框)。
2.1.2 标签分配
我们先简单介绍DETR的标签分配策略,该分配策略会在后面的章节进行改进。 如下式1所示,该分配策略的目标是找到queries和真值之间的一对比匹配:
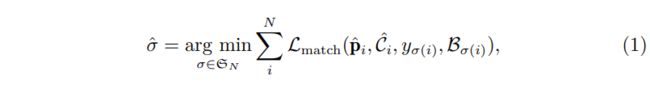
其中是query的数目,是个元素的排列组合。 对第个query, 表示预测的分类概率,表示预测的点集,表示匹配上的旋转目标框的类目标签(可能是),表示匹配上的旋转目标框的四个角点。
The 表示预测 和真值之间的匹配代价函数,定义为:
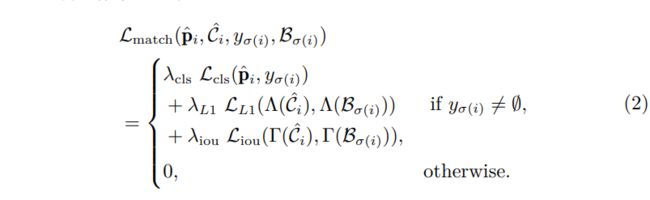
其中表示空或者背景。, and 是用来平衡三个损失项的超参数。如果没有特别说明,这三个超参数默认设置为 , , and . 关于这三个损失项的具体定义,我们放到后面的章节。有了式1和式2,可以通过匈牙利匹配算法计算得到最优匹配。
2.2 查询特征解耦
DETR 检测器并没有考虑查询特征解耦,如图 3(a) 所示。在本节,我们介绍提出的查询特征解耦模块。解码层一般包括两个重要的注意力模块,一个是查询特征本身的自注意力模块,另一个是查询特征和编码器特征之间的交叉注意力模块。在设计查询特征的解耦时,我们对比了两种方式,即只解耦交叉注意力模块(图 3(b)),同时解耦自注意力模块和交叉注意力模块
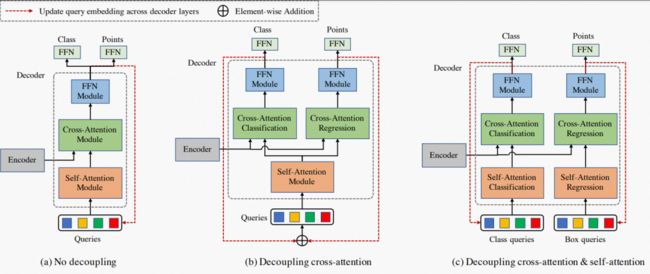
图 3:提出的查询特征解耦示意图。(a)表示Deformable DETR 的解码层。(b) 表示查询特征仅在交叉注意模块中解耦。(c) 表示查询特征在交叉注意和自注意模块中解耦。
(图 3(c))。我们将在下面解释这两种设计。图 3(c) 将查询特征解耦为两组查询特征: class query 和 box query。在我们的DQ-DETR 中,clas query和 box query 分别负责目标的类预测和点集预测。class query 和 box query的数量是一样的,按顺序一一配对。解耦后,这两组 queries 将独立的进行自注意力和交叉注意力。
我们的实验表明,图 3(b) 和图 3(c) 的设计,都比原始的 DETR 的解码器设计要好。其中,图 3(b) 的设计取得的性能最高,后面我们默认使用这种设计。
2.3 动态query
一个有趣的发现是,尽管 DOTA-v1.0 数据集中 99.9% 的 patch 图像(大小为 1024*1024)含有不超过 500 个标注对象,但即使 query 数目达到2000,模型的性能也能继续提升。一个可能的原因是,增加 query 数目将使查询特征和编码器特征之间的信息交换更加全面,并增加检测到更多目标的概率。DETR 等检测器一般堆叠 6 层解码器,每层解码器使用相同数目的 quereis。如果增加 query 的数目,将不可避免的增加模型的计算量和显存占用。为了更好地平衡模型性能和效率,我们提出在解码器层中动态减少query 数目。核心思想是我们将第一个求解器层的query数量设置为初始值,同时动态减少后续求解器层的query数量,如下式3所示:
