spark SQL入门指南《读书笔记》
文章目录
-
- spark SQL入门指南
- 第一章 初识 spark mysql
-
- 1.1 Spark的诞生 和SparkSQL是什么?
- 1.2 Spark SQL能做什么?
- 第2章 Spark安装、编程环境搭建以及打包提交
-
-
- 运行spark案例:
- 运行pyspark案例
-
- 其他案例
- 第3章 Spark上的RDD(Resilient Distributed Dataset,RDD)编程弹性分布式数据集
-
- 3.1 RDD基础
- 3.2 RDD简单实例—wordcount
- 第4章 Spark SQL编程入门
- 第七章 Spark实战
-
- 基于WIFI探针的商业大数据分析系统(hadoop+spark+hbase+bootstrap+echarts)
- 第八章:Spark SQL实践
-
- 8.1数据清洗
- 8.2 数据处理流程
- 第九章:Spark 优化
-
- 9.2 Spark内存简介
- 9.3 Spark的一些概念
- 9.4 Spark编程四大守则
- 9.5 Spark调优七式
- 9.6 数据倾斜
- 参考:
和同学聊了下,好像现在大家对安全工程师的期待是:
需要懂安全攻防,知道攻击原理,从里面提取特征工程。构建数据运营体系,大数据处理后做数据分析和机器学习模型。
spark SQL入门指南
书籍地址:https://item.jd.com/12319813.html
第一章 初识 spark mysql
1.1 Spark的诞生 和SparkSQL是什么?
spark就是解决MapReduce框架没有分布式内存管理的缺点,解决后者读写中间数据写回到磁盘消耗内存IO的问题。
伯克利大学提出了RDDs(弹性分布式数据集RDDs是一个具有容错性和并行性的数据结构,它可以让我们将中间结果持久化到内存中)
而Spark SQL就是替代Hadoop上Hive能把SQL转成MapReduce作业的过程,并添加了一些功能。
总结为:
MapReduce-> spark
Hadoop->hive->spark sql
1.2 Spark SQL能做什么?
那么Spark SQL到底能做些什么呢?下面我们根据ETL(数据的抽取、转换、加载)的三个过程来讲解一下Spark SQL的作用。
(1)抽取(Extract):Spark SQL可以从多种文件系统(HDFS、S3.本地文件系统等)、关系型数据库(MySQL、Oracle、PostgreSQL等)或NoSQL数据库(Cassandra、HBase、Druid等)中获取数据,Spark SQL支持的文件类型可以是CSV、JSON、XML、Parquet、ORC、Avro等。
(2)转换(Transform):我们常说的数据清洗,比如空值处理、拆分数据、规范化数据格式、数据替换等操作。Spark SQL能高效地完成这类转换操作。
(3)加载(Load):在数据处理完成之后,Spark SQL还可以将数据存储到各种数据源(前文提到的数据源)中。
除了上面这些功能:还能通过JDBC或ODBC以命令行的方式提交分布式数据查询任务。同时Spark SQL还可以和Spark的其他模块搭配使用,完成各种各样复杂的工作。比如和Streaming搭配处理实时的数据流,和MLlib搭配完成一些机器学习的应用。
第2章 Spark安装、编程环境搭建以及打包提交
使用docker的https://github.com/mjhea0/flask-spark-docker会更方便。
目的:在Linux中完成Spark的安装,以及搭建本书后面需要用到的Spark程序的编写环境,并能够将程序打包提交到Spark中运行。
docker-compose up -d
docker-compose ps
http://192.168.199.183:50070/dfshealth.html#tab-startup-progress
http://192.168.199.183:8080/
docker-compose stop. 如果需要停止spark的话
运行spark案例:
touch Readme.md
spark-shell
val lines = sc.textFile("file:///Readme.md")
lines.count() #
运行pyspark案例
参考https://xuxinkun.github.io/2016/08/12/spark-deploy/
from pyspark import SparkContext
sc = SparkContext("local", "Simple App")
distFile = sc.textFile("file:///etc/profile")
print distFile.count()
使用spark-submit提交任务。 local代表本地
spark-submit --master local[2] test.py
其他案例
# For Scala and Java, use run-example:
./bin/run-example SparkPi
# For Python examples, use spark-submit directly:
./bin/spark-submit examples/src/main/python/pi.py
# For R examples, use spark-submit directly:
./bin/spark-submit examples/src/main/r/dataframe.R
第3章 Spark上的RDD(Resilient Distributed Dataset,RDD)编程弹性分布式数据集
目的:
Spark为程序员提供的便利就在于此,隐藏Spark底层各节点通信、协调、容错细节,成功地让程序员在Spark上采用类似往常单机编程那样的模式,就可以轻松操控整个集群进行数据挖掘。
3.1 RDD基础
Spark中的RDD就是一个不可变的分布式对象集合。每个RDD都被分为多个分区(partitions),这些分区被分发到集群中的不同节点上进行计算。RDD可以包含Python、Java、Scala中任意类型的对象,甚至可以包含用户自定义的对象。
