吴恩达神经网络和深度学习课程自学笔记(十)之深层卷积神经网络
深层卷积网络
一、总述
计算机视觉研究中的大量研究集中在如何把这些基本构件组合起来,形成有效的卷积神经网络。
而找到感觉的方法之一就是多看一些案列,通过研究别人的来构建自己的。
已有的一些例如识别猫、识别人脸等比较好的框架,在我们需要用到其中的某部分时我们可以借鉴来解决自己的问题。
下面主要是一些计算机视觉的经典网络,包括:LeNet-5、AlexNet、VGGNet等。
然后还有残差网络(ResNet),主要是对于比较深层的网络提出了一些好的解决办法(隐藏层变多导致网络准确度达到饱和然后急剧退化)。最后就是Inception网络。
二、经典网络
2.1 LeNet-5
这是一个主要用于手写字体识别的经典的卷积神经网络。
2.1.1 网络结构
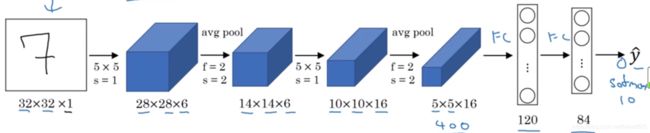
首先是一个卷积层,输入一个32×32×1的图片,然后使用为5×5×6的过滤器(卷积核)进行卷积操作,步长为1,处理后得到一个28×28×6的输出。
接着为池化层,采用平均池化(以前都是平均池化,现在多为最大池化)。过滤器大小设置为2×2×6,步长为2,得到一个14×14×6的输出。
接下来为卷积层,采用5×5×16的过滤器,步长为1,得到一个10×10×16的输出。(当时并未提出padding,因此图像会缩小)。
接着又一个池化层,输出5×5×16的输出。
然后是全连接层,有5×5×16=400个节点,每个节点有120个神经元。
最后一步为利用84个特征来得到最后的输出。本网络采用的是RBF函数,即:
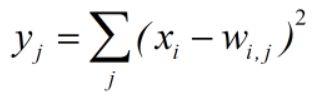
而现在主要是使用softmax函数。
2.1.2 网络特点
该网络大约有6万个参数。
随着网络的加深,图像越来越小,而信道数越来越多。
当时计算力不足,所以过滤器的信道数等于上一层的信道数,这样可以简化计算,现在不需要强制这样了。
LeNet-5在池化后进行了非线性激活函数处理,使用的是sigmoid函数,现在多为ReLU函数。
Tip:读这篇论文精读第二部分,泛读第三部分,其他部分不需要仔细看,提到的变形并未在今天被广泛使用。
2.2 AlexNet
2.2.1 网络结构
原文输入图片大小是224×224,实际上227×227更好。
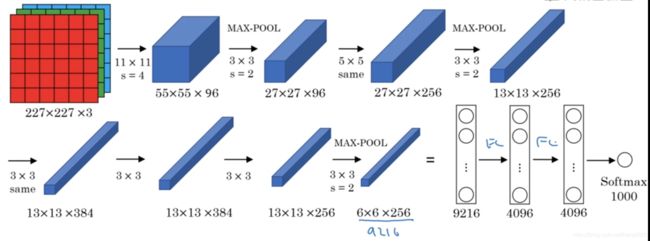
