FastICA的原理及实现
FastICA的原理及实现
为什么是ICA而不是PCA
ICA分离出来的是非高斯分布的信号,而PCA是假设高斯分布,非高斯分布在均值为0方差一样的情况下,信息熵比高斯分布小,所以在0附近有比高斯分布更高的峰值。所以更适合学习稀疏特征。ICA是使分量最大独立化,PCA是使重构误差最小。
PCA与ICA的对比参看https://blog.csdn.net/vendetta_gg/article/details/106521295。
FastICA相比ICA的进步
- ICA需要假定si的先验分布函数为sigmoid函数,而FastICA不需要假定先验分布。
- ICA使用梯度下降法更新,收敛速度是一次的。FastICA使用牛顿法更新,收敛速度至少是二次的,这就是FastICA名字的来源。
- ICA只能一次把所有独立成分全求出来,FastICA可以根据需要只求出1~n个独立成分。
论文的解读
此部分参照独立成分分析FastICA算法原理-知乎,并且加入了我的一些理解。
对于d维随机变量 x x x,假设是由相互独立的源 s s s通过 A A A矩阵线性组合产生:
x = A s x=As x=As
如果 s s s服从高斯分布,则不能还原出唯一的 s s s,如果 s s s非高斯,则可以通过找到 W W W使 s = W x s=Wx s=Wx,使 s s s相互独立从而得到 W W W和 s s s。
为什么ICA可以恢复原始的源?
Darmois - Skitovitch theorem 假设Si是相互独立的源噪声,对于两个随机变量
X = a 1 S 1 + … + a n S n , Y = b 1 S 1 + … + b n S n X=a_1S_1+…+a_nS_n,\\ Y=b_1S_1+…+b_nS_n X=a1S1+…+anSn,Y=b1S1+…+bnSn
若 X Y XY XY相互独立,则对任意 a i b i ≠ 0 a_ib_i \neq 0 aibi=0,必有 S i S_i Si为高斯分布。即两个独立的分布,除了高斯分布,两个非零的线性组合一定不相互独立。
根据定理,假设n=2, S S S非高斯,于是
x 1 = a 1 s 1 + a 2 s 2 , x 2 = b 1 s 1 + b 2 s 2 x_1=a_1s_1+a_2s_2, \\ x_2=b_1s_1+b_2s_2 x1=a1s1+a2s2,x2=b1s1+b2s2
且 z 1 = w 1 T X , z 2 = w 2 T X z_1=w_1^T X, z_2=w_2^TX z1=w1TX,z2=w2TX,且相互独立,则
z 1 = c 1 s 1 + c 2 s 2 , z 2 = d 1 s 1 + d 2 s 2 z_1=c_1s_1+c_2s_2,\\ z_2=d_1s_1+d_2s_2 z1=c1s1+c2s2,z2=d1s1+d2s2
根据定理,因为 s 1 , s 2 s_1,s_2 s1,s2非高斯,所以 c 1 d 1 = 0 , c 2 d 2 = 0 c_1d_1=0,c_2d_2=0 c1d1=0,c2d2=0。但是 z 1 , z 2 z_1,z_2 z1,z2不是零,所以 z 1 , z 2 z_1,z_2 z1,z2分别为 c 1 s 1 , b 2 s 2 c_1s_1,b_2s_2 c1s1,b2s2(或者反过来),总之可以分离成两个相互独立的 z 1 , z 2 z_1,z_2 z1,z2。即把 x 1 , x 2 x_1,x_2 x1,x2重新线性组合为 s 1 , s 2 s_1,s_2 s1,s2使其相互独立后, s 1 , s 2 s_1,s_2 s1,s2就是独立源噪声(可能多一个倍数关系)。
目标函数
我们使用互信息(独立的情况下 S S S的信息熵为分量 s i s_i si信息熵的和,用分量信息熵和减去 S S S信息熵,越小说明越接近独立)作为目标函数。
I ( s 1 , … , s n ) = ∑ ( H ( s i ) ) − H ( S ) I(s_1,…,s_n)=\sum(H(s_i))-H(S) I(s1,…,sn)=∑(H(si))−H(S)
首先计算 H ( S ) H(S) H(S)。因为 S = W X S=WX S=WX,
所以 l o g P ( S ) = l o g P ( X ) − l o g ∣ d e t W ∣ logP(S)=logP(X)-log|detW| logP(S)=logP(X)−log∣detW∣
如果 d e t W = 1 , l o g ∣ d e t W ∣ = 0 detW=1,log|detW|=0 detW=1,log∣detW∣=0。此时 H ( S ) H(S) H(S)与 W W W无关,只需要最小化每一个 H ( s i ) H(s_i) H(si)。
如何保证 d e t W = 1 detW=1 detW=1呢?
