Mnist分类任务
参考
Mnist分类任务:
-
网络基本构建与训练方法,常用函数解析
-
torch.nn.functional模块
-
nn.Module模块
读取Mnist数据集
- 会自动进行下载
%matplotlib inline
from pathlib import Path
import requests
DATA_PATH = Path("data")
PATH = DATA_PATH / "mnist"
PATH.mkdir(parents=True, exist_ok=True)
URL = "http://deeplearning.net/data/mnist/"
FILENAME = "mnist.pkl.gz"
if not (PATH / FILENAME).exists():
content = requests.get(URL + FILENAME).content
(PATH / FILENAME).open("wb").write(content)
import pickle
import gzip
with gzip.open((PATH / FILENAME).as_posix(), "rb") as f:
((x_train, y_train), (x_valid, y_valid), _) = pickle.load(f, encoding="latin-1")
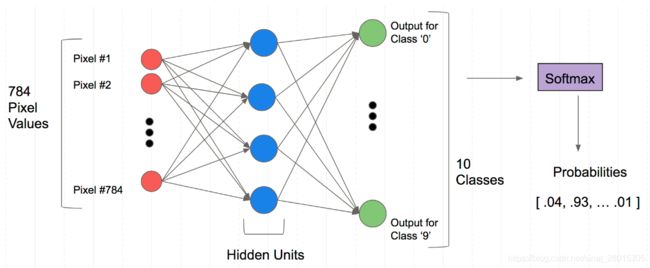
minist 数据集每个样本的像素点个数为 784
import matplotlib.pyplot as plt
import numpy as np
plt.imshow(x_train[0].reshape((28, 28)), cmap="gray")
print(x_train.shape) # 784 --> 28*28*1 , H*W*C
(50000, 784)

jupyter 导入图片
from IPython.display import Image
Image(filename = 'path')

import torch
# 将数据转换为tensor进行后续训练
x_train, y_train, x_valid, y_valid = map(torch.tensor, (x_train, y_train, x_valid, y_valid))
n, c = x_train.shape
x_train, x_train.shape, y_train.min(), y_train.max()
print(x_train, y_train)
print(x_train.shape)
print(y_train.min(), y_train.max())
tensor([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]) tensor([5, 0, 4, ..., 8, 4, 8])
torch.Size([50000, 784])
tensor(0) tensor(9)
torch.nn.functional
一般情况下,如果模型有可学习的参数,最好用nn.Module,其他情况nn.functional(如激活函数、损失函数)相对更简单一些
import torch.nn.functional as F
loss_func = F.cross_entropy
def model(xb):
return xb.mm(weights) + bias
bs = 64
xb = x_train[:bs] # batch
yb = y_train[:bs]
weights = torch.randn([784, 10], dtype = torch.float, requires_grad = True)
bias = torch.zeros(10, requires_grad = True)
print(loss_func(model(xb),yb))
tensor(15.3532, grad_fn=<NllLossBackward>)
构建模型
- 必须继承nn.Module且在其构造函数中需调用nn.Module的构造函数
- 无需写反向传播函数,nn.Module能够利用autograd自动实现反向传播
- Module中的可学习参数可以通过named_parameters()或者parameters()返回迭代器
import torch.nn as nn
class Mnist_NN(nn.Module):
def __init__(self):
super(Mnist_NN, self).__init__()
self.hidden1 = nn.Linear(784, 128)
self.hidden2 = nn.Linear(128, 256)
self.out = nn.Linear(256, 10)
def forward(self, x):
x = F.relu(self.hidden1(x))
x = F.relu(self.hidden2(x))
return self.out(x)
net = Mnist_NN()
print(net)
Mnist_NN(
(hidden1): Linear(in_features=784, out_features=128, bias=True)
(hidden2): Linear(in_features=128, out_features=256, bias=True)
(out): Linear(in_features=256, out_features=10, bias=True)
)
打印权重和偏置项
for name, parameter in net.named_parameters():
print(name, parameter, parameter.size())
hidden1.weight Parameter containing:
tensor([[ 0.0254, -0.0086, -0.0126, ..., 0.0136, 0.0186, 0.0039],
[-0.0018, -0.0231, -0.0341, ..., 0.0008, -0.0026, -0.0084],
[-0.0281, -0.0042, -0.0078, ..., -0.0317, 0.0121, -0.0097],
...,
[ 0.0093, 0.0152, -0.0289, ..., 0.0039, -0.0213, 0.0186],
[-0.0256, -0.0167, -0.0294, ..., 0.0328, 0.0083, -0.0089],
[ 0.0250, -0.0224, 0.0345, ..., 0.0154, -0.0297, 0.0179]],
requires_grad=True) torch.Size([128, 784])
