爬取新型冠状病毒的历史数据
网站选择
首先我看了下,腾讯的数据并不是很全,只有一天的,或者说我技艺不精,没发现其他的数据,后来观察了很久,发现丁香医生的数据有各个国家的历史数据,因此选用丁香医生的网址进行爬取
丁香医生网址
观察网站结构
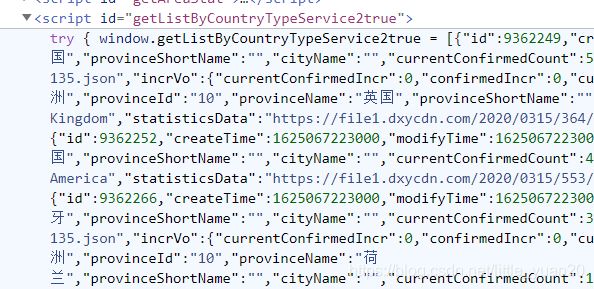
在getListByCountryTypeService2true栏中有各个国家的当前感染人数的数据,
其中statisticsData中的.json文件里含有各个国家的历史数据。
同样fetchRecentStat里面也有中国各个省市的历史数据(我只爬了国家的,其实原理一样,稍微改一下即可)
知识预备
如果看不懂的话需要学习一下库的基本使用,代码并不是很难。没有加其他的东西,看不懂的复制方法百度即可。
需要了解的python的库
numpy
pandas
json
requests
BeautifulSoup
HTML网站的基本结构
爬虫要用到的一些网站数据。
python的基本使用。
代码
代码本人均跑通,报错注意更改写入文件的地址
爬取到的数据(之后改成了excel格式并进行了汇总,也可以写入数据库,稍作更改即可)
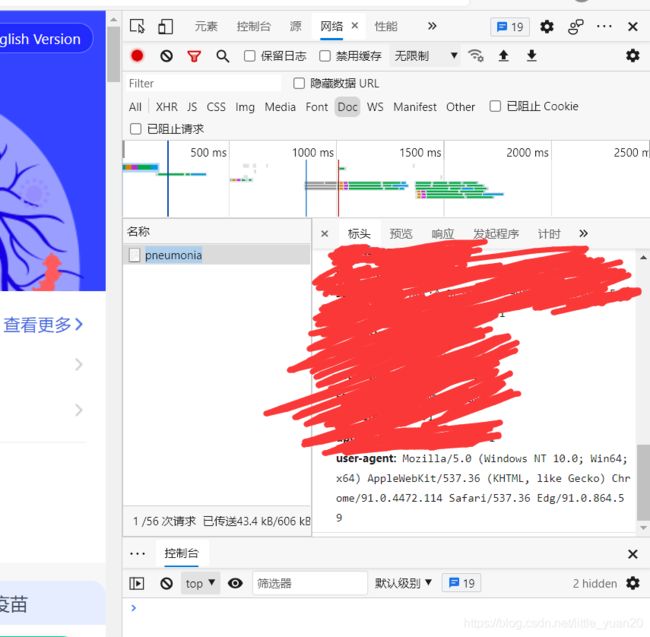
代码里的header可以网页自己提取,也可以用我的。
右键检查->选择网络->运行->双击名称->滚动到最底下复制粘贴。
共分为四个文件
#本块代码获取到的是总世界的json数据
import requests
import re
import json
from bs4 import BeautifulSoup
def getOriHtmlText(url,code='utf-8'):
try:
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36 Edg/91.0.864.54'
}
r=requests.get(url,timeout=30,headers=headers)
r.raise_for_status()
r.encoding=code
return r.text
except:
return "There are some errors when get the original html!"
def getTheList(url):
html=getOriHtmlText("https://ncov.dxy.cn/ncovh5/view/pneumonia")
soup=BeautifulSoup(html,'xml')
# script=soup.find_all('script',{"id":"getListByCountryTypeService2true"})
# print(script.find(''))
htmlBodyText=soup.body.text
# 获取国家数据
worldDataText=htmlBodyText[htmlBodyText.find('window.getListByCountryTypeService2true = '):]
worldDataStr = worldDataText[worldDataText.find('[{'):worldDataText.find('}catch')]
worldDataJson=json.loads(worldDataStr)
with open(r"F:\I_love_learning\junior\机器学习\课程设计\data\worldData.json","w",errors='ignore') as f:
json.dump(worldDataJson,f)
print("写入国家数据文件成功!")
