mysql 冷热数据分离_elasticsearch冷热数据读写分离
Elasticsearch5.5冷热数据读写分离
前言
冷数据索引:查询频率低,基本无写入,一般为当天或最近2天以前的数据索引
热数据索引:查询频率高,写入压力大,一般为当天数据索引
当前系统日志每日写入量约为6T左右,日志数据供全线业务系统查询使用。
查询问题:
高峰时段写入及查询频率都较高,集群压力较大,查询ES时,常出现查询缓慢问题。
写入问题:
索引峰值写入量约为12w/s,且无副本。加上副本将导致索引写入速度减半、磁盘使用量加倍;不使用副本,若一个节点宕掉,整个集群无法写入,后果严重。
一、冷热数据分离
ES集群的索引写入及查询速度主要依赖于磁盘的IO速度,冷热数据分离的关键为使用SSD磁盘存储数据。
若全部使用SSD,成本过高,且存放冷数据较为浪费,因而使用普通SATA磁盘与SSD磁盘混搭,可做到资源充分利用,性能大幅提升的目标。
几个ES关键配置解读:
节点属性(后续索引及集群路由分布策略均依据此属性)
node.attr.box_type
node.attr.zone
...
elasticsearch.yml中可增加自定义配置,配置前缀为node.attr,后续属性及值可自定义,如:box_type、zone,即为当前es节点增加标签,亦可在启动命令时设置:bin/elasticsearch -d -Enode.attr.box_type=hot
索引路由分布策略
"index.routing.allocation.require.box_type": "hot"
可在索引模板setting中设置,也可通过rest api动态更新。意义为索引依据哪个属性标签,对分片、副本进行路由分布。
如我们对使用SSD作为存储介质的ES节点增加属性标签node.attr.box_type: hot,对其他SATA类ES节点增加属性标签node.attr.box_type: cool,将使当前索引的分片数据都落在SSD上。

后续对其索引配置更新为
"index.routing.allocation.require.box_type": "cool"
将使索引分片从SSD磁盘上路由至SATA磁盘上,达到冷热数据分离的效果。

集群路由分布策略(此策略比索引级路由策略权重高)
目的:不将鸡蛋放进一个篮子中。
"cluster.routing.allocation.awareness.attributes": "box_type"
如上配置,新建索引时,索引分片及副本只会分配到含有node.attr.box_type属性的节点上。(该值可以为多个,如"box_type,zone")
若集群中的节点box_type值只有一个,如只有hot,索引分片及副本会落在hot标签的节点上;若box_type值包括hot、cool,则同一个分片与其副本将尽可能不在相同的box_type节点上。
此种场景使用于:同一个物理机含有多个ES节点,若这多个节点标签相同,使用此路由分布策略将尽可能保证相同物理机上不会存放同一个分片及其副本。
"cluster.routing.allocation.awareness.force.box_type.values": "hot,cool"
强制使分片与副本分离。若只有hot标签的节点,索引只有分片可以写入,副本无法分配;若有hot、cool两种标签节点,相同分片与其副本绝不在相同标签节点上。
二、数据读写分离
几点结论:
若使当天索引及副本都写在SSD磁盘上,SSD磁盘使用量需20T以上,代价可能过高。(读写效率最高,但由于SSD节点肯定较少,读写都在相同节点上,节点压力会非常大)
现有的方式,只使用普通的SATA磁盘存储,代价最低。(读写效率最低,即为当前运行状况)
使用集群路由分配策略,SSD与SATA各存放1份数据,SSD磁盘需分配10T以上。(读写效率折中,均有较大提升)
若使用折中方案,另一个问题考虑:
SSD节点即有读操作,也有写操作,节点较少,压力还是较大,怎么实现mysql的主从模式,达到读写分离的效果?
