【白话机器学习】算法理论+实战之K-Means聚类算法
1. 写在前面
如果想从事数据挖掘或者机器学习的工作,掌握常用的机器学习算法是非常有必要的,常见的机器学习算法:
监督学习算法:逻辑回归,线性回归,决策树,朴素贝叶斯,K近邻,支持向量机,集成算法Adaboost等
无监督算法:聚类,降维,关联规则, PageRank等
为了详细的理解这些原理,曾经看过西瓜书,统计学习方法,机器学习实战等书,也听过一些机器学习的课程,但总感觉话语里比较深奥,读起来没有耐心,并且理论到处有,而实战最重要, 所以在这里想用最浅显易懂的语言写一个白话机器学习算法理论+实战系列。
个人认为,理解算法背后的idea和使用,要比看懂它的数学推导更加重要。idea会让你有一个直观的感受,从而明白算法的合理性,数学推导只是将这种合理性用更加严谨的语言表达出来而已,打个比方,一个梨很甜,用数学的语言可以表述为糖分含量90%,但只有亲自咬一口,你才能真正感觉到这个梨有多甜,也才能真正理解数学上的90%的糖分究竟是怎么样的。如果算法是个梨,本文的首要目的就是先带领大家咬一口。另外还有下面几个目的:
检验自己对算法的理解程度,对算法理论做一个小总结
能开心的学习这些算法的核心思想, 找到学习这些算法的兴趣,为深入的学习这些算法打一个基础。
每一节课的理论都会放一个实战案例,能够真正的做到学以致用,既可以锻炼编程能力,又可以加深算法理论的把握程度。
也想把之前所有的笔记和参考放在一块,方便以后查看时的方便。
学习算法的过程,获得的不应该只有算法理论,还应该有乐趣和解决实际问题的能力!
今天是白话机器学习算法理论+实战的第八篇 之KMeans聚类算法, 听到这个名字,你可别和第七篇K近邻算法搞混了,K-Means 是一种非监督学习,解决的是聚类问题,这里的K表示的是聚成K类。而之前的K近邻算法是监督学习算法,解决的是分类问题,这里的K表示的是K个邻居。相差十万八千里吧, 一条取经路呢。一定要区分开。这个算法也不是很难,前面说道,K近邻算法的原理可以用八个大字叫做“近朱者赤,近墨者黑”来总结,这里我依然放出八个大字:“人以类聚,物以群分”,形容KMeans最好不过了。
通过今天的学习,掌握KMeans算法的工作原理,然后会使用sklearn实现KMeans聚类,最后我们来做一个实战项目:如何使用KMeans对图像进行分割? 下面我们开始吧。
大纲如下:
KMeans聚类的工作原理(结合足球队等级划分谈一谈)
20支亚洲足球队,你能划分出等级吗?(KMeans聚类应用)
KMeans聚类的实战:图像分割
OK, let's go!
2. K-Means的工作原理
上面我们说过,K-Means 是一种非监督学习,解决的是聚类问题。K 代表的是 K 类,Means 代表的是中心,你可以理解这个算法的本质是确定 K 类的中心点,当你找到了这些中心点,也就完成了聚类。
那么这里有两个问题:如何确定K类的中心点?如何把其他类划分到K个类中去?
先别慌, 先和我考虑一个场景,假设我有 20 支亚洲足球队,想要将它们按照成绩划分成 3 个等级,可以怎样划分?
元芳, 你怎么看?
