python使用pandas库解析xlsx中的数据、生成xlsx文件
操作步骤
- 导入pandas
- 获取相应sheet的数据
- pd.loc,iloc,ix,axis的区别
- 添加num1、num2、num3列
-
- 读取前两行的数据,dataFrame结构
- 读取后两行数据
- 查看列的名字
- 填充空值
- 计算和
- 计算平均值
- 更改数据格式
- 重命名列
- 数据替换
- 拼接数据
- 数据左连接
- 计算时间差
- 按照特定列排序
- 生成xlsx文件
导入pandas
import pandas as pd
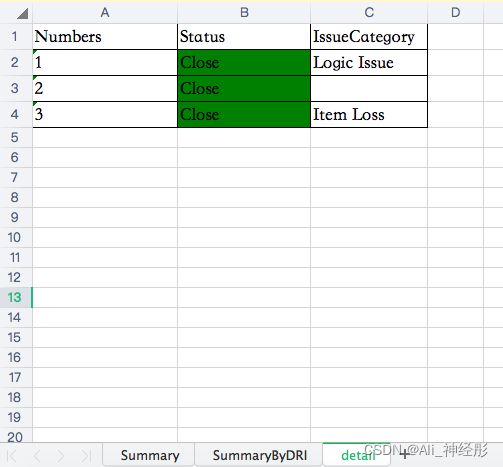
获取相应sheet的数据
- 已知sheet名
df = pd.read_excel('/Users/xyt/Desktop/myFile.xlsx',sheet_name='detail')
# 表格的head(数组)
dataKeys = df.keys()
print("keys----",dataKeys[0])
#数组套数组
print("df---",df)
dataValues = df.values
j=0
for oneValue in dataValues:
j=j+1
print("第 %d 行value---"%(j),oneValue)
for i in range(len(dataKeys)):
# 判断单元格内容是否为空
if pd.isnull(oneValue[i]):
print("this is null")
else:
if i < len(dataKeys)-1:
print(oneValue[i],end=',')
else:
print(oneValue[i])
for index in range(len(df)):
print("df.iloc%d---\n"%(index),df.iloc[index])
输出如下:
keys---- Numbers
df--- Numbers Status IssueCategory
0 1 Close Logic Issue
1 2 Close Limit Issue
2 3 Close Item Loss
第 1 行value--- [1 'Close' 'Logic Issue']
1,Close,Logic Issue
第 2 行value--- [2 'Close' nan]
2,Close,this is null
第 3 行value--- [3 'Close' 'Item Loss']
3,Close,Item Loss
df.iloc0---
Numbers 1
Status Close
IssueCategory Logic Issue
Name: 0, dtype: object
df.iloc1---
Numbers 2
Status Close
IssueCategory Limit Issue
Name: 1, dtype: object
df.iloc2---
Numbers 3
Status Close
IssueCategory Item Loss
Name: 2, dtype: object
- sheet名未知
df = pd.read_excel('/Users/xyt/Desktop/myFile.xlsx',sheet_name=None)
# 通过.keys获取所有的sheet名字,再进行相应处理
print("all sheet---",df.keys())
输出入下:
all sheet--- dict_keys(['Summary', 'SummaryByDRI', 'detail'])
pd.loc,iloc,ix,axis的区别
图片来源

添加num1、num2、num3列

读取前两行的数据,dataFrame结构
df.head(2)df.iloc[0:2]
读取后两行数据
df.tail(2)
查看列的名字
columns = df.columns
print(f"columns 第一次展示 :{columns}")
print(“columns 第二次展示 :{}\n”.format(columns))
填充空值
df.fillna(0, inplace = True) # 用0来填充空值
计算和
# axis=1 计算每一行第4列和第5列的和
# df['num1+num2'] = df.iloc[:,[3,4]].sum(axis=1)
df['num1+num2'] = df.loc[:,['num1','num2']].sum(axis=1)
# print("df['num1+num2']----",df['num1+num2'].values)
# 计算每一行第456列的和
df['num1+num2+num3'] = df.iloc[:,3:6].sum(axis=1)
计算平均值
# 计算每一行456列的平均值存放在avg列 即 num1、num2、num3这三列的平均值
df['avg'] = df.iloc[:,3:6].mean(axis=1)
更改数据格式
df['Numbers'] = df['Numbers'].astype('float')
重命名列
df = df.rename(columns={'Numbers':'my-number'})
数据替换
df['Status'] = df['Status'].replace('close','Open')
拼接数据
# 预处理数据
df2=pd.DataFrame({"my-number":[4,5],
"Status":['Close','Close'],
"IssueCategory":['Item Loss','Item Loss'],
"num1":[10,12],
"num2":[10,12],
"num3":[10,12]})
df2['num1+num2'] = df2.iloc[:,[3,4]].sum(axis=1)
# print("df['num1+num2']----",df['num1+num2'].values)
# 计算每一行第456列的和
df2['num1+num2+num3'] = df2.iloc[:,3:6].sum(axis=1)
df2['avg'] = df2.iloc[:,3:6].mean(axis=1)
# 拼接
df = df.append(df2)
数据左连接
df3=pd.DataFrame({"my-number":[1,2],
"a":['a1','a2'],
"b":['b1','b2'],
"c":['c1','c2']})
'''
表连接
- 内连接 pd.merge(df,df3,how='inner')
- 左连接 pd.merge(df,df3,how='left')
- 右连接 pd.merge(df,df3,how='right')
- 外连接 pd.merge(df,df3,how='outer')
'''
df=pd.merge(df,df3,how='left')
print("df_left",df)
输出如下

计算时间差
from datetime import datetime
# 存储为日期
df['addTime'] = datetime.strptime('2021-12-07 09:49:06', "%Y-%m-%d %H:%M:%S")
# 将当前时间格式化为字符串
df['updateTime'] = datetime.now().strftime(format="%Y-%m-%d %H:%M:%S")
# 转为日期
df['updateTime'] = pd.to_datetime(df['updateTime'])
# 计算日期差
'''
-1 相差秒数
[d.days * 86400 + d.seconds for d in df['日期差']]
-2 相差小时
[(d.days * 86400 + d.seconds) / 3600 for d in df['日期差']]
-3 设置小数点保留位数
[ "%.2f" % ((d.days * 86400 + d.seconds) / 3600) for d in df['日期差']]
'''
df['相差天数'] = df['updateTime'] - df['addTime']
df['相差天数'] = [d.days for d in df['相差天数']]
最终数据如下

按照特定列排序
df.sort_values(by=[‘avg’],axis=0,ascending=False,inplace=True)
生成xlsx文件
df.to_excel(’/Users/xyt/Desktop/new.xlsx’, index=False,sheet_name=‘mySheet’)