首先是卷积层,使用11×11×16的过滤器,步长设置为4,卷积后得到55×55×96的输出;
接着是池化层,采用最大池化,过滤器设置为3×3×96,步长为2,得到一个27×27×96的输出;
接着是卷积层,采用5×5×256的过滤器,步长为2,padding=same(填充后使得处理后的图像大小与输入相同),处理得到一个27×27×256的输出;
接着是池化层,最大池化,过滤器设置为3×3×256,步长为2,padding=same,得到一个13×13×256的输出;
接着进行两次与前面相同的卷积,最后再进行一次最大池化,最后输出为6×6×256
最后展开,构建全连接层,使用softmax输出结果(1000个种类)
2.2.2 网络特点
网络大约有6000万个参数。
与LeNet有很多相似之处,但是它更大,参数更多,比它更优异,主要有以下原因:
(1) 使用非线性激活函数:ReLU
此前经常用的激活函数sigmoid以及tanh函数容易出现梯度弥散或梯度饱和(输入非常大或非常小的时候,这些神经元的导数接近于0,而反向传播时梯度须乘以sigmoid导数,会造成梯度越来越小,导致网络变得很难学习)。而ReLU函数在x>0时导数始终为1,所以计算量大大减少,收敛速度会快的多。
(2) 数据扩充
大量的数据可以提升准确率,避免过拟合,加深网络结构等。
具体做法:
1)随机裁剪:对左上、右下、左下、右下、中间以及镜像的这些部分共10个,之后对结果求平均。
2)在RGB做PCA,找到主成分,然后大小成比例的使R,G,B变形,其实也就是对颜色、光照作变换,增加了 对颜色更改的鲁棒性。
(3)重叠池化
一般的池化并不重叠,即池化区域的大小与步长相同。而AlexNet采用重叠池化,即移动的步长小于池化的窗口大小。这样做可以减少过拟合。
(4)局部归一化(LRN)
归一化的目的是抑制,ReLU函数的激活结果是无界的,所以需要抑制一下。这样做有助于增加泛化能力。
(5)Dropout
主要是为了防止过拟合。
对于某一层的神经元,通过定义的概率将某些神经元置0,则该神经元不再参与前向和反向传播,如同被删除一样,但同时保持神经元的个数不变,然后继续参数更新。在下一次迭代中又随机删除一些直至训练结束。
这样每次生成的网络结构都不一样,通过组合多种网络模型并平均这样可以减少过拟合,而只需要多花点时间。
(6)多GPU训练
目前的GPU非常适合并行处理,他们可以互相读写内存,这是前提。