'''
provinceDataText = htmlBodyText[htmlBodyText.find('window.getAreaStat = '):]
provinceDataStr = provinceDataText[provinceDataText.find('[{'):provinceDataText.find('}catch')]
provinceDataJson=json.loads(provinceDataStr)
with open("../data/provinceData.json","w") as f:
json.dump(provinceDataJson,f)
print("写入省份数据文件成功!")
'''
getTheList("https://ncov.dxy.cn/ncovh5/view/pneumonia")
#本段代码是提取刚刚获得的worlddata里面各个国家的数据,并写入json
import json
import requests
import time
def deal_worlddatalist():
with open("F:\I_love_learning\junior\机器学习\课程设计\data\worldData.json",'r') as f:
worldDataJson=json.load(f)
# print(len(worldDataJson))
# print(worldDataJson)
for i in range(0,len(worldDataJson)):
print(worldDataJson[i]['provinceName']+" "+worldDataJson[i]['countryShortCode']+" "+worldDataJson[i]['countryFullName']+" "+worldDataJson[i]['statisticsData'])
return worldDataJson
def get_the_world_data():
# 获取每个国家对应的json
worldDataJson=deal_worlddatalist()
# 记录错误数量
errorNum=0
for i in range(0,len(worldDataJson)):
provinceName=worldDataJson[i]['provinceName']
try:
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36 Edg/91.0.864.54'
}
r = requests.get(worldDataJson[i]['statisticsData'], timeout=30, headers=headers)
r.raise_for_status()
r.encoding = 'utf-8'
everCountryDataJson = json.loads(r.text)
toWriteFilePath="F:\I_love_learning\junior\机器学习\课程设计\data\worldData"+provinceName+".json"
with open(toWriteFilePath,'w') as file:
json.dump(everCountryDataJson, file)
print(provinceName + " 数据得到!")
time.sleep(10)
except:
errorNum+=1
print("在获取 "+provinceName+" 数据时出错!")
print("各国数据获取完成!")
print("错误数据量为:"+str(errorNum))
get_the_world_data()
#本段代码是提取了10个国家的json数据,并且将json数据转化为excel数据便于pandas读取,并且对于0的数值进行了bfill()方法进行填充,即用后一个的数值填充前一个的数值,也可用拉格朗日插值法进行,下面给出拉格朗日插值法的代码连接。
import json
import pandas as pd
import numpy as np
nameList = ['中国','美国','巴西','印度','巴基斯坦','英国','阿富汗','墨西哥','南非','乌克兰']
for i in nameList:
file = 'F:/I_love_learning/junior/机器学习/课程设计/data/data_use/WorldData' + i + '.json'
with open(file,'r') as f:
data = json.load(f)
data_list = data['data']
data_df = pd.DataFrame(data_list)
data_df.set_index('dateId',inplace = True)
data_df = data_df[['confirmedCount','confirmedIncr','curedCount','curedCount','curedIncr','currentConfirmedCount','currentConfirmedIncr','deadCount','deadIncr']]