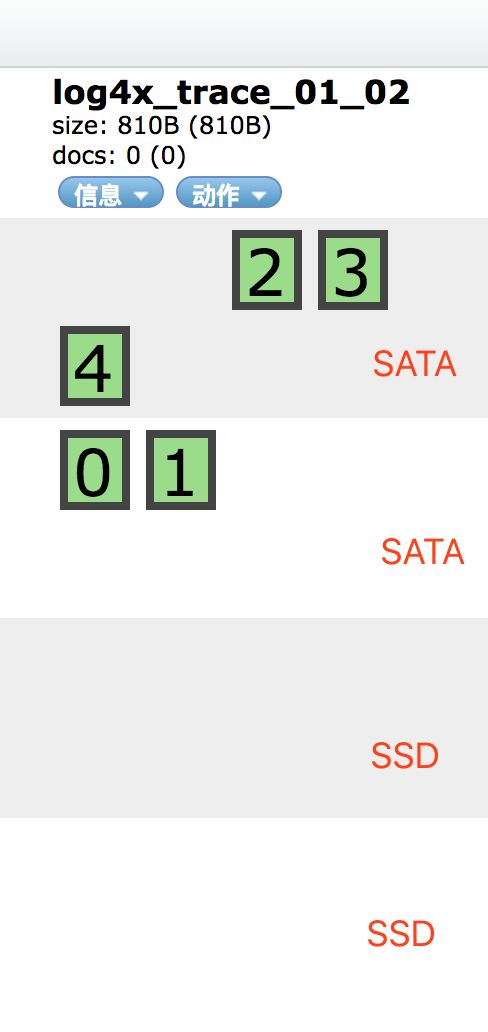
目标:使主分片分配在SSD磁盘上,副本落在SATA磁盘上,读取时优先从副本中查询数据,SSD节点只负责写入数据。
实现步骤:
修改集群路由分配策略配置
增加集群路由配置
"allocation.awareness.attributes": "box_type",
"allocation.awareness.force.box_type.values": "hot,cool"
提前创建索引
提前创建下一天的索引,索引配置如下(可写入模板中):
PUT log4x_trace_2018_08_11
{
"settings": {
"index.routing.allocation.require.box_type": "hot",
"number_of_replicas": 0
}
}
此操作可使索引所有分片都分配在SSD磁盘中。
修改索引路由分配策略配置
索引创建好后,动态修改索引配置
PUT log4x_trace_2018_08_11/_settings
{
"index.routing.allocation.require.box_type": null,
"number_of_replicas": 1
}
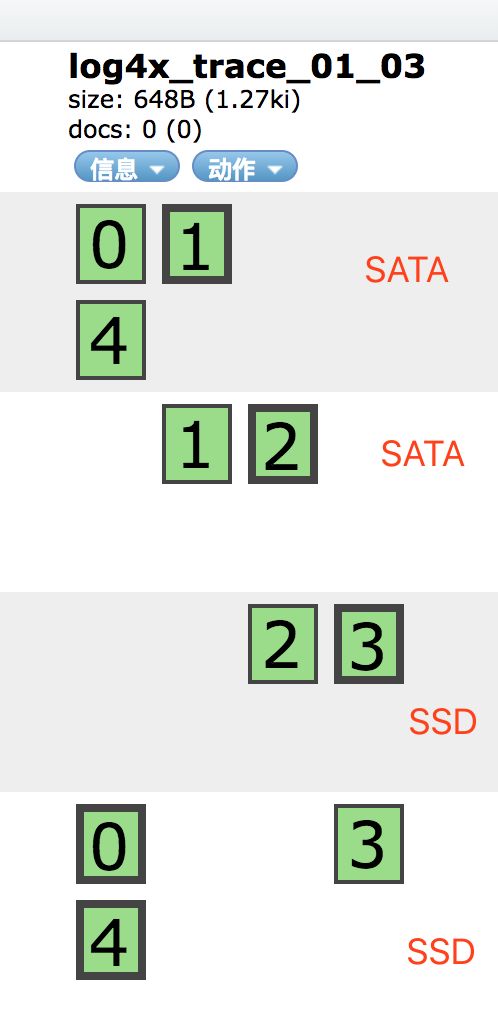
转为冷数据
动态修改索引配置,并取消副本数
PUT log4x_trace_2018_08_11/_settings
{
"index.routing.allocation.require.box_type": "cool",
"number_of_replicas": 0
}