将网络分布在两个GPU上训练,只在特定的几层进行通信,这样稍微减少了训练时间但是降低了错误率。
2.3 VGGNet
并没有太多的超级参数(过滤器大小、步长、padding等),只需要专注于构建卷积层的简单网络。
2.3.1 网络结构
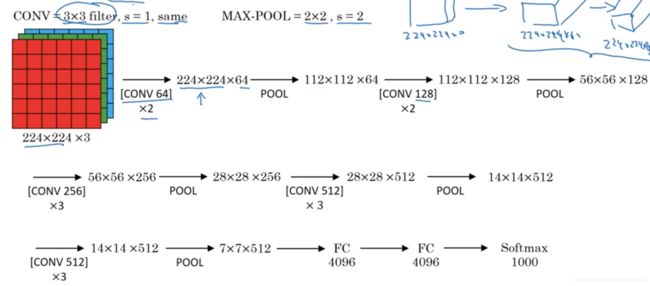
首先为卷积层,使用3×3×64的过滤器,步长为1,padding=same,接着相同的卷积操作再处理一次,也就是两次卷积,输出224×224×64的图像;
接着为池化层,最大池化,过滤器设置为2×2×64,步长设置为2,输出112×112×64的图像;
接着为若干个卷积层,使用3×3×128的过滤器,其他参数不变,得到一个112×112×128的输出;
接着池化层,最大池化,参数也一样,输出56×56×128;
再接着3个卷积层,过滤器信道数为256,其他参数相同,再最大池化,再3个卷积层,再一个最大池化,最后得到7×7×512的输出;
然后全连接层,4096个单元,softmax输出结果。
2.3.2 网络特点
本网络包括1.38亿个参数。
VGG有两种,具体如下:
VGG-16:共有16层,13个卷积层(池化不计算层数)+3个全连接层
VGG-19:共有19层,16个卷积层+3个全连接层
这两个性能差别不大,一般指VGG-16。
网络很大但是结构清晰不复杂,就是若干个卷积层后跟一个池化层,池化层用于缩小图像。过滤器信道数数量依次翻倍,图像依次缩小一半。
主要缺点是:需要训练的特征数量非常巨大。
三、残差网络(ResNet)
非常深的网络是难以训练的,因为存在梯度消失和梯度爆炸的问题,残差网络很好的解决了这个问题。
3.1 残差块
残差网络由残差块组成。残差块就是:

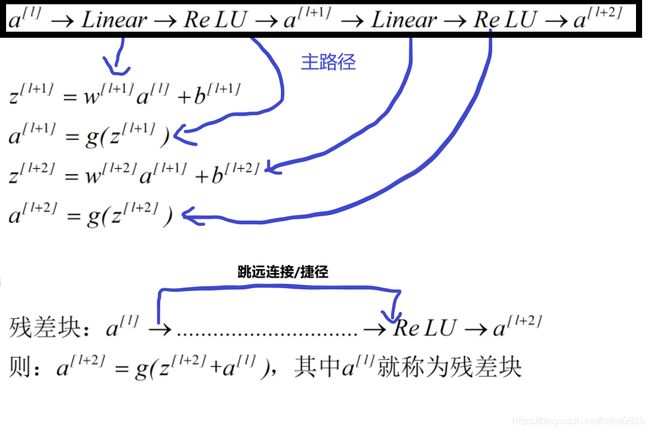
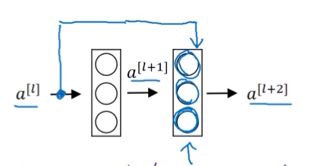

具体实例:5个残差块构成一个残差网络。
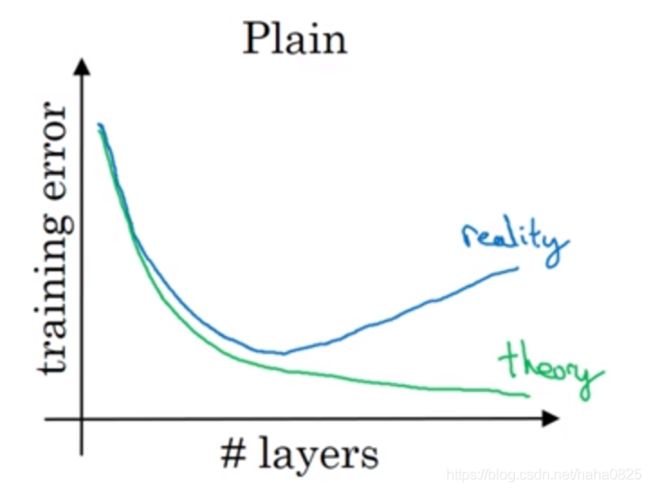
对于一个普通网络,理论上网络越深误差越小,实际上,在一定深度后,误差开始变大。
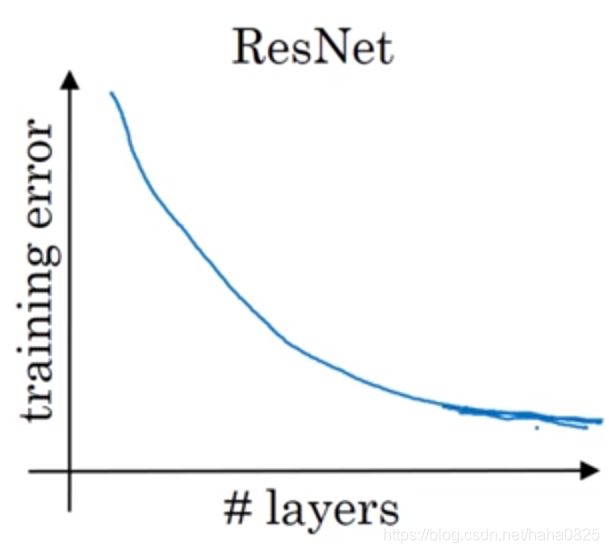
而残差网络,随着网络深度加深,误差则越来越小。
对于中间的这些激活能够达到网络的更深层,这种方式有助于帮助解决梯度消失和梯度爆炸问题,保证我们在训练比较深的网络时也能保持较好的性能。
3.2 为何残差网络有效?