3.1.1 RDD创建:
两种方式,读取一个外部数据集,或在驱动程序里转化驱动程序中的对象集合(比如list和set)为RDD。
转化
3.1.2 RDD转化操作、行动操作
创建出来后,RDD支持两种类型的操作:转化操作(transformations)和行动操作(actions)。
3.1.3 惰性求值
就是优化策略,先不做转化,根据操作对象决定转化的对象多少。
3.1.4 缓存
缓存使用多次的部分数据到内存或者磁盘。以时间换空间。

3.2 RDD简单实例—wordcount
参考:http://dblab.xmu.edu.cn/blog/986-2/
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object WordCount {
def main(args: Array[String]) {
val inputFile = "file:///usr/local/spark/mycode/wordcount/word.txt"
val conf = new SparkConf().setAppName("WordCount")
val sc = new SparkContext(conf)
val textFile = sc.textFile(inputFile)
val wordCount = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)//三个转化操作
wordCount.foreach(println)
}
}
第4章 Spark SQL编程入门
基本步骤总结起来就是:Spark程序中利用SparkSession对象提供的读取相关数据源的方法读取来自不同数据源的结构化数据,转化为DataFrame,当然也可以将现成RDDs转化为DataFrame,在转化为DataFrame的过程中,需自识别或指定DataFrame的Schema,之后可以直接通过DataFrame的API进行数据分析,当然也可以直接将DataFrame注册为table,直接利用Sparksession提供的sql方法在已注册的表上进行SQL查询,DataFrame在转化为临时视图时需根据实际情况选择是否转化为全局临时表
第七章 Spark实战
参考:https://www.pianshen.com/article/4911801253/
代码:https://github.com/wanghan0501/WiFiProbeAnalysis
基于WIFI探针的商业大数据分析系统(hadoop+spark+hbase+bootstrap+echarts)
第八章:Spark SQL实践
8.1数据清洗
数据预处理过程主要使用对MAC和时间的循环实现。首先,使用读入的文件建立全局临时视图。
搜索表里所有记录的mac对应时间,按时间排序,计算驻留时间。最后得到结果。
package com.cjs
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import scala.collection.mutable.ListBuffer
/**
* 数据清洗
* 原始hdfs的数据形式:{"tanzhen_id":"00aabbce","mac":"a4:56:02:61:7f:1a","time":"1492913100","rssi":"95","range":"1"}
* 转换成新形式:{"mac":"a4:56:02:61:7f:1a","in_time":"xxxxxx","out_time":"xxxxxx","stay_time":"xxxxxx"}
*/
object new_customer_extract {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.set("spark.some.config.some","some-value")
val ss = SparkSession
.builder()
.config(conf)
.appName("custome_extract")
.getOrCreate()
import java.io._
val writer = new PrintWriter(new File("/spark_data/visit_records.json"))
//读取源文件
val hdfs_path = "hdfs://master:9000/log1/log.log"
val df = ss.read.json(hdfs_path)
df.createOrReplaceTempView("data")
ss.sql("cache table data")
//获取所有用户的MAC,得到的是一个Array[Row]对象
val macArray = ss.sql("select distinct mac from data").collect()
//遍历每一个MAC
for (mac <- macArray) {
//mac是一个Row对象
var resultString = ""
var sql = "select 'time' from data where mac = '" + mac(0) + "'order by 'time'"
val timeArray = ss.sql(sql).collect()
//将timeArray转换成List
var timeList = new ListBuffer[Int]
for (time <- timeArray) {
timeList += time(0).toString.toInt
}
var oldTime = 0
var newTime = 0
var startTime = 0
var leaveTime = 0
//最大时间间隔,表示若相邻两次时间超过这一时间,则认为这两个时间构成一次访问
val maxVistTimeInterval = 300
