工作站(集群)使用说明及相关工具
快速入门
登陆方式
工作站只允许已经授权的用户进行登录。在从管理员处获得你的账号名和初始密码后, Linux 或 Mac 用户可直接从命令行登录我们的工作站,使用 ssh 命令即可
ssh username@ip_address
username为管理员给你的账号,ip_address为远程主机的地址
比如:ssh [email protected]对于windows用户,可以使用PuTTY,secureCRT,mobaterm等SSH客户端工具。就个人而言,mobaterm官网地址使用最顺手。
mobaterm使用示例
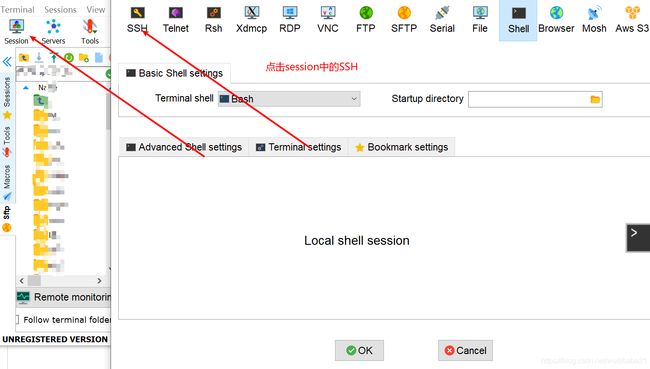

更多使用可以参考mobaterm使用
SLURM脚本---作业调度
SLURM 资源管理系统的管理对象包括:节点,分区,作业和作业步。
-
节点:Node
- 即指计算节点
- 包含处理器、内存、磁盘空间等资源
- 具有空闲、分配、故障等状态
- 使用节点名字标识
-
分区:Partition
- 节点的逻辑分组
- 提供一种管理机制,可设置资源限制、访问权限、优先级等
- 分区可重叠,提供类似于队列的功能
- 使用分区名字标识
-
作业:Job
- 一次资源分配
- 位于一个分区中,作业不能跨分区
- 排队调度后分配资源运行
- 通过作业 ID 标识
-
作业步:Jobstep
- 通过 srun 进行的任务加载
- 作业步可只使用作业中的部分节点
- 一个作业可包含多个作业步,可并发运行
- 在作业内通过作业步 ID 标识
三种模式:srun(交互模式)sbatch(批处理模式) salloc(分配模式)
名为 bcm的主机仅仅为用户提供了登录操作的 平台,但程序的运行需要交给它背后的计算节点们完成。那么如何告诉工作站来运行我们的程序? 我们需要使用作业调度系统 SLURM,它给我们提供了若干运行程序的方式,在本章节 里我们简要介绍最常用的方式:提交 SLURM 作业脚本的批处理方式
man slurm
sacct(1), sacctmgr(1), salloc(1)分配模式, sattach(1), sbatch(1)批处理模式运行, sbcast(1), scan‐
cel(1), scontrol(1), sinfo(1), smap(1), squeue(1), sreport(1), srun(1)交互模式,
sshare(1), sstat(1), strigger(1), sview(1), slurm.conf(5), slurmdbd.conf(5),
slurmctld(8), slurmd(8), slurmdbd(8), slurmstepd(8), spank(8)
上面命令举例说明:
srun将任务分配到运行节点中
srun -n 8 -c 1 --gres=gpu:2 --pty bash
参数说明,-n 任务个数
“ --gres = gpu:2,mic:1”,“-gres = gpu:kepler:2”和“ --gres = help”。 注意:
通用资源,显式设置--gres的值以指定零
每个通用资源的计数或设置为“ --gres = none”或设置为对应数量
-c num 使用cpu数量
--pty bash 进入该节点的终端
-w node02 进入指定节点
squeue查看全部用户任务情况
sacct -S MMDD则会输出从 MM 月 DD 日起的所有历史作业
sacct -S 0916
JobID JobName Partition Account AllocCPUS State ExitCode
------------ ---------- ---------- ---------- ---------- ---------- --------
2635 bash defq users 8 FAILED 6:0
2636 bash defq users 8 COMPLETED 0:0
sinfo查看节点情况
defq* up infinite 1 drng node05
defq* up infinite 3 mix node[01,06-07]
defq* up infinite 2 idle node[02-03]
idle表示空闲,mix表示有任务在跑,但有空闲智源,drng表示无scontrol show jobs 显示作业具体信息
JobId=962 JobName=bash
UserId=zhangtao(1010) GroupId=zhangtao(1010) MCS_label=N/A
Priority=4294901079 Nice=0 Account=users QOS=normal
JobState=RUNNING Reason=None Dependency=(null)
Requeue=1 Restarts=0 BatchFlag=0 Reboot=0 ExitCode=0:0
RunTime=96-11:29:28 TimeLimit=UNLIMITED TimeMin=N/A
SubmitTime=2020-05-14T09:07:43 EligibleTime=2020-05-14T09:07:43
AccrueTime=Unknown
StartTime=2020-05-14T09:07:43 EndTime=Unknown Deadline=N/A