一个例子:
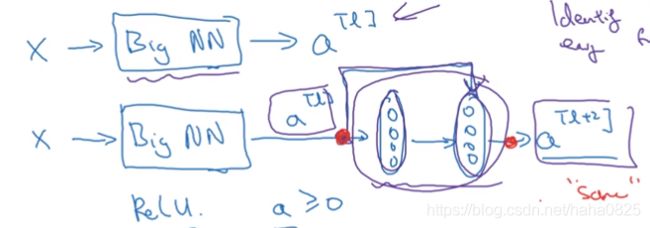
使用ReLU激活函数,默认激活值都大于0,此时

所以有效的主要原因是:残差块学习恒等函数非常容易,深层结构不会影响性能,甚至提高效率。
另一点:假设刚开始的输入与最后的输出维度相同,残差网络使用了很多相同的卷积,相同的卷积不改变维度,所以即使经过了处理,最后输出与输入仍有相同的维度,这也是跳远连接可以实现的原因。
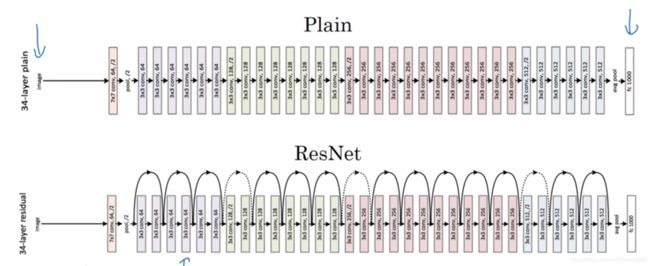
若输入与输出的维度不同,如图中所示只有卷积层,无全连接层,有的其中偶尔也会有池化层或者类似于池化的层,池化导致维度变化,这时需要乘以一个系数(Ws)或者可以使用padding使得他们的维度保持相同。
四、网络中的网络(1×1卷积)
4.1 一个例子
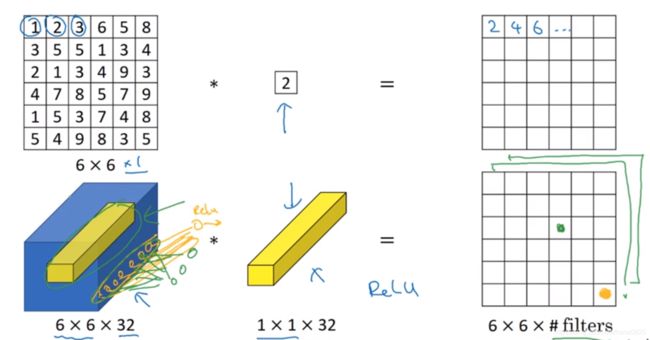
仅仅是对于只有一个信道的(6×6×1)输入,1×1卷积表现并不好,但是对于信道比较多的(6×6×32)1×1卷积有着不错的效果。
1×1卷积遍历这32个数字,然后计算乘积,再应用ReLU函数,可以理解为32个神经元分别乘上他们的权重。
多过滤器的情况,从根本上说,相当于这32个单元都应用了一个全连接层(输入32,输出过滤器数量,也就是全连接层的作用)。
4.2 应用
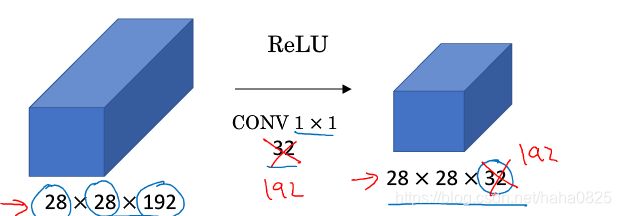
使用32个1×1的过滤器使输入的28×28×192压缩为28×28×32。
这就是作用:压缩信道数量以减少计算。
总体来说,可以利用1×1卷积核压缩/保持/扩大信道数量。
五、Inception网络
5.1 基本介绍
主要用于决定网络结构,是否池化、过滤器大小等。代替人工来确定卷积层中的过滤器类型,以及确定是否需要创建卷积层或池化层。
基本思想:不要认为决定这些参数,由网络自行决定采用哪些过滤器组合。
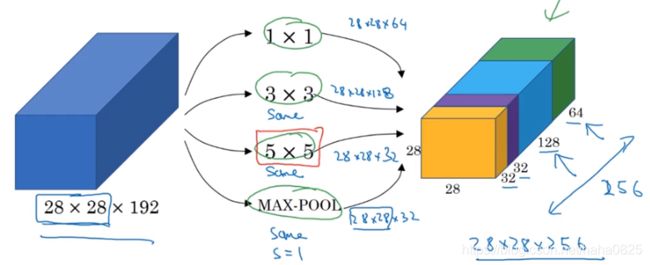
1×1过滤器卷积后得到28×28×64;3×3过滤器卷积后得到28×28×128;大小为5×5,conv=same(卷积使维度相同)的过滤器得到28×28×32;最大池化,padding=same,步长为1,得到28×28×32。
将这些堆积在一起,也就是2828×28×192的输入变成了28×28×256的输出。
下面来专门看看5×5卷积的计算成本:
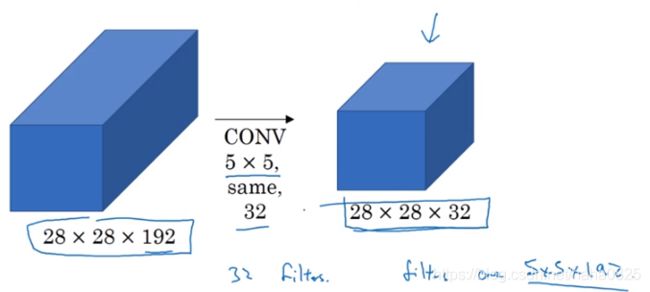
32个5×5×192过滤器,运算次数为28×28×32×5×5×192=1.2亿,计算成本比较高。

16个1×1×192过滤器,信道缩小为16个,再5×5卷积得到28×28×32.
