机器学习初探之logistic回归
正文
在前面我们知道,感知机对数据进行分类是生成一个超平面(在二维世界中是一条直线),这个超平面可以将图中的两类点区分开。如下图所示:

但是感知机存在一个很重要的问题,那就是它是一个硬分类,我们只用sign(w*x+b)输出的+1和-1来判断点的类别。
如下图所示:

这么简单的判别方式真的会很有效吗?
虽然我们已经程序测试过正确率很高,但总是让人有点担心是否在很多情况下都能很好地工作。事实上我们从小到大一直会听到一些升学考试差一分两分的例子,那么差一分和高一分的学生真的就是天壤之别吗?感知器也是如此:在超平面左侧距离0.001的点和右边0.001距离的点输出就是+1和-1这天壤之别的差距真的合适吗?
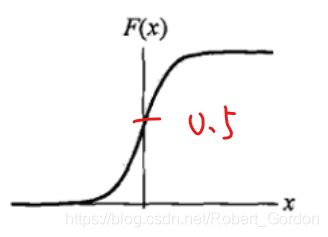
此外我们也知道机器学习中通常会对目标函数进行微分进而梯度下降,但我们看上面这张图。很明显x=0是跳跃间断点,因此sign是一条不光滑的函数,没有办法进行微分。emmm……咦?那我记得感知器用了梯度下降,它是怎么去梯度下降的?
我们回忆一下感知器的梯度下降方式,确实用了梯度下降,但是发现没有,我们是对sign内部进行梯度下降(通过点到直线的距离十分巧妙作为损失函数进而使用梯度下降法进行参数的确定),相对于其它直接微分的算法来说,感知器的这种方式确实有点不太好。如下图所示:

接下来我们对感知机存在的两个问题进行优化。
1、怎么解决极小距离差别带来的+1和-1的天壤之别?
在逻辑斯蒂回归中大致思想与感知器相同,但在输出+1与-1之间存在一些差别。在朴素贝叶斯中我们提到过P(Y|X),它表示在给定X条件下,Y发生的概率。逻辑斯蒂也使用了同样的概念,它使用p(Y=-1|X)和p(Y=1|X)来表示该样本分别为-1或1的概率(实际上逻辑斯蒂并非强制要求标签必须为1或-1,可以用任意标签来表示)。这样当再出现样本X1距离为-0.001时,可能P(Y=1|X1)=0.49,P(Y=0|X1)=0.51,那么我们觉得X1为0的概率更大一点,但我们同时也清楚程序可能并不太确定X1一定为0。
使用概率作为输出结果使得样本在距离很小的差别下不再强制地输出+1和-1这两种天壤之别的结果,而是通过概率的方式告诉你结果可能是多少,同时也告诉你预测的不确信程度。这样子看起来让人比较安心一点不是吗?
2.怎么让最终的预测式子可微呢?
虽然无法微分并不会阻碍感知器的正常工作(事实上只是避开了sign),但对于很多场合都需要微分的机器学习来说,能找到一个可以微分的最终式子是很重要的。为了解决第一个问题我们提出了一种概率输出模型,那么感知器的sign也需要被随之替换为一种能输出概率大小的函数。具体函数在如下所示,其中值得高兴的是,我们找到的概率输出式子是平滑的,可微的,所以第二个问题也就迎刃而解了。
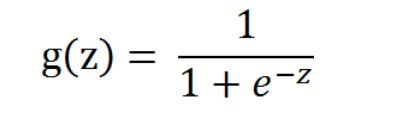
逻辑回归模型的建立
顺便说一下,逻辑回归算法是分类算法,我们将它作为分类算法使用。有时候可能因为这个算法的名字中出现了“回归”使你感到困惑,但逻辑回归算法实际上是一种分类算法,它适用于标签 y 取值离散的情况,如:1 0 0 1。
接下来,讲解逻辑回归算法的细节。
逻辑回归,该模型的输出变量范围始终在0和1之间。 逻辑回归模型的假设是: hθ (x)=g(θ^T*X) 其中: X 代表特征向量 g 代表逻辑函数
假设我们有m个样本,每个样本有n各属性特征,所表示的含义如下:

则建立的线性回归如下图所示:

在线性模型回归中,通常采用最小二乘法,然后再通过梯度下降,便可获得很好的效果。但在logistic函数中,它的代价函数是非凸的,我们求到的极值点不是全局最优而实局部最优的,不能采用这种方法。
如下图所示:
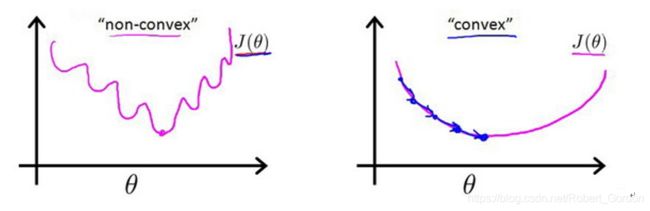
因此重新定义代价函数

代价函数的含义是:当实际的 y=1 且hθ (x)也为 1 时误差为 0,当 y=1 但hθ (x)不为1时误差随着hθ (x)变小而变大;当实际的 y=0 且hθ (x)也为 0 时代价为 0,当y=0 但hθ (x)不为 0时误差随着 hθ (x)的变大而变大。

接下来对代价函数进行梯度下降算法,更新参数θ:

实战
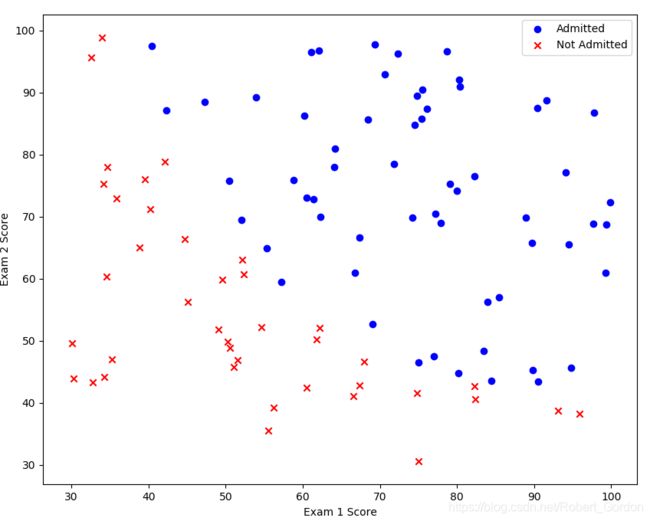
在训练的初始阶段,我们将要构建一个逻辑回归模型来预测,某个学生是否被大学录取。设想你是大学相关部分的管理者,想通过申请学生两次测试的评分,来决定他们是否被录取。现在你拥有之前申请学生的可以用于训练逻辑回归的训练样本集。对于每一个训练样本,你有他们两次测试的评分和最后是被录取的结果。为了完成这个预测任务,我们准备构建一个可以基于两次测试评分来评估录取可能性的分类模型。
1、首先我们先载入数据:

read_csv()函数以表格的形式读取数据。

2、可视化数据
3、sigmoid函数
代码实现sigmoid函数。


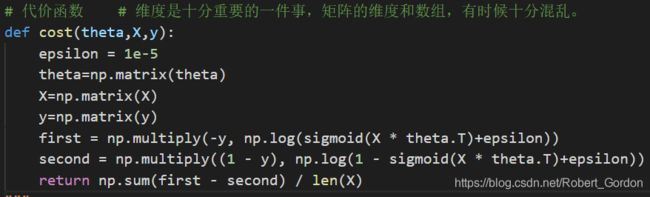
4、代价函数: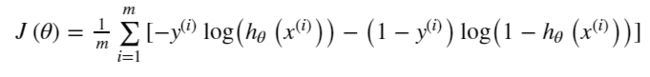
代码为:
5、梯度下降

对参数进行迭代更新:
![]()

在这里展示代价函数于迭代次数的关系图:

由图可知:随着迭代次数的增加,代价函数的值不断减小。
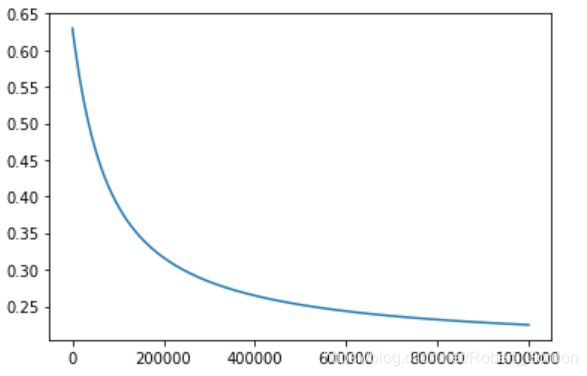
在迭代1000000次之后的参数值为:
![]()
6、画出边界