var k=0
//遍历当前mac用户的time集合
while(k < timeArray.length) {
if (k == 0) {
//第一次遍历
oldTime = timeList(0)
newTime = timeList(0)
startTime = timeList(0)
}else if (k == timeArray.length-1) {
//最后一次遍历
leaveTime = timeList(k)
var stayTime = leaveTime - startTime
resultString +=
s""""{"mac":${mac},"in_time":${startTime},"out_time":${leaveTime},"stay_time"${stayTime}}\n""".stripMargin
}else{
newTime = timeList(k)
if ((newTime-oldTime)>maxVistTimeInterval) {
//相邻两次访问间隔大于分割阈值,则认为可以划分一次访问
leaveTime = newTime
var stayTime = leaveTime - startTime
resultString =
s"""{"mac":${mac},"in_time":${startTime},"out_time":${leaveTime},"stay_time":${stayTime}}\n""".stripMargin
startTime = newTime
}
oldTime = newTime
}
k+=1
}
//将结果集写入文件
writer.write(resultString)
}
//关闭文件
writer.close()
ss.sql("uncache table data")
}
}
需要注意的是,Spark读入文件时会将JSON数据中的值都归纳为[Any]类型,所以在使用字符串时需要调用toString方法,使用数值类型则需要先调用toString再调用toInt/toFloat/toDouble方法转换为相应的类型。
8.2 数据处理流程
在上一节中,我们完成了数据的初步处理,接下来我们将使用这些冗余较小的数据计算以下指标:
客流量:店铺或区域整体客流及趋势。
入店量:进入店铺或区域的客流及趋势。
入店率:通俗一点讲就是在单位时间内,从店铺门口经过的客流量与进入店铺内的客流量的比率。来访周期:进入店铺或区域的顾客距离上次来店的间隔。
新老顾客:一定时间段内首次/两次以上进入店铺的顾客。顾客活跃度:按顾客距离上次来访间隔,划分为不同活跃度(高活跃度、中活跃度、低活跃度、沉睡活跃度)。
驻店时长:进入店铺的顾客在店内的停留时长。跳出率:进入店铺后很快离店的顾客及占比(占总体客流)。
深访率:进入店铺深度访问的顾客及占比(占总体客流)。
package com.cjs
import org.apache.spark.SparkConf
import org.apache.spark.sql.{Row, SparkSession}
import scala.util.control.Breaks
/**
* 每天深访率:进入店铺深度访问的顾客占比(占总体客流)
* 平均访问时间
* 新、老顾客数
* 访客总数等指标
*/
object base_day_analyse {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.set("spark.some.config.some","some-value")
val ss = SparkSession
.builder()
.config(conf)
.appName("base day analyse")
.getOrCreate()
val path = "/spark_data/visit_records.json" //经过数据清洗后的数据文件,字段包括{mac:标识不同的用户,in_time:用户进店时间,out_time:用户离开店的时间,stay_time:用户停留时间}
val vistiRDF = ss.read.json(path)
vistiRDF.createOrReplaceTempView("visit")
ss.sql("cache table visit")
var resultStr = ""
val sql = "select in_time from visit order by 'in_time'"
val timeArr = ss.sql(sql).collect()
//初始化时间
val minTime = timeArr(0)(0).toString.toInt
val maxTime = timeArr(timeArr.length-1)(0).toString.toInt
var nowTime = minTime
var outer = new Breaks
var lastCustomerNum = 0
var nowCustomerNum = 0 //当前总客户
var newCustomerNum = 0 //新客户
var oldCustomerNum = 0 //老客户
var intervalCustomerNum = 0 //一天的访客量
while (nowTime<=maxTime) {
outer.breakable{ //异常捕捉
var jumpNum = 0 //3分钟内,离开店铺的用户数量
var visitNum = 0 //当天访问的数量
var deepInNum = 0 //逗留时间超过半个小时的用户数量,深访数量
var avgStayTime = 0 //当天内,平均每次访问逗留的时间
var time1 = nowTime //起始时间
var time2 = nowTime+86400 //起始时间开始后的一天时间,86400 = 24*60*60
//一天的访客量的sql
var sqlTmp =
s"""
|select count(distinct mac) as num from visit