PreemptTime=None SuspendTime=None SecsPreSuspend=0
LastSchedEval=2020-05-14T09:07:43
Partition=defq AllocNode:Sid=bcm:10241
ReqNodeList=(null) ExcNodeList=(null)
NodeList=node05
BatchHost=node05
NumNodes=1 NumCPUs=8 NumTasks=8 CPUs/Task=1 ReqB:S:C:T=0:0:*:*
TRES=cpu=8,node=1,billing=8,gres/gpu=2
Socks/Node=* NtasksPerN:B:S:C=0:0:*:* CoreSpec=*
MinCPUsNode=1 MinMemoryNode=0 MinTmpDiskNode=0
Features=(null) DelayBoot=00:00:00
OverSubscribe=OK Contiguous=0 Licenses=(null) Network=(null)
Command=bash
WorkDir=/home/zhangtao/zy/CFF
Power=
TresPerNode=gpu:2总结起来,在工作站上进行运算的步骤如下:
-
登录主节点,准备程序和数据。
-
编写 SLURM 脚本/进入交互模式,设置作业属性(例如占用的资源,最长运行时间)。
-
检查可用资源,提交作业脚本,检查任务状态(使用 squeue 和 sinfo)。
-
等待运行结束,验收结果。
配置服务器个人运行环境
为了满足同学们计算任务的需求,服务器中安装了各种版本的软件。大家可在同一软件的不同版本之间切换,也可以在同一功能的不同软件之间切换,以此来选择最合适的编程环境和运行环境。使用系统命令 module 可以快速地达到这一效果。
module(可使用module就可弹出来)
Loading / Unloading commands:
add | load modulefile [...] Load modulefile(s)
rm | unload modulefile [...] Remove modulefile(s)
purge Unload all loaded modulefiles
reload | refresh Unload then load all loaded modulefiles
switch | swap [mod1] mod2 Unload mod1 and load mod2
Listing / Searching commands:
list [-t|-l] List loaded modules
avail [-d|-L] [-t|-l] [mod ...] List all or matching available modules
aliases List all module aliases
whatis [modulefile ...] Print whatis information of modulefile(s)
apropos | keyword | search str Search all name and whatis containing str
is-loaded [modulefile ...] Test if any of the modulefile(s) are loaded
is-avail modulefile [...] Is any of the modulefile(s) available
info-loaded modulefile Get full name of matching loaded module(s)
Collection of modules handling commands:
save [collection|file] Save current module list to collection
restore [collection|file] Restore module list from collection or file
saverm [collection] Remove saved collection
saveshow [collection|file] Display information about collection
savelist [-t|-l] List all saved collections
is-saved [collection ...] Test if any of the collection(s) exists
Shell's initialization files handling commands:
initlist List all modules loaded from init file
initadd modulefile [...] Add modulefile to shell init file
initrm modulefile [...] Remove modulefile from shell init file
initprepend modulefile [...] Add to beginning of list in init file
initswitch mod1 mod2 Switch mod1 with mod2 from init file
