【PyTorch】4.1 权值初始化
目录
1.梯度消失与爆炸
2.Xavier方法与Kaiming方法
2.1Xavier初始化
2.2Kaiming初始化
3.常用初始化方法
任务简介:学习权值初始化的原理;
详细说明:
本节学习权值初始化的必要性,首先分析神经网络中权值的方差过大导致梯度爆炸的原因,然后从方差一致性原则出发分析Xavier初始化方法与Kaiming初始化方法的由来,最后介绍pytorch提供的十种初始化方法。
1.梯度消失与爆炸

代码:
import os
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
import torch
import random
import numpy as np
import torch.nn as nn
path_tools = os.path.abspath(os.path.join(BASE_DIR, "..", "..", "tools", "common_tools.py"))
assert os.path.exists(path_tools), "{}不存在,请将common_tools.py文件放到 {}".format(path_tools, os.path.dirname(path_tools))
import sys
hello_pytorch_DIR = os.path.abspath(os.path.dirname(__file__)+os.path.sep+".."+os.path.sep+"..")
sys.path.append(hello_pytorch_DIR)
from tools.common_tools import set_seed
set_seed(1) # 设置随机种子
class MLP(nn.Module):
def __init__(self, neural_num, layers):
super(MLP, self).__init__()
self.linears = nn.ModuleList([nn.Linear(neural_num, neural_num, bias=False) for i in range(layers)])
self.neural_num = neural_num
def forward(self, x):
for (i, linear) in enumerate(self.linears):
x = linear(x)
return x
def initialize(self):
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.normal_(m.weight.data)
# nn.init.normal_(m.weight.data, std=np.sqrt(1/self.neural_num)) # normal: mean=0, std=1
# a = np.sqrt(6 / (self.neural_num + self.neural_num))
#
# tanh_gain = nn.init.calculate_gain('tanh')
# a *= tanh_gain
#
# nn.init.uniform_(m.weight.data, -a, a)
# nn.init.xavier_uniform_(m.weight.data, gain=tanh_gain)
# nn.init.normal_(m.weight.data, std=np.sqrt(2 / self.neural_num))
# nn.init.kaiming_normal_(m.weight.data)
# flag = 0
flag = 1
if flag:
layer_nums = 100
neural_nums = 256
batch_size = 16
net = MLP(neural_nums, layer_nums)
net.initialize()
inputs = torch.randn((batch_size, neural_nums)) # normal: mean=0, std=1
output = net(inputs)
print(output)
# ======================================= calculate gain =======================================
flag = 0
# flag = 1
if flag:
x = torch.randn(10000)
out = torch.tanh(x)
gain = x.std() / out.std()
print('gain:{}'.format(gain))
tanh_gain = nn.init.calculate_gain('tanh')
print('tanh_gain in PyTorch:', tanh_gain)输出:
tensor([[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
...,
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan]], grad_fn=)
发现这个网络的输出的值很大,出现了nan的情况。查看在那一层出现了梯度爆炸,代码:
def forward(self, x):
for (i, linear) in enumerate(self.linears):
x = linear(x)
# x = torch.relu(x)
print("layer:{}, std:{}".format(i, x.std()))
if torch.isnan(x.std()):
print("output is nan in {} layers".format(i))
break
return x输出:
发现在31层的时候出现了梯度爆炸。
layer:0, std:15.959932327270508
layer:1, std:256.6237487792969
layer:2, std:4107.24560546875
layer:3, std:65576.8125
layer:4, std:1045011.875
layer:5, std:17110408.0
layer:6, std:275461440.0
layer:7, std:4402537984.0
layer:8, std:71323615232.0
layer:9, std:1148104736768.0
layer:10, std:17911758454784.0
layer:11, std:283574813065216.0