data_ult = data_df[data_df.index>20210100]
data_ult = data_ult[data_ult.index<20210415]
data_ult = data_ult.replace(0, np.nan)
data_ult.bfill(inplace = True)
data_ult.to_excel('F:/I_love_learning/junior/机器学习/课程设计/data/data_use/dataFrame/'+ i + '.xlsx')
拉格朗日插值法代码
#本段代码将10个国家的数据整合到了6个文件,分别为确诊人数,确诊人数增加,治愈人数,治愈人数增加,死亡人数,死亡人数增加。并写入CSV中方便pandas读取。
import numpy as np
import pandas as pd
import random
#这是一个中文名转英文名的字典,可以直接复制,非常好用,不过本代码并没有使用。
nameMap = {'毛里求斯':'Mauritius','圣皮埃尔和密克隆群岛':'St. Pierre and Miquelon','安圭拉':'Anguilla','荷兰加勒比地区':'Caribbean Netherlands','圣巴泰勒米岛':'Saint Barthelemy','英属维尔京群岛':'British Virgin Is.','科摩罗':'Comoros','蒙特塞拉特':'Montserrat','塞舌尔':'Seychelles','特克斯和凯科斯群岛':'Turks and Caicos Is.','梵蒂冈':'Vatican','圣其茨和尼维斯':'Saint Kitts and Nevis','库拉索岛':'Curaçao','多米尼克':'Dominica','圣文森特和格林纳丁斯':'St. Vin. and Gren.','斐济':'Fiji','圣卢西亚':'Saint Lucia','北马里亚纳群岛联邦':'N. Mariana Is.','格林那达':'Grenada','安提瓜和巴布达':'Antigua and Barb.','列支敦士登':'Liechtenstein','圣马丁岛':'Saint Martin','法属波利尼西亚':'Fr. Polynesia','美属维尔京群岛':'U.S. Virgin Is.','荷属圣马丁':'Sint Maarten','巴巴多斯':'Barbados','开曼群岛':'Cayman Is.','摩纳哥':'Monaco','阿鲁巴':'Aruba','特立尼达和多巴哥':'Trinidad and Tobago','钻石公主号邮轮':'Princess','瓜德罗普岛':'Guadeloupe','关岛':'Guam','直布罗陀':'Gibraltar','马提尼克':'Martinique','马耳他':'Malta','法罗群岛':'Faeroe Is.','圣多美和普林西比':'São Tomé and Principe','安道尔':'Andorra','根西岛':'Guernsey','泽西岛':'Jersey','佛得角':'Cape Verde','马恩岛':'Isle of Man','留尼旺':'Reunion','圣马力诺':'San Marino','马尔代夫':'Maldives','马约特':'Mayotte','巴林':'Bahrain','新加坡': 'Singapore Rep.', '多米尼加': 'Dominican Rep.', '巴勒斯坦': 'Palestine', '巴哈马': 'The Bahamas', '东帝汶': 'East Timor', '阿富汗': 'Afghanistan', '几内亚比绍': 'Guinea Bissau', '科特迪瓦': "Côte d'Ivoire", '锡亚琴冰川': 'Siachen Glacier', '英属印度洋领土': 'Br. Indian Ocean Ter.', '安哥拉': 'Angola', '阿尔巴尼亚': 'Albania', '阿联酋': 'United Arab Emirates', '阿根廷': 'Argentina', '亚美尼亚': 'Armenia', '法属南半球和南极领地': 'French Southern and Antarctic Lands', '澳大利亚': 'Australia', '奥地利': 'Austria', '阿塞拜疆': 'Azerbaijan', '布隆迪共和国': 'Burundi', '比利时': 'Belgium', '贝宁': 'Benin', '布基纳法索': 'Burkina Faso', '孟加拉国': 'Bangladesh', '保加利亚': 'Bulgaria', '波黑': 'Bosnia and Herz.', '白俄罗斯': 'Belarus', '伯利兹': 'Belize', '百慕大': 'Bermuda', '玻利维亚': 'Bolivia', '巴西': 'Brazil', '文莱': 'Brunei', '不丹': 'Bhutan', '博茨瓦纳': 