首先,根据 S S S是相互独立的源,可以假设 s i si si的方差是一致的。那么 S S S的协方差为 I I I的整数倍。不妨设为 I I I。这时 X X X可以看成 S S S每个源先经过放大器再线性组合得到,并不影响模型。在 X X X接收器,线性组合后,变成 X ^ \hat{X} X^,使其协方差为 I I I。这些改动没有改变 X X X是 S S S线性组合的本质。但是经过这些假设,从 S S S到 X X X的中间线性变换 W W W的行列式绝对值变为1,因为
S S T = W X X T W T , S S T = n I , X X T = n I . SS^T=WXX^TW^T,\\SS^T=nI, \\XX^T=nI. SST=WXXTWT,SST=nI,XXT=nI.取行列式发现 ∣ d e t W ∣ = 1 |detW|=1 ∣detW∣=1。
X X X正交化利用协方差特征分解。
X X T = A S S T A T = A A T = E D E T , XX^T=ASS^TA^T=AA^T=EDE^T, XXT=ASSTAT=AAT=EDET,则
E D − 1 / 2 E T X X T E D − 1 / 2 E T = E D − 1 / 2 E T E D E T E D − 1 / 2 E T . ED^{-1/2}E^TXX^TED^{-1/2}E^T=ED^{-1/2}E^TEDE^TED^{-1/2}E^T. ED−1/2ETXXTED−1/2ET=ED−1/2ETEDETED−1/2ET.注意 E E T = I EE^T=I EET=I,所以原式= I I I。
令 X ^ = E D − 1 / 2 E T X , X ^ X ^ T = I , \hat{X}=ED^{-1/2}E^TX,\hat{X}\hat{X}^T=I, X^=ED−1/2ETX,X^X^T=I,即 X ^ \hat{X} X^是正交矩阵。
完成以后才发现其实原文定义的 I I I并不是这样。原文令 J ( y ) = H ( y gauss ) − H ( y ) J({y})=H\left({y}_{\text {gauss }}\right)-H({y}) J(y)=H(ygauss )−H(y),其中 y g a u s s y_{gauss} ygauss是与 y y y同方差的正态分布。 I ( y 1 , y 2 , ⋯ , y n ) = J ( y ) − ∑ i J ( y i ) . I\left(y_{1}, y_{2}, \cdots, y_{n}\right)=J(\mathbf{y})-\sum_{i} J\left(y_{i}\right). I(y1,y2,⋯,yn)=J(y)−i∑J(yi).实际上对 S S S在假定独立且协方差为 I I I时, H ( S g a u s s ) = ∑ i H ( s i g a u s s ) H(S_{gauss})=\sum_i H(s_{i_{gauss}}) H(Sgauss)=∑iH(sigauss)。因此这个互信息和上面的定义等价。因为 H ( S g a u s s ) H(S_{gauss}) H(Sgauss)也是一个常数,再根据上面已经证明的 H ( S ) H(S) H(S)与 W W W无关, J ( S ) = H ( S g a u s s ) − H ( S ) J(S)=H(S_{gauss})-H(S) J(S)=H(Sgauss)−H(S)与 W W W无关。所以最小化 I ( s 1 , … , s n ) I(s_1,…,s_n) I(s1,…,sn),只需要最大化 ∑ i J ( y i ) \sum_{i} J\left(y_{i}\right) ∑iJ(yi)。根据知乎大佬的解释,最小化 H ( s i ) H(s_i) H(si)就是最大化非高斯性,因为高斯分布在同均值方差下有最大熵。 J ( s i ) J(s_i) J(si)就是衡量非高斯性大小的。
原文用 J J J定义后用了另一个式子来近似 J ( y i ) ≈ c [ E { G ( y i ) } − E { G ( ν ) } ] 2 , J\left(y_{i}\right) \approx c\left[E\left\{G\left(y_{i}\right)\right\}-E\{G(\nu)\}\right]^{2}, J(yi)≈c[E{G(yi)}−E{G(ν)}]2,其中 c c c是正常数, ν ∼ N ( 0 , 1 ) \nu\sim N(0,1) ν∼N(0,1), G G G是非二次函数。
J G ( w i ) = [ E { G ( w i T x ) } − E { G ( ν ) } ] 2 J_G(w_i)=[E\left\{G(w_i^Tx)\right\}-E\left\{G(\nu)\right\} ]^2 JG(wi)=[E{G(wiTx)}−E{G(ν)}]2
s i = w i T x s_i=w_i^Tx si=wiTx.