★对亚洲足球队的水平,你可能也有自己的判断。比如一流的亚洲球队有谁?你可能会说伊朗或韩国。二流的亚洲球队呢?你可能说是中国。三流的亚洲球队呢?你可能会说越南。
”
其实这些都是靠我们的经验来划分的,那么伊朗、中国、越南可以说是三个等级的典型代表,也就是我们每个类的中心点。
所以回过头来,如何确定 K 类的中心点?一开始我们是可以随机指派的,当你确认了中心点后,就可以按照距离将其他足球队划分到不同的类别中。
这也就是 K-Means 的中心思想,就是这么简单直接。
你可能会问:如果一开始,选择一流球队是中国,二流球队是伊朗,三流球队是韩国,中心点选择错了怎么办?其实不用担心,K-Means 有自我纠正机制,在不断的迭代过程中,会纠正中心点。中心点在整个迭代过程中,并不是唯一的,只是你需要一个初始值,一般算法会随机设置初始的中心点。
那下面就给出K-Means的工作原理,两步就搞定,就是那两个问题的解决:
选取 K 个点作为初始的类中心点,这些点一般都是从数据集中随机抽取的;
将每个点分配到最近的类中心点,这样就形成了 K 个类,然后重新计算每个类的中心点;(这个怎么算最近,一般是欧几里得距离公式, 那么怎么重新计算每个类的中心点, 每个维度的平均值就可以的)
重复第二步,直到类不发生变化,或者你也可以设置最大迭代次数,这样即使类中心点发生变化,但是只要达到最大迭代次数就会结束。
什么?还不明白? 好吧,那直接看看亚洲球队聚类的例子吧
3. 如何给亚洲球队做聚类
对于机器来说需要数据才能判断类中心点,所以下面整理了 2015-2019 年亚洲球队的排名,如下表所示。
我来说明一下数据概况。
其中 2019 年国际足联的世界排名,2015 年亚洲杯排名均为实际排名。2018 年世界杯中,很多球队没有进入到决赛圈,所以只有进入到决赛圈的球队才有实际的排名。如果是亚洲区预选赛 12 强的球队,排名会设置为 40。如果没有进入亚洲区预选赛 12 强,球队排名会设置为 50。 我们怎么做聚类呢?可以跟着我的思路走了:
我们怎么做聚类呢?可以跟着我的思路走了:
首先,针对上面的排名,我们需要做的就是数据规范化,你可以把这些值划分到[0,1]或者按照均值为 0,方差为 1 的正态分布进行规范化。我先把数值规范化到了[0,1]空间中,得到了下面的数值表:
 如果我们随机选取中国、日本、韩国为三个类的中心点,我们就需要看下这些球队到中心点的距离。
如果我们随机选取中国、日本、韩国为三个类的中心点,我们就需要看下这些球队到中心点的距离。下面就是把其其他样本根据距离中心点的远近划分到这三个类中去,有关距离可以参考KNN那一篇博客。 常用的有欧氏距离,曼哈顿距离等。这里采用欧式距离。
欧氏距离是最常用的距离计算方式,这里选择欧氏距离作为距离的标准,计算每个队伍分别到中国、日本、韩国的距离,然后根据距离远近来划分。我们看到大部分的队,会和中国队聚类到一起。这里我整理了距离的计算过程,比如中国和中国的欧氏距离为 0,中国和日本的欧式距离为 0.732003。如果按照中国、日本、韩国为 3 个分类的中心点,欧氏距离的计算结果如下表所示: 然后我们再重新计算这三个类的中心点,如何计算呢?最简单的方式就是取平均值,然后根据新的中心点按照距离远近重新分配球队的分类,再根据球队的分类更新中心点的位置。计算过程这里不展开,最后一直迭代(重复上述的计算过程:计算中心点和划分分类)到分类不再发生变化,可以得到以下的分类结果:
然后我们再重新计算这三个类的中心点,如何计算呢?最简单的方式就是取平均值,然后根据新的中心点按照距离远近重新分配球队的分类,再根据球队的分类更新中心点的位置。计算过程这里不展开,最后一直迭代(重复上述的计算过程:计算中心点和划分分类)到分类不再发生变化,可以得到以下的分类结果: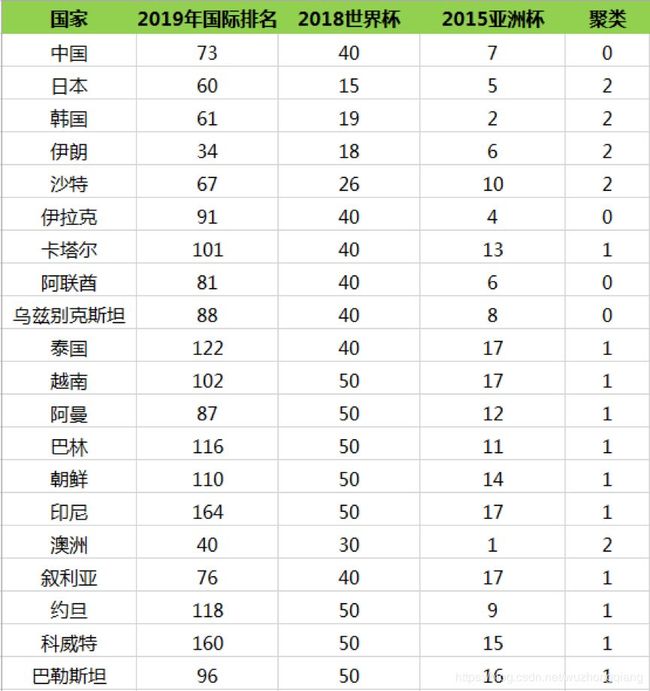 所以我们能看出来第一梯队有日本、韩国、伊朗、沙特、澳洲;第二梯队有中国、伊拉克、阿联酋、乌兹别克斯坦;第三梯队有卡塔尔、泰国、越南、阿曼、巴林、朝鲜、印尼、叙利亚、约旦、科威特和巴勒斯坦。
所以我们能看出来第一梯队有日本、韩国、伊朗、沙特、澳洲;第二梯队有中国、伊拉克、阿联酋、乌兹别克斯坦;第三梯队有卡塔尔、泰国、越南、阿曼、巴林、朝鲜、印尼、叙利亚、约旦、科威特和巴勒斯坦。
这个就是KMeans进行聚类的过程了。简单点,就是反复两个过程:
确定中心点
把其他的点按照距中心点的远近归到相应的中心点
上面这个也可以使用sklearn中的K-Means进行实战一下子,作为图像分割图像的准备期。
4. KMeans聚类实战:如何使用KMeans对图像进行分割?
还是老规矩,我们在实战之前,先看一下如何调用sklearn实现KMeans。
4.1 如何使用sklearn中的KMeans算法