'Botswana', '中非共和国': 'Central African Rep.', '加拿大': 'Canada', '瑞士': 'Switzerland', '智利': 'Chile', '中国': 'China', '象牙海岸': 'Ivory Coast', '喀麦隆': 'Cameroon', '刚果(金)': 'Dem. Rep. Congo', '刚果(布)': 'Congo', '哥伦比亚': 'Colombia', '哥斯达黎加': 'Costa Rica', '古巴': 'Cuba', '北塞浦路斯': 'N. Cyprus', '塞浦路斯': 'Cyprus', '捷克': 'Czech Rep.', '德国': 'Germany', '吉布提': 'Djibouti', '丹麦': 'Denmark', '阿尔及利亚': 'Algeria', '厄瓜多尔': 'Ecuador', '埃及': 'Egypt', '厄立特里亚': 'Eritrea', '西班牙': 'Spain', '爱沙尼亚': 'Estonia', '埃塞俄比亚': 'Ethiopia', '芬兰': 'Finland', '斐': 'Fiji', '福克兰群岛': 'Falkland Islands', '法国': 'France', '加蓬': 'Gabon', '英国': 'United Kingdom', '格鲁吉亚': 'Georgia', '加纳': 'Ghana', '几内亚': 'Guinea', '冈比亚': 'Gambia', '赤道几内亚': 'Eq. Guinea', '希腊': 'Greece', '格陵兰': 'Greenland', '危地马拉': 'Guatemala', '法属圭亚那': 'French Guiana', '圭亚那': 'Guyana', '洪都拉斯': 'Honduras', '克罗地亚': 'Croatia', '海地': 'Haiti', '匈牙利': 'Hungary', '印度尼西亚': 'Indonesia', '印度': 'India', '爱尔兰': 'Ireland', '伊朗': 'Iran', '伊拉克': 'Iraq', '冰岛': 'Iceland', '以色列': 'Israel', '意大利': 'Italy', '牙买加': 'Jamaica', '约旦': 'Jordan', '日本': 'Japan', '哈萨克斯坦': 'Kazakhstan', '肯尼亚': 'Kenya', '吉尔吉斯斯坦': 'Kyrgyzstan', '柬埔寨': 'Cambodia', '韩国': 'Korea', '科索沃': 'Kosovo', '科威特': 'Kuwait', '老挝': 'Lao PDR', '黎巴嫩': 'Lebanon', '利比里亚': 'Liberia', '利比亚': 'Libya', '斯里兰卡': 'Sri Lanka', '莱索托': 'Lesotho', '立陶宛': 'Lithuania', '卢森堡': 'Luxembourg', '拉脱维亚': 'Latvia', '摩洛哥': 'Morocco', '摩尔多瓦': 'Moldova', '马达加斯加': 'Madagascar', '墨西哥': 'Mexico', '北马其顿': 'Macedonia', '马里': 'Mali', '缅甸': 'Myanmar', '黑山': 'Montenegro', '蒙古': 'Mongolia', '莫桑比克': 'Mozambique', '毛里塔尼亚': 'Mauritania', '马拉维': 'Malawi', '马来西亚': 'Malaysia', '纳米比亚': 'Namibia', '新喀里多尼亚': 'New Caledonia', '尼日尔': 'Niger', '尼日利亚': 'Nigeria', '尼加拉瓜': 'Nicaragua', '荷兰': 'Netherlands', '挪威': 'Norway', '尼泊尔': 'Nepal', '新西兰': 'New Zealand', '阿曼': 'Oman', '巴基斯坦': 'Pakistan', '巴拿马': 'Panama', '秘鲁': 'Peru', '菲律宾': 'Philippines', '巴布亚新几内亚': 'Papua New Guinea', '波兰': 'Poland', '波多黎各': 'Puerto Rico', '朝鲜': 'Dem. Rep. Korea', '葡萄牙': 'Portugal', '巴拉圭': 'Paraguay', '卡塔尔': 'Qatar', '罗马尼亚': 'Romania', '俄罗斯': 'Russia', '卢旺达': 'Rwanda', '西撒哈拉': 'W. Sahara', '沙特阿拉伯': 'Saudi Arabia', '苏丹': 'Sudan', '南苏丹': 'S. Sudan', '塞内加尔': 'Senegal', '所罗门群岛': 'Solomon Is.', '塞拉利昂': 'Sierra Leone', '萨尔瓦多': 'El Salvador', '索马里兰': 