initclear Clear all modulefiles from init file
Environment direct handling commands:
prepend-path [-d c] var val [...] Prepend value to environment variable
append-path [-d c] var val [...] Append value to environment variable
module avail
blacs/openmpi/gcc/64/1.1patch03 intel-tbb-oss/ia32/2019_20191006oss
blas/gcc/64/3.8.0 intel-tbb-oss/intel64/2019_20191006oss
bonnie++/1.97.3 iozone/3_482
cm-pmix3/3.1.4 keras-py36-cuda10.1-gcc/2.3.1
cuda10.1/blas/10.1.243 lapack/gcc/64/3.8.0
cuda10.1/fft/10.1.243 ml-pythondeps-py36-cuda10.1-gcc/3.0.0
cuda10.1/nsight/10.1.243 mpich/ge/gcc/64/3.3
cuda10.1/profiler/10.1.243 mvapich2/gcc/64/2.3
cuda10.1/toolkit/10.1.243 nccl2-cuda10.1-gcc/2.4.8
cudnn/7.5.0 netcdf/gcc/64/4.6.1
default-environment netperf/2.7.0
fftw2/openmpi/gcc/64/double/2.1.5 openblas/dynamic(default)
fftw2/openmpi/gcc/64/float/2.1.5 openblas/dynamic/0.2.20
fftw3/openmpi/gcc/64/3.3.8 opencv3-py36-cuda10.1-gcc/3.4.7
gcc5/5.5.0 openmpi/cuda/64/3.1.4
gdb/8.2 openmpi/gcc/64/1.10.7
globalarrays/openmpi/gcc/64/5.7 protobuf3-gcc/3.7.1
hdf5/1.10.1 pytorch-py36-cuda10.1-gcc/1.3.0
hdf5_18/1.8.20 scalapack/openmpi/gcc/64/2.0.2
hpcx/2.4.0 sge/2011.11p1
hpl/2.2 slurm/18.08.8
hwloc/1.11.11 tensorflow-py36-cuda10.1-gcc/1.14.0
可以看出集群自带的核心模块数量,可以使用module add+模块名加载或者module initadd+模块名加载(初始化加载)
加载的模块都在~/.bashrc中可以看到
module list查看当前加载的模块
Currently Loaded Modulefiles:
1) slurm/18.08.8 2) cuda10.1/toolkit/10.1.243
删除与替换 module
如果要把某个模块从系统环境中删掉,需要使用
$ module remove
如果要删除全部的模块,可以直接使用$ module purge
一个模块删除之后,你将无法直接使用与之相关的命令。对应软件的执行目录无法被直接访问,或者是还原成系统默认的版本。有的时候,模块之间会有所冲突,你无法在同一时间同时加载两个模块。例如同一软件的不同版本,或者是接口相同的不同软件。当你载入其中一个后,再载入另一个就会出错 使用conda创建属于你自己的虚拟环境
conda info -e查看有哪些虚拟环境
conda activate +虚拟环境名称激活虚拟环境
创建虚拟环境并制定python版本
conda create -n your_env_name python=X.X
conda删除虚拟环境
conda remove -n tf2 --all
使用图形化界面
通常情况下,在集群中我们都在命令行中操作。但是有时我们需要打开某些软件的图形 界面,此时我们需要借助 X11 转发。
注意:在网络不好的时候请谨慎使用此功能,此时经过 X11 转发的界面操作起来有 明显卡顿。尽量在校内有线网或信号较好的无线网的环境下使用
Linux
在 Linux 环境中启用 X11 转发非常简单,只需要在登录时加入 -X 参数。
xxk@laptop: $ ssh -X user@server_ip
此后登录集群可以直接输入命令开启图形界面的程序。例如
matlab
MATLAB is selecting SOFTWARE OPENGL rendering.
firefox
Failed to open connection to "session" message bus: Using X11 for dbus-daemon autolaunch was disabled at compile time, set your DBUS_SESSION_BUS_ADDRESS instead
Running without a11y support!