先缩小再扩大,中间的部分称为瓶颈层。
运算次数:
第一层:28×28×16×192×1×1=240万;第二层:28×28×32×5×5×16=1000万;总计1240万,与1.2亿相比,只为后者的十分之一。
合理构建瓶颈层,既可以缩小表示层规模又可以不降低网络性能,大量节省了计算时间。
5.2 一个完整的Inception网络
Inception模块会将之前层的激活或输出作为它的输入。
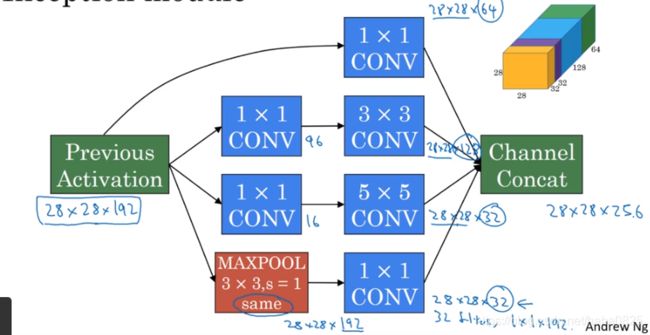

图中有很多重复部分,一部分就是一个Inception模块,其中还有一些MaxPooling来改变宽和高的维度。
还有一些分支(全连接层+softmax),作用为:通过这些组成的隐藏层做出预测。
Inception保证了即使是中间层和隐藏单元也参与了特征计算,并能减少过拟合。
七、使用开放源码(GitHub)
一般自己很难复现别人的论文的代码,而现在大部分论文的代码都放在了GitHub上,当我们自己编写代码时,可以参考作者或者他人的实现。
Google上搜索你先要学习的论文+GitHub,会找到该论文在GitHub上的资源,有一些介绍、代码等。我们可以下载代码来学习。
八、迁移学习
使用别人做出来的开源的权重、参数来作为自己项目的参数的初始化的值。即将公共数据集的问题迁移到自己的问题上。
举个例子:
要识别猫,假设有两种猫,则分类的情况分别为Tigger、Misty、Neither(两个都不是)。假设没有这两种猫出现在同一图片的可能。
若我们的训练集很小,我们可以从网上下载一个图像识别网络的代码和权重,假设是ImageNet的。

我们可以去除它的softmax、然后加上自己的softmax来输出这三种情况。我们需要把前面的层冻结,我们只需要训练和我们的softmax层有关系的层的有关参数。这样即使我们训练集很小,但仍然可以有很好的性能。而大多数深度学习框架都支持这种操作。
另一个技巧是:根据已知参数,先计算训练集中的所有样本的在最后一层的激活值,然后在此基础上训练softmax分类器。这样做的好处是不需要每次都重新计算这个激活值。
若我们的训练数据比较多,这样我们可以冻结更少的层,然后从后面这几层根据已知参数开始梯度下降,或直接去掉这几层换成自己设计的层。
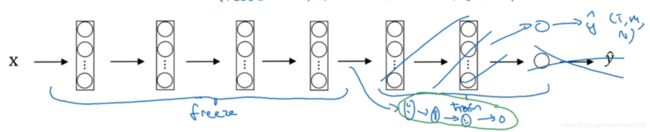
我们有越多的数据就冻结越少的层,自己训练的层越多。

若我们有足够的数据,我们把整个的网络的参数、权重当做自己网络的初始化参数和权重,然后训练整个网络。
因此,除非我们有足够多的数据可以从头开始训练,否则,迁移学习是一个很好的选择。