layer:12, std:4480599540629504.0
layer:13, std:7.196813845908685e+16
layer:14, std:1.1507761512626258e+18
layer:15, std:1.8531105202862293e+19
layer:16, std:2.9677722308204246e+20
layer:17, std:4.780375660819944e+21
layer:18, std:7.61322258007914e+22
layer:19, std:1.2092650667673597e+24
layer:20, std:1.923256845372055e+25
layer:21, std:3.134466694721031e+26
layer:22, std:5.014437175989598e+27
layer:23, std:8.066614199776408e+28
layer:24, std:1.2392660797937701e+30
layer:25, std:1.9455685681908206e+31
layer:26, std:3.02381787247178e+32
layer:27, std:4.950357261592001e+33
layer:28, std:8.150924034825315e+34
layer:29, std:1.3229830735592165e+36
layer:30, std:2.0786816651036685e+37
layer:31, std:nan
output is nan in 31 layers
tensor([[ inf, -2.6817e+38, inf, ..., inf,
inf, inf],
[ -inf, -inf, 1.4387e+38, ..., -1.3409e+38,
-1.9660e+38, -inf],
[-1.5873e+37, inf, -inf, ..., inf,
-inf, 1.1484e+38],
...,
[ 2.7754e+38, -1.6783e+38, -1.5531e+38, ..., inf,
-9.9440e+37, -2.5132e+38],
[-7.7183e+37, -inf, inf, ..., -2.6505e+38,
inf, inf],
[ inf, inf, -inf, ..., -inf,
inf, 1.7432e+38]], grad_fn=)
相关公式推导:
期望:E(X),E(Y)
方差:
![]()
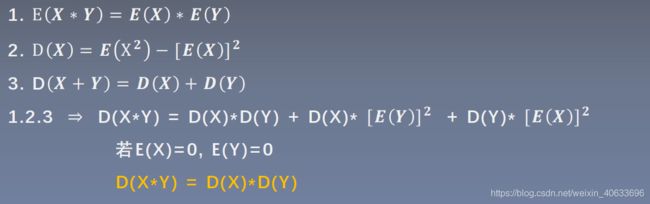
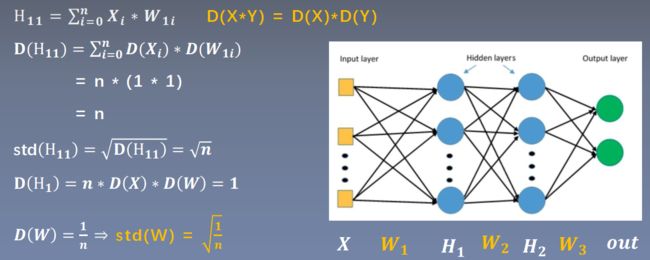
每经过一次前向传播,方差扩大n倍,标准差扩大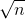 倍。
倍。
为了让网络层尺度不变,让方差一直等于1(只有1可以保证任意个数相乘还是为1)。即,初始化权重W的标准差为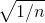 。
。
设置:
nn.init.normal_(m.weight.data, std=np.sqrt(1/self.neural_num)) # normal: mean=0, std=1输出:
输出的值在合适的范围之内,并且标准差都在1左右,说明公式推导正确。
layer:0, std:0.9974957704544067
layer:1, std:1.0024365186691284
layer:2, std:1.002745509147644
layer:3, std:1.0006227493286133
layer:4, std:0.9966009855270386
layer:5, std:1.019859790802002
layer:6, std:1.0261738300323486
layer:7, std:1.0250457525253296
layer:8, std:1.0378952026367188
layer:9, std:1.0441951751708984
layer:10, std:1.0181655883789062
......
layer:94, std:1.031973123550415
layer:95, std:1.0413124561309814
layer:96, std:1.0817031860351562
layer:97, std:1.1287994384765625
layer:98, std:1.1617799997329712
layer:99, std:1.2215300798416138
tensor([[-1.0696, -1.1373, 0.5047, ..., -0.4766, 1.5904, -0.1076],
[ 0.4572, 1.6211, 1.9660, ..., -0.3558, -1.1235, 0.0979],
[ 0.3909, -0.9998, -0.8680, ..., -2.4161, 0.5035, 0.2814],
...,
[ 0.1876, 0.7971, -0.5918, ..., 0.5395, -0.8932, 0.1211],
[-0.0102, -1.5027, -2.6860, ..., 0.6954, -0.1858, -0.8027],
[-0.5871, -1.3739, -2.9027, ..., 1.6734, 0.5094, -0.9986]],
grad_fn=)
添加激活函数,代码:
def forward(self, x):
for (i, linear) in enumerate(self.linears):
x = linear(x)
x = torch.tanh(x)
print("layer:{}, std:{}".format(i, x.std()))
if torch.isnan(x.std()):
print("output is nan in {} layers".format(i))
break
return x
输出:
标准差越来越小,甚至到梯度消失的情况。
layer:0, std:0.6273701786994934
layer:1, std:0.48910173773765564
layer:2, std:0.4099564850330353
layer:3, std:0.35637012124061584
layer:4, std:0.32117360830307007
layer:5, std:0.2981105148792267
layer:6, std:0.27730831503868103
......