Windows
使用 MobaXterm
推荐使用 MobaXterm 客户端进行连接。官网地址>>
在默认情况下 MobaXterm 会自动打开 X11 的转发,因此只需正常登录然后直接输入 打开软件的命令即可
传输文件
我们经常会将我们本地的一些文件上传到工作站上,或是从工作站下载文件。这些工作用命令行可以轻松完成。
建议在传输文件之前对要传输的文件进行打包,以便有更高的传输效率。在 Linux 下可以使用 tar 工具进行打包。
$ tar -cjf archive.tar.bz2 folder1/ folder2/
上面的命令是将两个文件夹下的所有文件打包到 archive.tar.bz2 文件中,并进行一定压缩。在工作站打包数据建议使用这个命令。
Windows 用户可以使用 WinRAR 或者 Zip 进行打包。
在服务器中,相应的解包命令为
$ tar -xjf archive.tar.bz2
$ unzip archive.zip
$ unrar e archive.rar
Linux 或 Mac
使用 scp
在命令行中可以使用 scp 命令进行传输文件。这是依赖于 SSH 的一个命令,如果已经配置了 SSH 无密码 登录那么每次复制将不必输入密码。否则,每次传输文件都需要输入密码。
以下命令均在本地计算机中执行。
$ scp file username@ip_address:
$ scp file username@ip_address:Documents/
上面的第一条命令即可将 file 传输到工作站相应账号的 HOME 文件夹下,如果想要指定目录,可以直接写 相对于 HOME 文件夹的路径,例如第二条命令。
如果要使用 scp 命令复制文件夹,需要加上 -r 参数。
$ scp -r folder username@ip_address:
从服务器传输文件到本地只需将两个参数的位置调换。
$ scp username@ip_address:file .
在这里我们使用 . 来表示本地的当前路径。
使用 rsync
rsync 是强大的同步文件的命令行工具,它比 scp 更加智能。rsync 支持从本地到本地, 从本地到服务器,从服务器到本地的文件传输。使用 rsync 访问服务器依赖于 SSH 的 配置。下面的例子假定用户已经配置了 SSH 无密码登录。
传输文件
rsync 基本的传输文件命令为
# 下载文件
rsync [OPTION...] [USER@]HOST:SRC... [DEST]
# 上传文件
rsync [OPTION...] SRC... [USER@]HOST:DEST
其中 SRC 表示来源的路径,DEST 表示目标路径。由于要访问服务器,因此当来源或 目标不是本地时,需要指定服务器的用户和主机名。用户和主机名的指定可以直接使用 SSH 的 .ssh/config 表示的格式。
因此上传可用
# 假设已经配好了 SSH config,server 表示的主机有意义
rsync -avz folder server:
# 如果没有配置 SSH config
rsync -avz folder user@server_ip:
其中的三个选项,a 表示归档模式,在这个模式下传输将递归地进行,并保留文件的 权限信息;v 表示将中间信息输出;z 表示在传输过程中进行压缩来减少传输量。 下载只需要将 SRC 和 DEST 的地位对换。
rsync 的优势在于,每次在传输之前会对文件进行比较,只会传输那些真正改变的文件, 在多数情况下会极大减小传输量。下面是一个例子。
[liuhy@laptop ~]$ ls test/
total 0 # test 文件夹只有三个文件
-rw-rw-r--. 1 liuhy liuhy 0 Jul 1 15:25 1.txt
-rw-rw-r--. 1 liuhy liuhy 0 Jul 1 15:25 2.txt
-rw-rw-r--. 1 liuhy liuhy 0 Jul 1 15:25 3.txt
# 使用 rsync 上传
[liuhy@laptop ~]$ rsync -avz test server:
sending incremental file list
test/
test/1.txt
test/2.txt
test/3.txt
sent 213 bytes received 80 bytes 195.33 bytes/sec
total size is 0 speedup is 0.00
# 创建新文件 4.txt
[liuhy@laptop ~]$ echo "hello world" >> test/4.txt
[liuhy@laptop ~]$ rsync -avz test server:
sending incremental file list
test/
test/4.txt # <- 只上传了这一个文件!