至此已经找到目标函数了:
最大化 ∑ i = 1 n J G ( w i ) wrt. w i , i = 1 , ⋯ , n \sum_{i=1}^{n} J_{G}\left(\mathbf{w}_{i}\right) \text { wrt. } \mathbf{w}_{i}, i=1, \cdots, n ∑i=1nJG(wi) wrt. wi,i=1,⋯,n
其中约束条件为 s i , s j s_i,s_j si,sj无关,即
E { ( w k T x ) ( w j T x ) } = δ j k E\left\{\left(\mathbf{w}_{k}^{T} \mathbf{x}\right)\left(\mathbf{w}_{j}^{T} \mathbf{x}\right)\right\}=\delta_{j k} E{(wkTx)(wjTx)}=δjk,其中 δ j k \delta_{jk} δjk是示性函数。
G G G的选择
然后考虑非二次函数 G ( u ) G(u) G(u)的选择。论文给了几个定理,分别从 w w w估计的一致性,渐进方差和鲁棒性出发给了几个定理和选择标准。具体可以查看原论文。中间有一个地方比较重要,需要 G G G满足:
条件1
E { s i g ( s i ) − g ′ ( s i ) } [ E { G ( s i ) } − E { G ( ν ) } ] > 0 E\left\{s_{i} g\left(s_{i}\right)-g^{\prime}\left(s_{i}\right)\right\}\left[E\left\{G\left(s_{i}\right)\right\}-E\{G(\nu)\}\right]>0 E{sig(si)−g′(si)}[E{G(si)}−E{G(ν)}]>0
注意左边第二项是 J G ( w i ) J_{G}(w_i) JG(wi)的绝对值。该论文选择的 G G G为 l o g P ( s ) logP(s) logP(s),并且在 s s s是指数族分布下进行一些近似。这个在后面优化会用到。
G 1 ( u ) = 1 a 1 log cosh ( a 1 u ) g 1 ( u ) = tanh ( a 1 u ) G 2 ( u ) = − 1 a 2 exp ( − a 2 u 2 / 2 ) g 2 ( u ) = u exp ( − a 2 u 2 / 2 ) G 3 ( u ) = 1 4 u 4 g 3 ( u ) = u 3 \begin{aligned} G_{1}(u) &=\frac{1}{a_{1}} \log \cosh \left(a_{1} u\right) \\ g_{1}(u) &=\tanh \left(a_{1} u\right) \\ G_{2}(u) &=-\frac{1}{a_{2}} \exp \left(-a_{2} u^{2} / 2\right) \\ g_{2}(u) &=u \exp \left(-a_{2} u^{2} / 2\right) \\ G_{3}(u) &=\frac{1}{4} u^{4} \\ g_{3}(u) &=u^{3} \end{aligned} G1(u)g1(u)G2(u)g2(u)G3(u)g3(u)=a11logcosh(a1u)=tanh(a1u)=−a21exp(−a2u2/2)=uexp(−a2u2/2)=41u4=u3
其中 g ( ∗ ) g(*) g(∗)是 G ( ∗ ) G(*) G(∗)的导数。实际上算法还需要 g ′ ( ∗ ) g'(*) g′(∗)但是没有给出。实现的时候还需要再算一下。
牛顿法解优化问题
接下来使用拉格朗日方程去解带约束的优化问题。
当 E { G ( s i ) } − E { G ( ν ) } > 0 E\left\{G\left(s_{i}\right)\right\}-E\{G(\nu)\}>0 E{G(si)}−E{G(ν)}>0时,最大化 ∑ i = 1 n J G ( w i ) wrt. w i , i = 1 , ⋯ , n \sum_{i=1}^{n} J_{G}\left(\mathbf{w}_{i}\right) \text { wrt. } \mathbf{w}_{i}, i=1, \cdots, n ∑i=1nJG(wi) wrt. wi,i=1,⋯,n等价于最大化 ∑ i = 1 n E { G ( w i T x ) } \sum_{i=1}^nE\left\{G(w_i^Tx)\right\} ∑i=1nE{G(wiTx)}。逐个考虑 w i \mathbf{w}_i wi,即最大化 E { G ( w i T x ) } , ∥ w i ∥ 2 = 1 E\left\{G(\mathbf{w}_i^T\mathbf{x})\right\}, \left\|\mathbf{w}_ i\right\|^2=1 E{G(wiTx)},∥wi∥2=1使用拉格朗日方程:
E { x g ( w T x ) } − β w = 0 E\left\{\mathbf{x} g\left(\mathbf{w}^{T} \mathbf{x}\right)\right\}-\beta \mathbf{w}=0 E{xg(wTx)}−βw=0
可以得到 β = E { w 0 T x g ( w 0 T x ) } \beta=E\left\{\mathbf{w}_{0}^{T} \mathbf{x} g\left(\mathbf{w}_{0}^{T} \mathbf{x}\right)\right\} β=E{w0Txg(w0Tx)},其中 w 0 \mathbf{w}_0 w0是 w i \mathbf{w}_i wi的最优点。
记 F F F为左边的式子,则 J F ( w ) J_F(\mathbf{w}) JF(w)为雅各比矩阵
J F ( w ) = E { x x T g ′ ( w T x ) } − β I . J F(\mathbf{w})=E\left\{\mathbf{x x}^{T} g^{\prime}\left(\mathbf{w}^{T} \mathbf{x}\right)\right\}-\beta \mathbf{I} . JF(w)=E{xxTg′(wTx)}−βI.
E { x x T g ′ ( w T x ) } E\left\{\mathbf{x x}^{T} g^{\prime}\left(\mathbf{w}^{T} \mathbf{x}\right)\right\} E{xxTg′(wTx)}合理近似为 E { x x T } E { g ′ ( w T x ) } = I E { g ′ ( w T x ) } E\left\{\mathbf{x x}^{T} \right\}E\left\{g^{\prime}\left(\mathbf{w}^{T} \mathbf{x}\right) \right\}=IE\left\{g^{\prime}\left(\mathbf{w}^{T} \mathbf{x}\right) \right\} E{xxT}E{g′(wTx)}=IE{g′(wTx)}。
接下来用牛顿法求解拉格朗日方程。
w + = w − [ E { x g ( w T x ) } − β w ] / [ E { g ′ ( w T x ) } − β ] w ∗ = w + / ∥ w + ∥ \begin{array}{l} \mathbf{w}^{+}=\mathbf{w}-\left[E\left\{\mathbf{x} g\left(\mathbf{w}^{T} \mathbf{x}\right)\right\}-\beta \mathbf{w}\right] /\left[E\left\{g^{\prime}\left(\mathbf{w}^{T} \mathbf{x}\right)\right\}-\beta\right] \\ \mathbf{w}^{*}=\mathbf{w}^{+} /\left\|\mathbf{w}^{+}\right\| \end{array} w+=w−[E{xg(wTx)}−βw]/[E{g′(wTx)}−β]w∗=w+/∥w+∥
根据条件1左边第一项为正,即分母 E { g ′ ( w T x ) } − β E\left\{g^{\prime}\left(\mathbf{w}^{T} \mathbf{x}\right)\right\}-\beta E{g′(wTx)}−β为负,所以同乘分母的相反数不改变 w + \mathbf{w}^{+} w+的方向,只改变大小,单位化以后不变。即:
w + = E { x g ( w T x ) } − E { g ′ ( w T x ) } w w ∗ = w + / ∥ w + ∥ \begin{aligned} \mathbf{w}^{+} &=E\left\{\mathbf{x} g\left(\mathbf{w}^{T} \mathbf{x}\right)\right\}-E\left\{g^{\prime}\left(\mathbf{w}^{T} \mathbf{x}\right)\right\} \mathbf{w} \\ \mathbf{w}^{*} &=\mathbf{w}^{+} /\left\|\mathbf{w}^{+}\right\| \end{aligned} w+w∗=E{xg(wTx)}−E{g′(wTx)}w=w+/∥ ∥w+∥ ∥
有了一个 w \mathbf{w} w的估计,就可以进行n次从而得到n个独立成分。为了防止收敛到同一个 w \mathbf{w} w,可以使用施密特正交化把 w i \mathbf{w}_i wi单位正交化。只需要在第i+1个 w i + 1 \mathbf{w}_{i+1} wi+1去掉其在前i个方向上的分量,然后单位化即可:
w i + 1 = w i + 1 − ∑ j = 1 i w i + 1 T w j w j w i + 1 = w i + 1 / w p + 1 T w i + 1 \mathbf{w}_{i+1}=\mathbf{w}_{i+1}-\sum_{j=1}^{i} \mathbf{w}_{i+1}^{T} \mathbf{w}_{j} \mathbf{w}_{j}\\ \mathbf{w}_{i+1}=\mathbf{w}_{i+1} / \sqrt{\mathbf{w}_{p+1}^{T} \mathbf{w}_{i+1}} wi+1=wi+1−j=1∑iwi+1Twjwjwi+1=wi+1/wp+1Twi+1
还有一种对称去相关的方法,与白化基本一致,不赘述直接贴公式
W = ( W W T ) − 1 / 2 W \mathbf{W}=\left(\mathbf{W W}^{T}\right)^{-1 / 2} \mathbf{W} W=(WWT)−1/2W
对称矩阵的-1/2次幂意味着特征分解后的逆矩阵
( W W ) − 1 / 2 = E D − 1 / 2 E T (\mathbf{W W})^{-1 / 2}=\mathbf{E D}^{-1 / 2} \mathbf{E}^{T} (WW)−1/2=ED−1/2ET
在具体得到n个 w i \mathbf{w}_{i} wi的实现,我使用随机选取X的样本点和随机从 G 1 , G 2 , G 3 G_1, G_2, G_3 G1,G2,G3中选择 G G G的方式,防止 w i \mathbf{w}_{i} wi相关性太强。
python实现及sklearn包调用
numpy实现
首先使用numpy编写自己的算法,然后与sklearn包比较。
import numpy as np
# 1.白化
def whiten(x):
# x是一列一个记录,一行一个特征
mean=np.mean(x,axis=1)
sd=np.std(x,axis=1)
std_x=(x-mean)/sd
Lambda, Vec=np.linalg.eig(std_x.dot(std_x.T))
# C = V*Lambda*V'
X_white=(np.dot(Vec.dot(np.diag(1/np.sqrt(Lambda))),Vec.T))
X_white=X_white.dot(std_x)
# print(1/np.sqrt(Lambda))
return X_white
# 验证白化效果
X=np.mat(np.random.randn(5,100))
A=np.mat(np.array([[1,0,0,0,0],
[0,2,0,0,1],
[0,0,1,1,0],
[1,1,0,1,0],
[0,1,0,0,1]
]))
X=A.dot(X)
print(A.dot(A.T))
X=whiten(X)
print(np.dot(X,X.T))
定义G
def G_1(x,a=1.5):
# G_1(u)=1/a1 logcosh(a1u)
# G_1'=tanh(a1u)
# G_1''=a1(1-tan(a1u)^2)
# 返回一阶导数和二阶导数
g=np.tanh(a*x)
g_dif=a*(1-g**2)
return (g,g_dif)
def G_2(x,a=1):
# G_2(u)=-1/a2*exp(-a2*u^2/2)
# G_2'=u*exp(-a2*u^2/2)
# G_2''=exp(-a2*u^2/2)-a2*u^2*exp(-a2*u^2/2)
g_2=x*np.exp(-(a*x**2/2))
g_2_dif=g_2/x - g_2*a*x
return (g_2,g_2_dif)
def G_3(x):
# G_3(u)=1/4 * u^4
# G_3'=u^3
# G_3''=3*u^2
g_3=x**3
g_3_dif=3*x**2
return (g_3,g_3_dif)
牛顿法求单个 w w w
def newton_method(X,G,loops,eps=0.0001):
"""
参数
X: 观测矩阵,每列为一个观测,每行为一个特征
G: 函数G
loops: 最大循环次数
eps: 判断收敛的参数 当循环后w变化的模小于eps停止循环
返回值
列向量w
"""
m,n=X.shape
w0=np.random.random([m,1])
w0=w0/np.dot(w0.T,w0)
w=w0
for i in range(loops):
E1=np.zeros((m,1))
E2=np.zeros((m,1))
for k in range(n):
x=X[:,k]
y=np.dot(w.T,x)
g,g_dif=G(y)
E1+=g.item()*x
