37、递推算法、分治算法入门和算法复杂度
这节课是整个青少年Python编程系列讲解的最后一节课了。前面一节课我们讲了排序算法和查找算法,这节课我们了解一下递推算法和分治算法,以及算法复杂度的概念。算法还有很多,比如分型算法、聚类算法、预测算法、调度算法、路径算法等等,我们就不再展开讲了,大家有兴趣的可以自己进行研究,算法部分的内容为这里是给大家开一个头。下面正式开始这一讲的内容吧。
一、递推算法
递推是序列计算中的一种常用算法。它是按照一定的规律来计算序列中的每一项,通常是通过前面一些项的得到序列中指定项的值。
我们举一个例子:
有一组小朋友,第1位小朋友说自己比第2位小朋友多2块糖,第2位小朋友说自己比第3位小朋友多2块糖,第3位小朋友说自己比第4位小朋友多2块糖……最后问到第6位小朋友的时候,他说自己有3块糖。请问第1位小朋友有几块糖?
我们假设第1个位小朋友有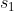 块糖,想要知道是多少,需要从第6位小朋友的糖的个数
块糖,想要知道是多少,需要从第6位小朋友的糖的个数![]() 着手。根据多2块糖这个规律,我们可以按顺序逐步推算:
着手。根据多2块糖这个规律,我们可以按顺序逐步推算:
![]()
![]()
![]()
![]()
![]()
![]()
根据上面的规律,我们可以得到递推公式: s = s + 2,初始条件s = 1,通过5次计算就可以得到答案。得到算法后,我们转换为Python的代码如下:
s = 3
for i in range(1, 6):
k += 2
print(k)同样的道理,使用递推算法也可以计算斐波拉契数列的前n项。斐波拉契数列在讲Python中函数的递归调用时我们曾经讲过。我们这里复习一下:
斐波拉契数列也叫“黄金分割数列”,数列从0和1开始,从第三项起,每一项都等于前两项之和。数列的前n项包括:0,1,1,2,3,5,8,13,21,…。在数学上,斐波拉契数列以递归的方法来定义:
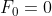
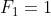

我们分析一下:
假设a和b是斐波拉契数列的前2项,那么a = 0,b = 1。
第三项c = a + b。
第四项是第二项和第三项的和。
我们得到通用公式为c = a + b。那此时的a从哪里来,b又从哪里来的呢?
通过分析我们知道,a是上次的b,而b是上次的c。
根据递推的分析,我们得到斐波拉契数列的Python代码如下:
a, b = 0, 1
n = int(input()) # 前n项
print(a, b, end=' ')
if n > 2:
for i in range(3, n + 1):
c = a + b
a = b
b = c
print(c, end=' ')看到这里,有同学会有一个疑问,好像使用递推解决的问题完全可以使用函数的递归调用解决,那为什么要学习递推算法呢?
大家可以做一个实验,分别使用递归的方法和递推的方法求斐波拉契数列的前1000项,看看会有什么效果。递归的方法程序运行一会儿就动不了了,而递推的方法程序不到1秒就计算出结果了。
当递归深度太深时,可尝试用递推解决。当递推顺序不明显的情况下,可利用递归的方式解决。递归结构清晰、可读性强、目的性强,但容易函数栈溢出或超时;递推速度较快、比较灵活,但有时思路不易想到。
二、分治算法
分治思想的核心思想是:先分再治再合。分治算法的实现离不开函数的递归调用。
- 分:将一个复杂的问题分成两个或多个相同或相似的子问题,再把子问题分成更小的子问题。
- 治:最后子问题可以简单地直接求解。
- 合:将所有子问题的解合起来就是原问题的解。
分治算法的特征有如下几点:
- 问题的规模小到一定的程度就可以解决。
- 问题可以分解成若干个规模较小的相同问题。
- 问题分解出的子问题的解可以合并为该问题的解。
- 问题所解出的各个子问题是相互独立的,即子问题之间不包含公共的子子问题。
下面我们看一下分治算法的典型案例:快速排序。快速排序是对冒泡排序的一种改进。它的基本思想是通过一遍排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另一部分的所有数据小,然后再按此方法对这两部分数据分别进行快速排序。整个排序过程可以递归进行,最后所有的数据变成有序序列。
快速排序通过多次比较和交换来实现排序,它的流程如下:
- 设定一个分界值,通过该分界值将序列数据分成左右两部分
- 将大于或等于分界值的数据集中到右边,小于分界值的数据集中到左边。此时,左边各个元素的值都小于或等于分界值,右边各个元素的值都大于或等于分界值
- 左边和右边的数据进行独立排序。对左边的数据、右边的数据分别取一个分界值,再将它分成左右两个部分。同样得到左边是较小值,右边是较大值
- 重复上述步骤,递归执行。当所有分割出来的序列都排好序了,整个序列就排序完成了。
假设对一个长度为n的序列a进行排序,快速排序的算法如下所示:
- 设置两个变量i、j,排序开始时,i = 0, j = n - 1
- 以第一个元素作为关键数据,将其赋值给key,即key = a[0]。
- 从j开始向前搜索,即由后向前搜索,找到第一个小于key的值a[j],将a[j]和a[i]的值互换