sent 184 bytes received 42 bytes 150.67 bytes/sec
total size is 12 speedup is 0.05
同步时删除
使用 rsync 上传文件时,如果 SRC 的文件比 DEST 的文件要少时,rsync 默认不会去 处理 DEST 多出来的文件。如果要实现真的的完全同步,即删除 DEST 多出来的文件,需要 给 rsync 加上 --delete 选项。
接着上面的例子,在本地删除 1.txt,并告诉服务器也要删除这个文件
[liuhy@laptop ~]$ rm test/1.txt # 删除 1.txt
[liuhy@laptop ~]$ rsync -avz --delete test server:
sending incremental file list
test/
deleting test/1.txt # <- 在做删除操作!
sent 113 bytes received 37 bytes 100.00 bytes/sec
total size is 12 speedup is 0.08
断点续传
rsync 的同步算法只能针对整个的文件。默认情况下,如果文件传输不完整,rsync 会 扔掉这些文件,在下次传输的时候重新处理。当要传输单个大文件时,由于网络等多方面 原因,传输很难一次完成,这时候就需要断点续传功能。
# 使用 rsync 指定 --partial 选项来保留传输未完成的文件
[liuhy@laptop Downloads]$ rsync -avz --partial --progress gcc-7.3.0.tar.xz server:
sending incremental file list
gcc-7.3.0.tar.xz
36,208,640 57% 11.43MB/s 0:00:02 ^CKilled by signal 2.
# ^ 使用 Ctrl+C 强制终止
rsync error: unexplained error (code 255) at rsync.c(638) [sender=3.1.2]
# 指定 --append 选项来传输未完成的文件
[liuhy@laptop Downloads]$ rsync -avz --append --progress gcc-7.3.0.tar.xz server:
sending incremental file list
gcc-7.3.0.tar.xz
62,462,388 100% 11.71MB/s 0:00:02 (xfr#1, to-chk=0/1)
sent 26,481,503 bytes received 34 bytes 7,566,153.43 bytes/sec
total size is 62,462,388 speedup is 2.36
# ^ 注意这是从 57% 开始传的,sent 和 total size 不一样。
将工作站目录挂载到本地
如果不想使用 scp 命令,可以利用 sshfs 将服务器的 HOME 目录挂载到本地。这并不会消耗你本地的存储空间。
首先,使用如下命令安装 sshfs 应用
$ sudo apt install sshfs
其中 apt 是 ubuntu/debian 的安装包管理器,如果你在使用其它 Linux 发行版,请使用相应的安装包管理器进行安装。
安装完毕后,在你喜欢的本地目录下建立挂载点,为了方便,可以选择个人的本地 HOME 文件夹。
$ mkdir workstation
其中 workstation 为挂载点的名称,可以随意填写。
最后,将服务器端的 HOME 文件夹挂载到本地
$ sshfs username@ip_address: workstation
其中 username 为你用户名,ip_address为服务器的地址。上面命令的最后一个 workstation 表示将服务器文件夹挂载到刚创建的挂载点 workstation 上。使用时请将其替换成你实际创建挂载点的路径。