sklearn 是 Python 的机器学习工具库,如果从功能上来划分,sklearn 可以实现分类、聚类、回归、降维、模型选择和预处理等功能。这里我们使用的是 sklearn 的聚类函数库,因此需要引用工具包,具体代码如下:
from sklearn.cluster import KMeans
当然 K-Means 只是 sklearn.cluster 中的一个聚类库,实际上包括 K-Means 在内,sklearn.cluster 一共提供了 9 种聚类方法,比如 Mean-shift,DBSCAN,Spectral clustering(谱聚类)等。这些聚类方法的原理和 K-Means 不同,这里不做介绍。
我们看下 K-Means 如何创建:
KMeans(n_clusters=8, init='k-means++', n_init=10, max_iter=300, tol=0.0001, precompute_distances='auto', verbose=0, random_state=None, copy_x=True, n_jobs=1, algorithm='auto')
这些参数解释一下:
n_clusters: 即 K 值,一般需要多试一些 K 值来保证更好的聚类效果。你可以随机设置一些 K 值,然后选择聚类效果最好的作为最终的 K 值;max_iter:最大迭代次数,如果聚类很难收敛的话,设置最大迭代次数可以让我们及时得到反馈结果,否则程序运行时间会非常长;
n_init:初始化中心点的运算次数,默认是 10。程序是否能快速收敛和中心点的选择关系非常大,所以在中心点选择上多花一些时间,来争取整体时间上的快速收敛还是非常值得的。由于每一次中心点都是随机生成的,这样得到的结果就有好有坏,非常不确定,所以要运行 n_init 次, 取其中最好的作为初始的中心点。如果 K 值比较大的时候,你可以适当增大 n_init 这个值;
init:即初始值选择的方式,默认是采用优化过的 k-means++ 方式,你也可以自己指定中心点,或者采用 random 完全随机的方式。自己设置中心点一般是对于个性化的数据进行设置,很少采用。random 的方式则是完全随机的方式,一般推荐采用优化过的 k-means++ 方式;
algorithm:k-means 的实现算法,有“auto” “full”“elkan”三种。一般来说建议直接用默认的"auto"。简单说下这三个取值的区别,如果你选择"full"采用的是传统的 K-Means 算法,“auto”会根据数据的特点自动选择是选择“full”还是“elkan”。我们一般选择默认的取值,即“auto” 。
在创建好 K-Means 类之后,就可以使用它的方法,最常用的是 fit 和 predict 这个两个函数。你可以单独使用 fit 函数和 predict 函数,也可以合并使用 fit_predict 函数。其中 fit(data) 可以对 data 数据进行 k-Means 聚类。predict(data) 可以针对 data 中的每个样本,计算最近的类。
下面我们先跑一遍20支亚洲球队的聚类问题:数据集在这下载
# coding: utf-8
from sklearn.cluster import KMeans
from sklearn import preprocessing
import pandas as pd
import numpy as np
# 输入数据
data = pd.read_csv('data.csv', encoding='gbk')
train_x = data[["2019年国际排名","2018世界杯","2015亚洲杯"]]
df = pd.DataFrame(train_x)
kmeans = KMeans(n_clusters=3)
# 规范化到[0,1]空间
min_max_scaler=preprocessing.MinMaxScaler()
train_x=min_max_scaler.fit_transform(train_x)
# kmeans算法
kmeans.fit(train_x)
predict_y = kmeans.predict(train_x)
# 合并聚类结果,插入到原数据中
result = pd.concat((data,pd.DataFrame(predict_y)),axis=1)
result.rename({0:u'聚类'},axis=1,inplace=True)
print(result)
运行结果如下:
国家 2019年国际排名 2018世界杯 2015亚洲杯 聚类
0 中国 734072
1 日本 601550
2 韩国 611920
3 伊朗 341860