| where 'in_time' between ${time1} and ${time2}
| and stay_time > 0
""".stripMargin
intervalCustomerNum = (ss.sql(sqlTmp).collect())(0)(0).toString.toInt
//一开始到当前时间的一天后的访客量
sqlTmp =
s"""
|select count(distinct mac) as num from visit
| where 'in_time' between ${minTime} and ${time2}
| and stay_time > 0
""".stripMargin
nowCustomerNum = (ss.sql(sqlTmp).collect())(0)(0).toString.toInt
//sql用了distinct,所以intervalCustomerNum >= newCustomerNum
newCustomerNum = nowCustomerNum - lastCustomerNum
oldCustomerNum = intervalCustomerNum - newCustomerNum
//当天时间里面,3分钟(180秒)内离开店铺的用户的数量,跳出数量
sqlTmp =
s"""
|select count(*) as jump_num from visit
| where 'in_time' between ${time1} and ${time2}
| and stay_time <= 180
""".stripMargin
jumpNum = (ss.sql(sqlTmp).collect())(0)(0).toString.toInt
//当天时间里面,超过半个小时(1200秒)才离开店铺的用户的数量,深访数量
sqlTmp =
s"""
|select count(*) as deep_in_num from visit
| where 'in_time' between ${time1} and ${time2}
| and stay_time >= 1200
""".stripMargin
deepInNum = (ss.sql(sqlTmp).collect())(0)(0).toString.toInt
sqlTmp =
s"""
|select count(*) as visit_num, avg(stay_time) as avg_stay_time from visit
| where 'in_time' between ${time1} and ${time2}
""".stripMargin
val row = (ss.sql(sqlTmp).collect())(0).asInstanceOf[Row]
visitNum = row.getInt(0)
avgStayTime = row.getInt(1)
//跳出率
var jumpRate = jumpNum.toFloat / visitNum.toFloat
//深访率
var deepInRate = deepInNum.toFloat / visitNum.toFloat
//标准化格式
var formatJumpRate = f"${jumpRate%1.2f}"
var formatDeepInRate = f"${deepInRate%1.2f}"
var dayString =
s"""{"time":${time1},"jump_out_rate":${formatJumpRate},"deep_in_rate":${formatDeepInRate},"avg_stay_time":${avgStayTime},"new_num":${newCustomerNum},"old_num":${oldCustomerNum},"customer_num":${visitNum}}\n""".stripMargin
resultStr += dayString
nowTime = time2
lastCustomerNum = nowCustomerNum
}
}
//将结果存进文件
import java.io._
val targetPath = "/spark_data/base_day_analyse.json"
val writer = new PrintWriter(new File(targetPath))
writer.write(resultStr)
writer.close()
ss.sql("uncache table visit")
}
}
package com.cjs
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import scala.util.Random
import scala.util.control.Breaks
/**
* 实时客流量,实际上是每60秒统计一次访客量
*/
object simulation_data_flow_analyse {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.set("spark.some.config.some","some-value")
val ss = SparkSession
.builder()
.config(conf)
.appName("simulation_data_flow_analyse")
.getOrCreate()
val path = "/spark_data/visit_records.json" //经过数据清洗后的数据文件,字段包括{mac:标识不同的用户,in_time:用户进店时间,out_time:用户离开店的时间,stay_time:用户停留时间}
val vistiRDF = ss.read.json(path)
vistiRDF.createOrReplaceTempView("visit")
ss.sql("cache table visit")