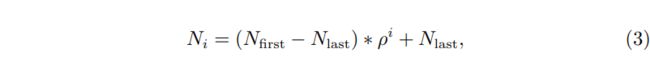
其中表示第一层解码器中的query数目, ()表示最后一层解码器中的query数目, 表示第层解码器的query数目。
如式3所示,第层解码器的query数目小于第层解码器中的query数目,因此我们需要从第层解码器的queries中选择 个输入到第层解码器。 我们在第 层解码器中选择具有较大分类预测概率的前个queries。
2.4 标签映射重分配
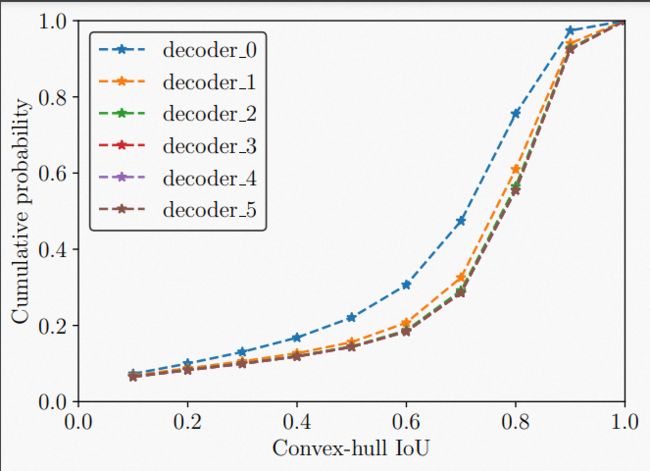
图 4: 不同解码器层中 convex-hull IoU 的累积分布函数图。该 convex-hullIoU 是在预测输出和匹配的目标之间计算的。
为了调查二分匹配后 query 的质量,我们使用训练了 50 epochs 的 DQ-DETR 模型来统计 DOTA-v1.0 验证集上 query 的预测和匹配的目标框之间的 convex-hull IoU。如图 4 所示,在最后一个解码器层中,大约 10% 的queries 与其匹配的目标框的 convex-hull IoU 低于 0.5。并且在第一个解码层中该比率增加到大约 25%。
模型性能和收敛速度会受到低质量查询的影响。为了减轻低质量query的不利影响,我们提出在二分匹配后重新分配query的匹配标签。 如下式4所示,在二分匹配之后,我们检查query预测 和匹配的目标框之间的convext-hull IoU,并将低于阈值 的query的分配标签 设置为 。
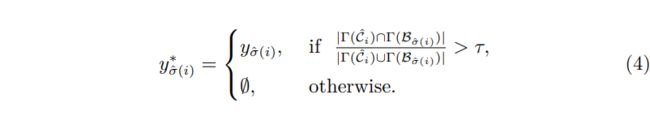
其中超参数默认设置为0.5。
基于重分配的query标签,模型的损失更新为:
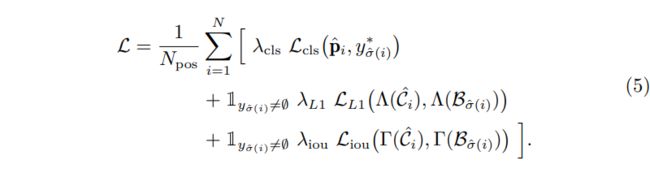
03 实 验
3.1 数据集
DOTA 是航拍图像中最大的旋转目标检测数据集,有两个常用版本:DOTA-v1.0 and DOTA-v1.5。DOTA-v1.0 包含 2806 张航拍图像,图像大小从 800 × 800 到 4000 ×4000。DOTA-v1.0 标注了 15 个常见类别的共计 188, 282 个实例,这些类别是:平面(PL),棒球场(BD),桥(BR),地面跑道(GTF)、小型车辆(SV)、大型车辆 (LV), 船舶 (SH), 网球场 (TC), 篮球场 (BC)、储罐 (ST)、足球场 (SBF)、圆形路口 (RA)、海港 (HA)、游泳池 (SP) 和直升机 (HC)。