4 沙特 6726100
5 伊拉克 914042
6 卡塔尔 10140131
7 阿联酋 814062
8 乌兹别克斯坦 884082
9 泰国 12240171
10 越南 10250171
11 阿曼 8750121
12 巴林 11650111
13 朝鲜 11050141
14 印尼 16450171
15 澳洲 403010
16 叙利亚 7640171
17 约旦 1185091
18 科威特 16050151
19 巴勒斯坦 9650161
4.2 如何用KMeans对图像进行分割?
图像分割就是利用图像自身的信息,比如颜色、纹理、形状等特征进行划分,将图像分割成不同的区域,划分出来的每个区域就相当于是对图像中的像素进行了聚类。单个区域内的像素之间的相似度大,不同区域间的像素差异性大。这个特性正好符合聚类的特性,所以你可以把图像分割看成是将图像中的信息进行聚类。当然聚类只是分割图像的一种方式,除了聚类,我们还可以基于图像颜色的阈值进行分割,或者基于图像边缘的信息进行分割等。
将微信开屏封面进行分割。
我们现在用 K-Means 算法对微信页面进行分割。微信开屏图如下所示: 我们先设定下聚类的流程,聚类的流程和分类差不多,如图所示:
我们先设定下聚类的流程,聚类的流程和分类差不多,如图所示: 在准备阶段里,我们需要对数据进行加载。因为处理的是图像信息,我们除了要获取图像数据以外,还需要获取图像的尺寸和通道数,然后基于图像中每个通道的数值进行数据规范化。这里我们需要定义个函数 load_data,来帮我们进行图像加载和数据规范化。代码如下:
在准备阶段里,我们需要对数据进行加载。因为处理的是图像信息,我们除了要获取图像数据以外,还需要获取图像的尺寸和通道数,然后基于图像中每个通道的数值进行数据规范化。这里我们需要定义个函数 load_data,来帮我们进行图像加载和数据规范化。代码如下:
# 加载图像,并对数据进行规范化
def load_data(filePath):
# 读文件
f = open(filePath,'rb')
data = []
# 得到图像的像素值
img = image.open(f)
# 得到图像尺寸
width, height = img.size
for x in range(width):
for y in range(height):
# 得到点(x,y)的三个通道值
c1, c2, c3 = img.getpixel((x, y))
data.append([c1, c2, c3])
f.close()
# 采用Min-Max规范化
mm = preprocessing.MinMaxScaler()
data = mm.fit_transform(data)
return np.mat(data), width, height
因为 jpg 格式的图像是三个通道 (R,G,B),也就是一个像素点具有 3 个特征值。这里我们用 c1、c2、c3 来获取平面坐标点 (x,y) 的三个特征值,特征值是在 0-255 之间。
为了加快聚类的收敛,我们需要采用 Min-Max 规范化对数据进行规范化。我们定义的 load_data 函数返回的结果包括了针对 (R,G,B) 三个通道规范化的数据,以及图像的尺寸信息。在定义好 load_data 函数后,我们直接调用就可以得到相关信息,代码如下:
# 加载图像,得到规范化的结果img,以及图像尺寸
img, width, height = load_data('./weixin.jpg')
假设我们想要对图像分割成 2 部分,在聚类阶段,我们可以将聚类数设置为 2,这样图像就自动聚成 2 类。代码如下:
# 用K-Means对图像进行2聚类
kmeans =KMeans(n_clusters=2)
kmeans.fit(img)
label = kmeans.predict(img)
# 将图像聚类结果,转化成图像尺寸的矩阵
label = label.reshape([width, height])
# 创建个新图像pic_mark,用来保存图像聚类的结果,并设置不同的灰度值
pic_mark = image.new("L", (width, height))
for x in range(width):
for y in range(height):
# 根据类别设置图像灰度, 类别0 灰度值为255, 类别1 灰度值为127
pic_mark.putpixel((x, y), int(256/(label[x][y]+1))-1)
pic_mark.save("weixin_mark.jpg", "JPEG")
代码中有一些参数,下面说一下这些参数的作用和设置方法:
★我们使用了 fit 和 predict 这两个函数来做数据的训练拟合和预测,因为传入的参数是一样的,我们可以同时进行 fit 和 predict 操作,这样我们可以直接使用 fit_predict(data) 得到聚类的结果。得到聚类的结果 label 后,实际上是一个一维的向量,我们需要把它转化成图像尺寸的矩阵。label 的聚类结果是从 0 开始统计的,当聚类数为 2 的时候,聚类的标识 label=0 或者 1。
”
如果你想对图像聚类的结果进行可视化,直接看 0 和 1 是看不出来的,还需要将 0 和 1 转化为灰度值。灰度值一般是在 0-255 的范围内,我们可以将 label=0 设定为灰度值 255,label=1 设定为灰度值 127。具体方法是用 int(256/(label[x][y]+1))-1。可视化的时候,主要是通过设置图像的灰度值进行显示。所以我们把聚类 label=0 的像素点都统一设置灰度值为 255,把聚类 label=1 的像素点都统一设置灰度值为 127。原来图像的灰度值是在 0-255 之间,现在就只有 2 种颜色(也就是灰度为 255,和灰度 127)。
有了这些灰度信息,我们就可以用 image.new 创建一个新的图像,用 putpixel 函数对新图像的点进行灰度值的设置,最后用 save 函数保存聚类的灰度图像。这样你就可以看到聚类的可视化结果了,如下图所示: 如果我们想要分割成 16 个部分,该如何对不同分类设置不同的颜色值呢?这里需要用到 skimage 工具包,它是图像处理工具包。你需要使用 pip install scikit-image 来进行安装。这段代码可以将聚类标识矩阵转化为不同颜色的矩阵:
如果我们想要分割成 16 个部分,该如何对不同分类设置不同的颜色值呢?这里需要用到 skimage 工具包,它是图像处理工具包。你需要使用 pip install scikit-image 来进行安装。这段代码可以将聚类标识矩阵转化为不同颜色的矩阵:
from skimage import color
# 将聚类标识矩阵转化为不同颜色的矩阵
label_color = (color.label2rgb(label)*255).astype(np.uint8)
label_color = label_color.transpose(1,0,2)
images = image.fromarray(label_color)
images.save('weixin_mark_color.jpg')
代码中,我使用 skimage 中的 label2rgb 函数来将 label 分类标识转化为颜色数值,因为我们的颜色值范围是[0,255],所以还需要乘以 255 进行转化,最后再转化为 np.uint8 类型。unit8 类型代表无符号整数,范围是 0-255 之间。
得到颜色矩阵后,你可以把它输出出来,这时你发现输出的图像是颠倒的,原因可能是图像源拍摄的时候本身是倒置的。我们需要设置三维矩阵的转置,让第一维和第二维颠倒过来,也就是使用 transpose(1,0,2),将原来的 (0,1,2)顺序转化为 (1,0,2) 顺序,即第一维和第二维互换。
最后我们使用 fromarray 函数,它可以通过矩阵来生成图片,并使用 save 进行保存。最后得到的分类标识颜色化图像是这样的: 刚才我们做的是聚类的可视化。如果我们想要看到对应的原图,可以将每个簇(即每个类别)的点的 RGB 值设置为该簇质心点的 RGB 值,也就是簇内的点的特征均为质心点的特征。
刚才我们做的是聚类的可视化。如果我们想要看到对应的原图,可以将每个簇(即每个类别)的点的 RGB 值设置为该簇质心点的 RGB 值,也就是簇内的点的特征均为质心点的特征。
我给出了完整的代码,代码中,我可以把范围为 0-255 的数值投射到 1-256 数值之间,方法是对每个数值进行加 1,你可以自己来运行下:
# -*- coding: utf-8 -*-
# 使用K-means对图像进行聚类,并显示聚类压缩后的图像
import numpy as np
import PIL.Image as image
from sklearn.cluster import KMeans
from sklearn import preprocessing
import matplotlib.image as mpimg
# 加载图像,并对数据进行规范化
def load_data(filePath):
# 读文件
f = open(filePath,'rb')
data = []
# 得到图像的像素值
img = image.open(f)
# 得到图像尺寸
width, height = img.size
for x in range(width):