九、数据扩增
大部分计算机视觉问题都需要大量的数据,而一般情况下,计算机视觉问题的数据都是不够用的,所以数据扩充是经常使用的一种技巧。数据越多,计算机视觉问题解决的越好。
9.1数据扩增方式:
(1)垂直镜像翻转
(2)随机裁剪

一般情况下,随机裁剪并不完美,因为被裁剪的那一部分可能会影响要识别的物体。
(3)旋转、局部弯曲
这部分用的比较少,因为比较复杂。
(4)色彩转换
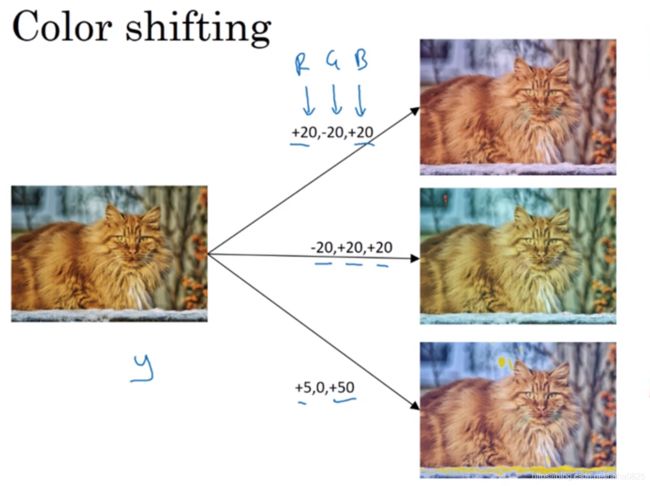
在R、G、B三个通道上加上不同的失真值。实践中,具体的值是根据某种概率分布决定的。
这样做的理由:实际中,可能阳光照得黄或者灯光的颜色使物体颜色变化了。这样做虽然颜色变了,但是并不影响识别物体,增加了对照片颜色更改的鲁棒性。
另外对于颜色变换有一种方法:PCA(主成分分析)
假设一张图片主要是紫色(R和B),G少一点,那么处理会使R和B变化比较多,G变化比较少,按照比例使总体颜色保持一致。
9.2 并行处理
在训练中,假设使图片变形
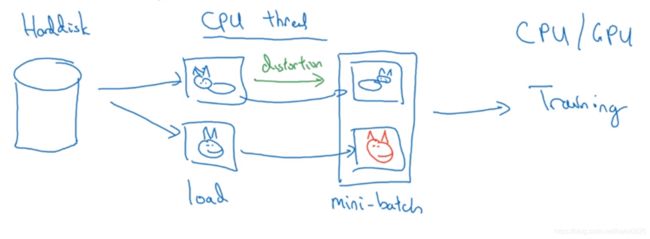
有一数据集存在硬盘上,我们从硬盘读取图片,然后使用CPU来变形,然后保存下来,同时其他线程在GPU上进行训练。
十、计算机视觉技巧
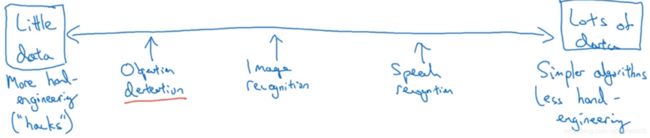
从少数据到多数据依次为目标检测、图像识别、语音识别。
少数据意味着更多的手工工作(设计网络结构、参数、算法等),多数据意味着简单的算法,更少的手工工程。计算机视觉问题通常没有较多的数据,所以更多的依赖手工工作。
计算机视觉问题主要在一些基准测试中(ImageNet、手写数据集等公开的数据集)训练,这可以帮我们找到更好的算法。
下面是一些在基准测试中表现良好的小技巧:
(1)集成
独立的训练几种结构的神经网络,然后平均输出他们的输出。(利用这个错误率会减少1%-2%)
(2)Multi-Croup
一种将数据扩增应用到测试图像的形式,将过滤器运行在图片上的不同部分,然后平均输出。
例如10-Croup:左上角、右上角、左下角、右下角、中间,还有镜像这5个部分,总共10部分。
如果有足够的算力可以更多,20-Croup、30Croup等。

虽然这些方法在基准测试上和比赛上表现很好,但是在实际构建实际应用的系统时不建议使用这些方法。
(3)使用开源资源
1)使用论文中的网络结构。一个网络结构通常也可以解决其他问题。
2)如果可能,可以使用一些开源的代码。
3)使用训练好的模型,然后在自己的训练集上微调。