DOTA-v1.5 是 DOAI 2019 挑战赛发布的,新增类别集装箱起重机 (CC)和更多极小实例(小于 10 像素)。DOTA-v1.5 包含 402、089 个实例。与DOTA-v1.0 相比,DOTA-v1.5 更具挑战性,但是训练结果更稳定。
按照之前方法中的设置,我们使用训练集和验证集进行训练,使用测试集进行测试。我们将原始图像裁剪成 1024 × 1024 的小图,步长为 824 像素。除了采用随机水平翻转和随机旋转来避免训练过程中的过度拟合,没有使用其他训练技巧。
3.2 和SOTA对比
为了与其他方法进行公平比较,我们准备了三个尺度 0.5, 1.0, 1.5 的多尺度数据。由于准备了大量的多尺度数据,我们发现 20 epochs 足以训练模型,并且学习率在第 16 个 epoch 时衰减了 10 倍。
DOTA-v1.0 的数据集上的结果
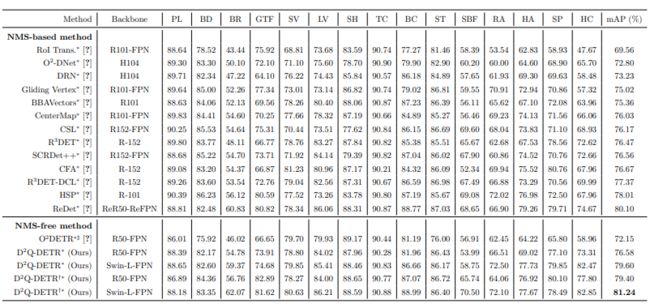
表 1: Performance comparisons on DOTA-v1.0 test set.
如表 1所示,在 DOTA-v1.0 数据集的旋转框检测任务(OBB Task)上,我们的 DQ-DETR获得了 81.24 mAP,超过了现有方案。
Results on DOTA-v1.5.
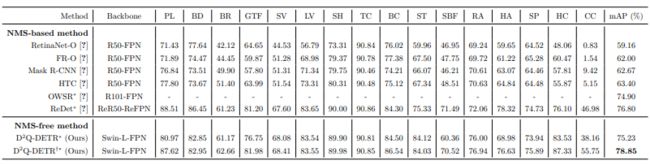
表 2: Performance comparisons on DOTA-v1.5 test set.
与 DOTA-v1.0 相比,DOTA-v1.5 包含许多极小的实例,增加了物体检测的难度。我们在表 2中报告 DOTA-v1.5 测试集的 OBB 结果。与之前ReDet 的最佳结果相比,我们的模型实现了 78.85 mAP 的最好性能。
下图 5 展示了在 DOTA-v1.5 数据集上的一些检测结果。

3.3 COCO 数据集上的扩展实验
如表 3 所示,我们提出的组件(除了为旋转对象检测设计的点预测头除外)提高了 Deformable DETR 在 COCO 数据集上的性能,这验证了它们对通用目标检测的有效性。
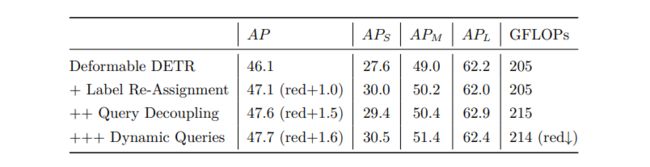
表 3: Performance comparisons on MS-COCO dataset. 所有模型使用 R50作为骨架模型,并且都训练 50 epochs。
04 结 论
我们提出了一个名为 DQ-DETR 的端到端旋转目标检测器。DOTAv1.0 和 DOTA-v1.5 数据集上的实验结果证明了 D2Q-DETR 的有效性。此外,在 COCO 数据集上的扩展实验进一步表明了我们的新设计对通用目标检测也是有效的。
作者信息: 周强,浙江大学博士, 就职于阿里巴巴达摩院AI Earth团队,主要研究计算机视觉。