- 从i开始向后搜索,即由前向后搜索,找到第一个大于key的值a[i],将a[i]与a[j]的值互换
- 重复3、4这两步,直到i = j;第3、4步如果没有找到符合条件的值,即第3步中a[j]不小于key,第4步中a[i]不大于key,改变j、i的值,使得j = j - 1,i = i + 1,直到找到为止。找到符合条件的值,进行交换时,i、j指针位置不变。另外,如果i和j的值相等,说明此次循环结束。
按照这样的思路,我们可以得到快速排序的Python代码:
def quick_sort(data, begin, end):
if begin < end:
q = partion(data, begin, end)
quick_sort(data, begin, q)
quick_sort(data, q + 1, end)
def partion(data, begin ,end):
i = begin - 1
for j in range(begin, end):
if data[j] <= data[end]:
i += 1
data[i], data[j] = data[j], data[i]
data[i+1], data[end] = data[end], data[i+1]
return i
list1 = [6, 5, 3, 2, 1, 7, 0, 9]
quick_sort(list1, 0, len(list1) - 1)
print(list1)三、算法复杂度
3.1 时间复杂度
一般情况下,算法中基本操作重复执行的次数是问题规模n的某个函数f(n),算法的时间度量记作T(n) = O(f(n)),它表示随时间规模n的增大,算法执行时间的增长率和f(n)的增长关系,称作算法的渐进时间复杂度,简称时间复杂度。
时间复杂度T(n)按数量级递增的顺序为:
| 常数阶 | 对数阶 | 线性阶 | 线性对数阶 | 平方阶 | …… | k次方阶 | 指数阶 |
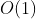 |
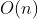 |
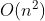 |
…… | 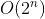 |
|||
| 复杂度低 → 复杂度高 | |||||||
我们用几个实例看一下时间复杂度:
print('1')
print('2')
print('3')以上代码中3条输出语句,执行了3次。这个代码的时间复杂度为O(1)。
s = 0
for i in range(100):
s += i
print(s)以上代码中,循环100次,执行了100次,属于线性阶,算法复杂度为O(n)。
s = 0
for i in range(100):
for j in range(i, 100):
s += j
print(s)以上代码中,代码执行的次数为![]() ,即
,即![]() 次。我们保留最高此项,得到时间复杂度为。
次。我们保留最高此项,得到时间复杂度为。
n = 1024
i = 0
while n > 1:
n = n // 2
i += 1
print(i)以上代码中,执行的次数为x,![]() ,所以时间复杂度为
,所以时间复杂度为![]()
讲到这里,我们来总结一下我们前面学习的几种算法的时间复杂度:
| 冒泡排序 | |
| 选择排序 | |
| 插入排序 | |
| 快速排序 | |
| 顺序查找 | |
| 对分查找 |
3.2 空间复杂度
空间复杂度是指算法被编写成程序后,在计算机中运行所需存储空间的大小的度量。记作S(n)=O(f(n)),其中n为问题的规模或大小。
存储空间一般包括3个部分:
- 输入数据所占用的存储空间
- 指令、变量等所占用的存储空间
- 辅助(存储)空间
算法的空间复杂度一般指的是辅助空间。
比如长度为n的列表,空间复杂度为O(n),长度为n列表,每个元素为长度为m的列表的二维数据,空间复杂度为O(n×m)。
四、课后思考题
1、选择题
在Python中随机产生一个1到1000的整数,使用二分查找法猜测这个数的值,最多要猜多少次?
A. 7 B. 8 C. 9 D. 10
2、判断题
若果一个问题的求解既可以使用递归,也可以使用递推,则往往采用递归求解
3、编程题
使用分治算法编写一个程序,给一个列表,求出其中的最大值。
五、上节课思考题答案
1、A
2、C
3、C
六、本节课思考题答案(选中查看)
1、D
2、错
3、参考代码:
def get_max(nums=list):
return max(nums)
def solve(nums):
n = len(nums)
if n <= 2:
return(get_max(nums))
left_list, right_list = nums[:n//2], nums[n//2:]
left_max, right_max = solve(left_list), solve(right_list)
return(get_max([left_max, right_max]))
list1 = [23, 12, 42, 12, 11, 9, 32, 39, 23]
print(solve(list1))