var resultStr = ""
val sql = "select in_time from visit order by 'in_time'"
val timeArr = ss.sql(sql).collect()
//初始化时间
val minTime = timeArr(0)(0).toString.toInt
val maxTime = timeArr(timeArr.length-1)(0).toString.toInt
var nowTime = minTime
var outer = new Breaks
while (nowTime<=maxTime) {
outer.breakable{
var comeNum = 0
var time1 = nowTime
var time2 = nowTime + 60
var sqlTmp =
s"""
|select count(*) as num from visit
| where 'in_time' between ${time1} and ${time2}
| and stay_time > 0
""".stripMargin
comeNum = (ss.sql(sqlTmp).collect())(0)(0).toString.toInt
if (comeNum==0) {
nowTime += 60
outer.break() //结束本次outer
}
var flowNum = comeNum
var time = time1
var rand = new Random
var i = rand.nextInt(7)+4
flowNum *= i
var visitStr = s"""{"time":${time},"num":${flowNum}}\n""".stripMargin
resultStr += visitStr
nowTime = time2
}
}
//将结果存进文件
import java.io._
val targetPath = "/spark_data/people_flow.json"
val writer = new PrintWriter(new File(targetPath))
writer.write(resultStr)
writer.close()
ss.sql("uncache table visit")
}
}
以上就是项目的全部代码,几个处理过程结构大致相同,基本就是读取元数据并打开输出文件→处理数据→将结果写入文件并关闭文件。在这种结构中,我们可以相对自由地改变程序的执行过程。
第九章:Spark 优化
了解Spark的执行流程、Spark的内存分布以及如何划分stage。本章的大半部分内容将主要讲解如何对Spark程序进行优化,重点放在优化思路上。
Spark把代码(发送给SparkContext的jar或者Python文件中的代码)发送到executors上。最后SparkContext发送tasks到executors上运行。
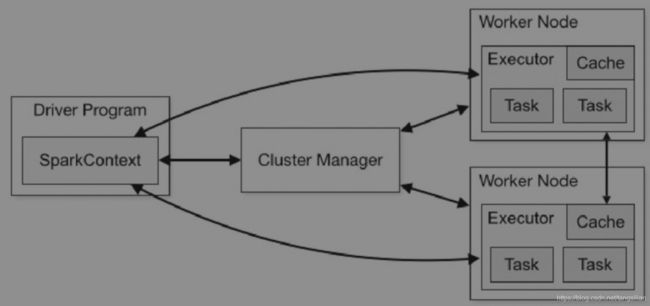
- 1.各spark任务中数据不共享
在executors这一端,不同应用的task运行在不同的JVM里面。这意味着不同Spark应用程序的数据不能互相共享,除非将数据写入到硬盘中。 - 2.底层的集群资源管理器对于Spark来说是透明的
只要Spark能获得executor进程,能相互通信就行。正是因为这个原因,所以Spark能在其他的集群资源管理器上运行,比如YARN和Mesos。 - 一个Spark应用程序由一个driver进程和多个executor组成(分布在集群中)。driver安排工作,executor以task的形式响应并且执行这些工作,如图9-2所示。

9.2 Spark内存简介
Spark中的内存大部分是Storage内存和Execution内存。
Execution内存:用于shuffle、join、sort、aggregation这些计算操作。Storage内存:用于缓存数据,以及存放一些元数据。在Spark中,Storage内存和Execution内存共享同一块区域。
9.3 Spark的一些概念
(1)Spark应用程序作为独立的进程集运行在集群上,通过主程序(也被称为驱动程序,含有main()方法,并且在里面创建了SparkContext实例)的SparkContext对象来协调,SparkContext在一个驱动程序中只能有一个实例。
(2)job包含许多的task (也许翻译为工作单元比较合适),job可以切分成一组一组的task,切分之后的一组task被称为stage。
(3)数据在执行的过程中被会切分为一块一块,称之为partition,一个task处理一个partition。
9.4 Spark编程四大守则
1.编程守则一:避免创建重复的DataFrame
2.编程守则二:避免重复性的SQL查询,对DataFrame复用
3.编程守则三:注意数据类型的使用
4.编程守则四:写出高质量的SQL
9.5 Spark调优七式
9.6 数据倾斜
我们知道在进行shuffle的时候会将各个节点上key相同的数据传输到同一结点进行下一步的操作。如果某个key或某几个key下的数据的数据量特别大,远远大于其他key的数据,这时就会出现一个现象,大部分task很快就完成结束,剩下几个task运行特别缓慢。甚至有时候还会因为某个task下相同key的数据量过大而造成内存溢出。这就是发生了数据倾斜。
解决方式:
1.调整分区数目
2.去除多余的数据
3.使用广播将reduce join转化为map join
4.将key进行拆分,大数据化小数据
参考:
https://www.jianshu.com/p/ee210190224f
Hive表是什么?
hive是基于Hadoop构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop分布式文件系统中的数据:可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能;