for y in range(height):
# 得到点(x,y)的三个通道值
c1, c2, c3 = img.getpixel((x, y))
data.append([(c1+1)/256.0, (c2+1)/256.0, (c3+1)/256.0])
f.close()
return np.mat(data), width, height
# 加载图像,得到规范化的结果imgData,以及图像尺寸
img, width, height = load_data('./weixin.jpg')
# 用K-Means对图像进行16聚类
kmeans =KMeans(n_clusters=16)
label = kmeans.fit_predict(img)
# 将图像聚类结果,转化成图像尺寸的矩阵
label = label.reshape([width, height])
# 创建个新图像img,用来保存图像聚类压缩后的结果
img=image.new('RGB', (width, height))
for x in range(width):
for y in range(height):
c1 = kmeans.cluster_centers_[label[x, y], 0]
c2 = kmeans.cluster_centers_[label[x, y], 1]
c3 = kmeans.cluster_centers_[label[x, y], 2]
img.putpixel((x, y), (int(c1*256)-1, int(c2*256)-1, int(c3*256)-1))
img.save('weixin_new.jpg')
结果如下: 你可以看到我没有用到 sklearn 自带的 MinMaxScaler,而是自己写了 Min-Max 规范化的公式。这样做的原因是我们知道 RGB 每个通道的数值在[0,255]之间,所以我们可以用每个通道的数值 +1/256,这样数值就会在[0,1]之间。
你可以看到我没有用到 sklearn 自带的 MinMaxScaler,而是自己写了 Min-Max 规范化的公式。这样做的原因是我们知道 RGB 每个通道的数值在[0,255]之间,所以我们可以用每个通道的数值 +1/256,这样数值就会在[0,1]之间。
对图像做了 Min-Max 空间变换之后,还可以对其进行反变换,还原出对应原图的通道值。对于点 (x,y),我们找到它们所属的簇 label[x,y],然后得到这个簇的质心特征,用 c1,c2,c3 表示:
c1 = kmeans.cluster_centers_[label[x, y], 0]
c2 = kmeans.cluster_centers_[label[x, y], 1]
c3 = kmeans.cluster_centers_[label[x, y], 2]
因为 c1, c2, c3 对应的是数据规范化的数值,因此我们还需要进行反变换,即:
c1=int(c1*256)-1
c2=int(c2*256)-1
c3=int(c3*256)-1
然后用 img.putpixel 设置点 (x,y) 反变换后得到的特征值。最后用 img.save 保存图像。
5. 总结
好了,写到这关于KMeans,就要结束了。下面快速的回顾一下:
首先,通过足球队聚类的例子引出了KMeans聚类的工作原理,简单来说两步,你可以回忆回忆。
然后,通过KMeans实现了对图像分割的实战,另外我们还学习了如何在 Python 中如何对图像进行读写,具体的代码如下,上文中也有相应代码,你也可以自己对应下:
import PIL.Image as image
# 得到图像的像素值
img = image.open(f)
# 得到图像尺寸
width, height = img.size
这里会使用 PIL 这个工具包,它的英文全称叫 Python Imaging Library,顾名思义,它是 Python 图像处理标准库。同时我们也使用到了 skimage 工具包(scikit-image),它也是图像处理工具包。用过 Matlab 的同学知道,Matlab 处理起图像来非常方便。skimage 可以和它相媲美,集成了很多图像处理函数,其中对不同分类标识显示不同的颜色。在 Python 中图像处理工具包,我们用的是 skimage 工具包。
好了,KMeans的故事就到这里吧。
参考:
http://note.youdao.com/noteshare?id=10dac8bb5d83358ffe73c792e1490a7b&sub=C7A3E74A1088435ABBE11AB91AC37194
https://time.geekbang.org/