E2+=g_dif.item()
E1=E1/n
E2=E2/n
w1=E1-E2*w
w1=w1/np.dot(w1.T,w1)
dif_w=w1-w0
dif_w_size=np.dot(dif_w.T,dif_w)
w=w1
if dif_w_size<eps:
break
# print('i',w)
return w
def extract_w(X,bs,loops,n=None):
"""
提取n个w作为矩阵输出
参数
X: 观测矩阵,每列为一个观测,每行为一个特征
bs: 一次提取多少个观测求w
loops: 一次牛顿法用至多多少次循环
n: 求多少个独立成分。默认X的特征数。
返回值
w作为列向量构成矩阵W
"""
if n is None:
n=X.shape[0]
m=X.shape[1]
W=np.mat(np.zeros([X.shape[0],n]))
for i in range(n):
idx=np.random.choice(range(m),bs,False)
X_sample=X[:,idx]
if np.random.sample(1)>0.5:
G=G_1
elif np.random.sample(1)>0.5:
G=G_2
else:
G=G_3
w=newton_method(X_sample,G,loops)
if i>0:
for j in range(i-1):
# print(w.T)
# print(W[:,j])
# print(np.dot(w.T,W[:,j]).item())
w=w-np.dot(w.T,W[:,j]).item() * W[:,j]
w=w/np.dot(w.T,w)
W[:,i]=w
return W
import matplotlib.pyplot as plt
# 生成波函数1
z0=np.hstack((np.ones(10),0,-np.ones(10)))
z1=np.tile(z0,(10))
z1=z1+np.random.random(len(z1))*0.01
plt.plot(z1)
# 生成波函数2
z0=[0.05*i for i in range(21)]
z0=z0-np.mean(z0)
z2=np.tile(z0,(10))
z2=z2+np.random.random(len(z2))*0.01
plt.plot(z2)
# 生成波函数3
z0=np.sin(np.linspace(0,2*np.pi,num=21,endpoint=False))
z3=np.tile(z0,(10))*0.5
plt.plot(z3)
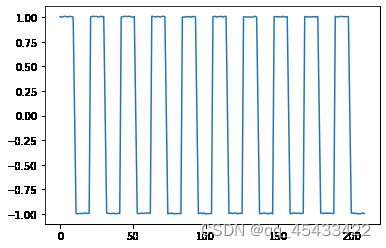

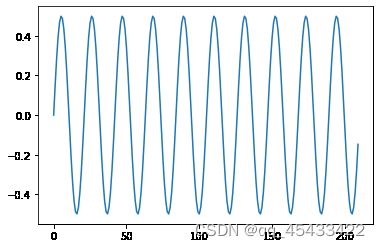
# 生成X,A是混合矩阵
A=np.mat([[1,2,0],[0.5,2,0.5],[0,1,1.5]])
z1=z1[:180]
z2=z2[:180]
z3=z3[:180]
Z=np.vstack((z1,z2,z3))
X=A*Z
# 绘制X
for i in range(X.shape[0]):
plt.plot(range(X.shape[1]),X[i,:].T)

用FastICA处理信号
X=whiten(X)
W=extract_w_2(X,150,500)
# 重构原始信号S
S=np.dot(W.T,X)
for i in range(3):
plt.figure()
plt.plot(range(S.shape[1]),S[i,:].T)

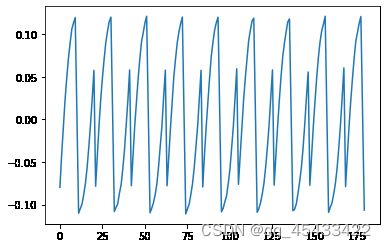

sklearn包
用sklearn包直接调用FastICA
from sklearn.decomposition import FastICA
fast_ica=FastICA(n_components=3)
Sr=fast_ica.fit_transform(X)
S=np.dot(Sr.T,X)
for i in range(3):
plt.figure()
plt.plot(range(S.shape[1]),S[i,:].T)
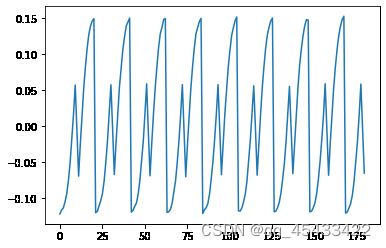

可以看出我实现的算法效果还是不错的,跟调包差不多。没有进一步增加数据集研究表现。毕竟只是学习笔记。
参照
HYVARINEN A. Fast and robust fixed-point algorithms for independent component analysis[J]. IEEE transactions on Neural Networks, IEEE, 1999, 10(3): 626–634.
小杰-独立成分分析FastICA算法原理
「vendetta_gg」PCA和ICA的对比