layer:94, std:0.07276967912912369
layer:95, std:0.07259567826986313
layer:96, std:0.07586522400379181
layer:97, std:0.07769151031970978
layer:98, std:0.07842091470956802
layer:99, std:0.08206240087747574
tensor([[-0.1103, -0.0739, 0.1278, ..., -0.0508, 0.1544, -0.0107],
[ 0.0807, 0.1208, 0.0030, ..., -0.0385, -0.1887, -0.0294],
[ 0.0321, -0.0833, -0.1482, ..., -0.1133, 0.0206, 0.0155],
...,
[ 0.0108, 0.0560, -0.1099, ..., 0.0459, -0.0961, -0.0124],
[ 0.0398, -0.0874, -0.2312, ..., 0.0294, -0.0562, -0.0556],
[-0.0234, -0.0297, -0.1155, ..., 0.1143, 0.0083, -0.0675]],
grad_fn=)
2.Xavier方法与Kaiming方法
2.1Xavier初始化

设置:
a = np.sqrt(6 / (self.neural_num + self.neural_num))
tanh_gain = nn.init.calculate_gain('tanh')
a *= tanh_gain
nn.init.uniform_(m.weight.data, -a, a)
输出:
方差在0.65左右,不大不小,比较适中。
layer:0, std:0.7571136355400085
layer:1, std:0.6924336552619934
layer:2, std:0.6677976846694946
layer:3, std:0.6551960110664368
layer:4, std:0.655646800994873
layer:5, std:0.6536089777946472
layer:6, std:0.6500504612922668
......
layer:95, std:0.6516367793083191
layer:96, std:0.643530011177063
layer:97, std:0.6426344513893127
layer:98, std:0.6408163905143738
layer:99, std:0.6442267298698425
tensor([[ 0.1155, 0.1244, 0.8218, ..., 0.9404, -0.6429, 0.5177],
[-0.9576, -0.2224, 0.8576, ..., -0.2517, 0.9361, 0.0118],
[ 0.9484, -0.2239, 0.8746, ..., -0.9592, 0.7936, 0.6285],
...,
[ 0.7192, 0.0835, -0.4407, ..., -0.9590, 0.2557, 0.5419],
[-0.9546, 0.5104, -0.8002, ..., -0.4366, -0.6098, 0.9672],
[ 0.6085, 0.3967, 0.1099, ..., 0.3905, -0.5264, 0.0729]],
grad_fn=)
使用pytorch封装好的xavier方法 :
tanh_gain = nn.init.calculate_gain('tanh')
nn.init.xavier_uniform_(m.weight.data, gain=tanh_gain)输出:
和手动计算的结果一致。注意:本初始化方法注意针对"饱和函数"的激活方法。
layer:0, std:0.7571136355400085
layer:1, std:0.6924336552619934
layer:2, std:0.6677976846694946
layer:3, std:0.6551960110664368
layer:4, std:0.655646800994873
layer:5, std:0.6536089777946472
layer:6, std:0.6500504612922668
......
layer:95, std:0.6516367793083191
layer:96, std:0.643530011177063
layer:97, std:0.6426344513893127
layer:98, std:0.6408163905143738
layer:99, std:0.6442267298698425
tensor([[ 0.1155, 0.1244, 0.8218, ..., 0.9404, -0.6429, 0.5177],
[-0.9576, -0.2224, 0.8576, ..., -0.2517, 0.9361, 0.0118],
[ 0.9484, -0.2239, 0.8746, ..., -0.9592, 0.7936, 0.6285],
...,
[ 0.7192, 0.0835, -0.4407, ..., -0.9590, 0.2557, 0.5419],
[-0.9546, 0.5104, -0.8002, ..., -0.4366, -0.6098, 0.9672],
[ 0.6085, 0.3967, 0.1099, ..., 0.3905, -0.5264, 0.0729]],
grad_fn=)
如果采用非饱和函数(在前向传播的时候),会出现数据剧增,如在前向传播设置:
x = torch.relu(x) 输出:
layer:0, std:0.9689465165138245
layer:1, std:1.0872339010238647
layer:2, std:1.2967970371246338
......