'Somaliland', '索马里': 'Somalia', '塞尔维亚': 'Serbia', '苏里南': 'Suriname', '斯洛伐克': 'Slovakia', '斯洛文尼亚': 'Slovenia', '瑞典': 'Sweden', '斯威士兰': 'Swaziland', '叙利亚': 'Syria', '乍得': 'Chad', '多哥': 'Togo', '泰国': 'Thailand', '塔吉克斯坦': 'Tajikistan', '土库曼斯坦': 'Turkmenistan', '特里尼达和多巴哥': 'Trinidad and Tobago', '突尼斯': 'Tunisia', '土耳其': 'Turkey', '坦桑尼亚': 'Tanzania', '乌干达': 'Uganda', '乌克兰': 'Ukraine', '乌拉圭': 'Uruguay', '美国': 'United States', '乌兹别克斯坦': 'Uzbekistan', '委内瑞拉': 'Venezuela', '越南': 'Vietnam', '瓦努阿图': 'Vanuatu', '西岸': 'West Bank', '也门共和国': 'Yemen', '南非': 'South Africa', '赞比亚共和国': 'Zambia', '津巴布韦': 'Zimbabwe'}
nameList = ['中国','美国','巴西','印度','巴基斯坦','英国','阿富汗','墨西哥','南非','乌克兰']
file = 'F:/I_love_learning/junior/机器学习/课程设计/data/data_use/dataFrame/'
data_init = pd.read_excel(file + nameList[0] +'.xlsx')
def changedf(file,nameList,ind):
confirmedCount = pd.DataFrame(index = ind,columns = nameList)
curedCount = pd.DataFrame(index = ind,columns = nameList)
deadCount = pd.DataFrame(index = ind,columns = nameList)
confirmedIncr = pd.DataFrame(index = ind,columns = nameList)
curedIncr = pd.DataFrame(index = ind,columns = nameList)
deadIncr = pd.DataFrame(index = ind,columns = nameList)
#变换数据格式,合并10个国家
for i in nameList:
data = pd.read_excel(file + i +'.xlsx')
data['countryName'] = i
confirmedCount[i]=pd.DataFrame(data.pivot(index='countryName',columns='dateId',values='confirmedCount').iloc[0])
curedCount[i]=pd.DataFrame(data.pivot(index='countryName',columns='dateId',values='curedCount').iloc[0])
deadCount[i]=pd.DataFrame(data.pivot(index='countryName',columns='dateId',values='deadCount').iloc[0])
confirmedIncr[i] = pd.DataFrame(data.pivot(index='countryName',columns='dateId',values='confirmedIncr').iloc[0])
curedIncr[i] = pd.DataFrame(data.pivot(index='countryName',columns='dateId',values='curedIncr').iloc[0])
deadIncr[i] = pd.DataFrame(data.pivot(index='countryName',columns='dateId',values='deadIncr').iloc[0])
confirmedCount.to_csv(file + 'confirmedCount' + '.csv')
curedCount.to_csv(file + 'curedCount' + '.csv')
deadCount.to_csv(file + 'deadCount' + '.csv')
confirmedIncr.to_csv(file + 'confirmedIncr' + '.csv')
curedIncr.to_csv(file + 'curedIncr' + '.csv')
deadIncr.to_csv(file + 'deadIncr' + '.csv')
changedf(file, nameList, data_init['dateId'])