7、正确率

![]()
代码为:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#首先载入数据
data = pd.read_csv('logis/ex2data1.txt', names=['exam1', 'exam2', 'admitted'])
#print(data.head()) #查看数据是否正确 输出前5个数据
#可视化数据
positive=data[data['admitted']==1] #将标签为1的数据放入positive中
negative=data[data['admitted']==0]
#fig代表绘图窗口(Figure);ax代表这个绘图窗口上的坐标系(axis),一般会继续对ax进行操作。
fig,ax=plt.subplots(figsize=(10,8))
#让我们创建两个分数的散点图,并使用颜色编码来可视化,如果样本是正的(被接纳)或负的(未被接纳)
ax.scatter(positive['exam1'], positive['exam2'], c='b', marker='o', label='Admitted')
ax.scatter(negative['exam1'], negative['exam2'], c='r', marker='x', label='Not Admitted')
ax.legend() #增加图例 即label标签
ax.set_xlabel('Exam 1 Score')
ax.set_ylabel('Exam 2 Score')
#plt.show()
#logistic 函数
def sigmoid(z):
return 1/(1+np.exp(-z))
# 代价函数 # 维度是十分重要的一件事,矩阵的维度和数组,有时候十分混乱。
def cost(theta,X,y):
epsilon = 1e-5
theta=np.matrix(theta)
X=np.matrix(X)
y=np.matrix(y)
first = np.multiply(-y, np.log(sigmoid(X * theta.T)+epsilon))
second = np.multiply((1 - y), np.log(1 - sigmoid(X * theta.T)+epsilon))
return np.sum(first - second) / len(X)
#取X,y和theta值
data.insert(0,'ones',1) #相当于ax+b的b值
col=data.shape[1] #输出列数,为4
X=data.iloc[:,:col-1].values #进行切片,前三列的值,即 1 exam1和exam2
y=data.iloc[:,col-1:col].values #最后一列,即标签。iloc()和loc()这两个函数的用法
theta=np.zeros(X.shape[1])
# 梯度下降法
def gradient(theta_star,X,y,alpha=0.001,iter=1000000):
theta=np.matrix(theta_star)
X=np.matrix(X)
y=np.matrix(y)
jvec=[]
parameters=int(theta.ravel().shape[1]) #ravel()函数是将theta变成一行矩阵 求theta的个数
temp=np.zeros(parameters)
for j in range(iter):
for i in range(3):
error=sigmoid(X*theta.T)-y
term =np.multiply(error,X[:,i])
temp[i]=temp[i]-alpha*(np.sum(term)/len(X))
theta=np.matrix(temp)
jvec.append(cost(theta,X,y))
return temp,jvec
s,m=gradient(theta,X,y,0.001,1000000)
#plt.plot(range(1000000),b)
#plt.show()
boundary_xs = np.array([np.min(X[:,1]), np.max(X[:,1])]) #找出的一门课成绩的极值。
boundary_ys = (-1./s[2])*(s[0] + s[1]*boundary_xs)
plt.plot(boundary_xs,boundary_ys,'b-')
plt.legend()
plt.show()
#下面验证它的正确率是多少
def makePrediction(theta, X):
probability=X*theta.T
return [1 if x>=0 else 0 for x in probability]
predictions = makePrediction(np.matrix(s),np.matrix(X))
#这里zip()函数返回由元组组成的列表
# 比如a=[1,2,3] b=[3,4,5] s=zip(a,b)
# s=[(1,3),(2,4),(3,5)] 由此来进行判断训练的与真实的标签进行比较
correct = [1 if ((a == 1 and b == 1) or (a == 0 and b == 0)) else 0 for (a, b) in zip(predictions, y)]
q=sum(correct)
accuracy=q%len(correct)
print('accuracy = {0}%'.format(accuracy))
这一篇写的比较乱,应该从线性模型和最小二乘法写起,然后在一步步的过度到非线性模型中,之后在加上正则化、特征归一化这些方法。
还有一种方法来解释逻辑回归是从概率判别模型中进行数学公式的推导,然后利用极大似然法进行参数的估计,最后参数迭代的数学公式是一样的(个人感觉代价函数这种方法比较简单、而且方便理解)改天将会讲解这种方法。
有什么问题大家可以直接留言。