layer:95, std:3661650.25
layer:96, std:4741351.5
layer:97, std:5300344.0
layer:98, std:6797731.0
layer:99, std:7640649.5
tensor([[ 0.0000, 3028669.0000, 12379584.0000, ...,
3593904.7500, 0.0000, 24658918.0000],
[ 0.0000, 2758812.2500, 11016996.0000, ...,
2970391.2500, 0.0000, 23173852.0000],
[ 0.0000, 2909405.2500, 13117483.0000, ...,
3867146.2500, 0.0000, 28463464.0000],
...,
[ 0.0000, 3913313.2500, 15489625.0000, ...,
5777772.0000, 0.0000, 33226552.0000],
[ 0.0000, 3673757.2500, 12739668.0000, ...,
4193462.0000, 0.0000, 26862394.0000],
[ 0.0000, 1913936.2500, 10243701.0000, ...,
4573383.5000, 0.0000, 22720464.0000]],
grad_fn=)
2.2Kaiming初始化
 设置:
设置:
nn.init.normal_(m.weight.data, std=np.sqrt(2 / self.neural_num))输出:
layer:0, std:0.826629638671875
layer:1, std:0.878681480884552
layer:2, std:0.9134420156478882
layer:3, std:0.8892467617988586
layer:4, std:0.8344276547431946
layer:5, std:0.87453693151474
......
layer:94, std:0.595414936542511
layer:95, std:0.6624482870101929
layer:96, std:0.6377813220024109
layer:97, std:0.6079217195510864
layer:98, std:0.6579239368438721
layer:99, std:0.6668398976325989
tensor([[0.0000, 1.3437, 0.0000, ..., 0.0000, 0.6444, 1.1867],
[0.0000, 0.9757, 0.0000, ..., 0.0000, 0.4645, 0.8594],
[0.0000, 1.0023, 0.0000, ..., 0.0000, 0.5147, 0.9196],
...,
[0.0000, 1.2873, 0.0000, ..., 0.0000, 0.6454, 1.1411],
[0.0000, 1.3588, 0.0000, ..., 0.0000, 0.6749, 1.2437],
[0.0000, 1.1807, 0.0000, ..., 0.0000, 0.5668, 1.0600]],
grad_fn=)
使用pytorch封装好的kaiming初始化方法:
nn.init.kaiming_normal_(m.weight.data) 输出:
和手动初始化结果一致。
layer:0, std:0.826629638671875
layer:1, std:0.878681480884552
layer:2, std:0.9134420156478882
layer:3, std:0.8892467617988586
layer:4, std:0.8344276547431946
layer:5, std:0.87453693151474
.......
layer:94, std:0.595414936542511
layer:95, std:0.6624482870101929
layer:96, std:0.6377813220024109
layer:97, std:0.6079217195510864
layer:98, std:0.6579239368438721
layer:99, std:0.6668398976325989
tensor([[0.0000, 1.3437, 0.0000, ..., 0.0000, 0.6444, 1.1867],
[0.0000, 0.9757, 0.0000, ..., 0.0000, 0.4645, 0.8594],
[0.0000, 1.0023, 0.0000, ..., 0.0000, 0.5147, 0.9196],
...,
[0.0000, 1.2873, 0.0000, ..., 0.0000, 0.6454, 1.1411],
[0.0000, 1.3588, 0.0000, ..., 0.0000, 0.6749, 1.2437],
[0.0000, 1.1807, 0.0000, ..., 0.0000, 0.5668, 1.0600]],
grad_fn=)
3.常用初始化方法
 代码:
代码:
# ======================================= calculate gain =======================================
# flag = 0
flag = 1
if flag:
x = torch.randn(10000)
out = torch.tanh(x)
gain = x.std() / out.std()
print('gain:{}'.format(gain))
tanh_gain = nn.init.calculate_gain('tanh')
print('tanh_gain in PyTorch:', tanh_gain)
输出:
手动计算和pytorch自带的函数计算结果对比
gain:1.5982500314712524
tanh_gain in PyTorch: 1.6666666666666667