挂载成功后,你可以从挂载点处(在本说明中为本地 HOME 文件夹下的 workstation 目录)直接访问你的服务器远端的目录,非常方便。
当你不需要使用服务器文件时,需要将服务器挂载目录卸载。命令为
$ fusermount -u workstation
其中 workstation 为你事先创建好的挂载点。卸载前请确保本地没有程序在使用远程目录下的文件。
让代码在后台运行
第一种 nohup
nohup python train.py默认会生成nohup.out的日志文件
第二种 screen
可以简单的认为用这个命令你可以为不同的任务开不同的窗口,这个窗口之间是可以切换的,同时,窗口和你的会话连接基本上没有任何区别,这样你可以在开一个连接的时候同时干多件事情,并且在终端看得到运行过程的同时而不会由于断网而导致代码停止运行。其常用命令如下:
screen -S name #创建一个窗口,并且为这个窗口命名
快捷键Ctrl+a+D断开这个窗口的连接而回到连接会话界面
screen -r name #进去那么窗口
kill +pid 或者 进入窗口exit可以完全退出窗口第三种 Tmux : 强烈推荐
很多开发者经常登录到服务器都遇到这些尴尬:
- 想同时打开多个目录不得不开很多终端标签来回切换
- 开了一个 vim 窗口之后,想切到其他目录不得不重新打开个一个终端窗口 ssh 到服务器
- 运行一个脚本,服务器断掉失联之后当前进程被服务器给无情地杀掉,不得不用 nohup 等方式让脚本在后台跑
- 每次 ssh 到服务器都要重新切到工作目录,打开多个进程等,之前的工作记录会丢失
- 鼠标是个伟大的发明,但不幸的是,开发者使用终端的时候在鼠标和键盘之间来回移动和定位,不仅浪费时间,还可能会影响你的思
Tmux 是一个终端复用工具,用于在一个终端窗口中运行多个终端会话。
mux 中有几个重要概念:
- 会话(session): 建立一个 tmux 工作区会话,会话可以长期驻留,重新连接服务器不会丢失,我们只需重新 tmux attach 到之前的工作区就可以恢复会话,这样你的工作区就可以常驻服务器了,非常方便
- 窗口(window): 容纳多个窗格
- 窗格(pane): 可以在窗口中分成多个窗格,每个窗格都可以运行各种命令
这种方式最好!在集群中就算退出,深度学习任务还可以在后台继续跑

查询所有会话(Session)
在命令行输入下列命令查询当前所有会话。
tmux ls
创建会话(Session)
tmux new -s session-name
断开会话(Session)
使用下列命令断开当前会话(断开会话并不影响会话中运行的程序,断开后还可以重新连接)
tmux detach
或者使用tmux中的快捷键
Ctrl+b d(即先使用Ctrl+b快捷键前缀,然后再按d)
重新连接会话(Session)
在命令行输入tmux a即可快速连接第一个所有会话中的第一个。
tmux a
或者通过会话名连接该一个会话
tmux a -t session-name
关闭会话
通过下列命令关闭会话后,会话中的程序也会全部关闭。
tmux kill-session -t session-name
当然你也可以通过直接按Ctrl+d关闭会话、窗口或窗格。
tmux中的快捷键参考
注意以下快捷键适用于tmux会话中,使用前皆需要按下快捷键前缀Ctrl+b。
帮助
? 获取帮助信息
会话(Session)管理
s 列出所有会话
$ 重命名当前的会话
d 断开当前的会话
窗口(Window)管理
c 创建一个新窗口
, 重命名当前窗口
w 列出所有窗口
% 水平分割窗口
“ 竖直分割窗口
n 选择下一个窗口
p 选择上一个窗口
09 选择09对应的窗口
窗格(Pane)管理
% 创建一个水平窗格
“ 创建一个竖直窗格
q 显示窗格的编号
o 在窗格间切换
} 与下一个窗格交换位置
{ 与上一个窗格交换位置
! 在新窗口中显示当前窗格
x 关闭当前窗格