hidden1.bias Parameter containing:
tensor([-6.5502e-03, -5.5020e-03, -3.2130e-02, -3.3698e-02, -3.7882e-03,
4.3483e-03, -1.1440e-02, -2.5736e-02, -1.3230e-02, 1.8212e-02,
1.4735e-02, -2.8692e-02, -1.9248e-02, -1.6134e-02, 2.6542e-02,
-2.3506e-02, 1.9662e-02, -3.4623e-02, -2.3149e-02, -2.8246e-02,
1.9046e-02, 9.0913e-04, -1.9846e-02, 1.7235e-02, 1.1492e-02,
-1.6770e-02, -1.4115e-02, -9.3709e-03, -2.3016e-02, -5.6963e-05,
-5.3043e-03, 1.3980e-02, 1.4813e-02, -2.2603e-02, -1.3933e-02,
5.0620e-03, 1.3708e-02, -3.3913e-02, -1.4046e-02, -2.1119e-02,
3.1775e-02, 3.2746e-02, -8.8494e-03, -9.8448e-03, 2.2414e-02,
-1.2001e-02, -1.2603e-02, -3.0907e-02, 3.3045e-02, -1.1636e-02,
-9.3357e-03, 3.1828e-02, 5.6664e-04, -2.9685e-02, 1.4453e-02,
-3.1200e-02, -2.1885e-02, 1.6815e-02, 4.2410e-03, -3.5402e-02,
3.0180e-02, 3.3961e-02, -1.1829e-02, 8.7620e-03, -2.7341e-02,
-3.4919e-02, 3.3052e-02, 2.0017e-02, -5.5200e-03, -2.6593e-02,
-2.0800e-02, -3.4543e-02, -6.6311e-03, -3.1868e-03, -3.6205e-03,
-2.4685e-02, 3.1324e-02, -3.1354e-03, -2.0892e-02, -1.8177e-02,
-2.6288e-02, 1.6119e-02, 1.7610e-02, 1.5385e-02, 1.3507e-02,
-1.1772e-02, 1.5924e-02, 3.3665e-02, -1.1112e-02, 7.4026e-03,
1.9150e-02, -2.1051e-02, 2.3446e-03, -8.3934e-03, -6.7710e-03,
2.2514e-03, 1.6836e-02, 1.0848e-02, -3.0801e-02, 2.1783e-03,
-3.1347e-03, -2.9991e-02, -7.4200e-03, -3.0242e-02, 3.2102e-02,
-5.3846e-03, 1.8788e-02, 1.9407e-02, 1.7531e-02, -2.6160e-02,
-2.8468e-02, 2.4840e-03, -1.1963e-02, -3.3299e-02, -2.0726e-02,
3.6885e-03, -2.7398e-02, 2.3647e-02, -2.7768e-02, -7.7109e-04,
-2.8763e-02, 3.3596e-02, -1.6966e-02, -6.5043e-03, 1.0516e-02,
-1.1469e-02, 1.5004e-02, 3.1973e-02], requires_grad=True) torch.Size([128])
hidden2.weight Parameter containing:
tensor([[-0.0347, 0.0167, -0.0324, ..., -0.0582, 0.0603, 0.0834],
[ 0.0720, -0.0335, -0.0762, ..., 0.0224, -0.0405, 0.0167],
[ 0.0356, 0.0801, -0.0104, ..., 0.0505, 0.0144, -0.0683],
...,
[-0.0317, 0.0338, -0.0141, ..., -0.0784, 0.0405, 0.0139],
[ 0.0221, 0.0389, 0.0688, ..., 0.0255, 0.0720, 0.0392],
[-0.0772, 0.0241, 0.0877, ..., -0.0487, 0.0440, -0.0370]],
requires_grad=True) torch.Size([256, 128])
hidden2.bias Parameter containing:
tensor([-4.4112e-02, -2.9887e-02, -2.8265e-02, -3.3286e-02, 7.2502e-02,
8.0232e-02, 1.8865e-03, 9.7098e-03, 3.1223e-02, -2.2631e-02,
-2.1214e-02, 3.1150e-02, 6.1466e-02, 7.0035e-02, -4.5615e-02,
-5.8772e-02, 6.2894e-02, 4.9750e-02, 5.7451e-02, 2.2339e-02,
2.6763e-02, 8.7752e-02, -5.7866e-02, -4.4658e-02, 1.2571e-02,
5.1465e-02, 3.1973e-02, 1.6999e-02, 1.0167e-02, -7.5020e-02,
5.2646e-02, 1.4925e-03, -2.8097e-02, 5.1080e-02, -4.3607e-02,
-1.0488e-02, -4.1806e-02, -2.6486e-02, -2.9917e-02, -1.4247e-02,
-8.1358e-02, -4.8308e-02, 1.0190e-02, -8.7466e-02, -3.2915e-02,
-2.2256e-02, -2.7506e-02, 5.0168e-02, -3.7357e-02, -6.6164e-02,
-4.8030e-02, 7.9535e-02, -7.8770e-02, 5.7002e-02, -8.2957e-02,
7.9409e-02, 6.7863e-02, 5.5029e-02, -1.3148e-02, 6.7071e-02,
6.9344e-02, 8.2403e-02, 7.7624e-04, 2.6836e-03, -1.0046e-02,
9.3734e-03, -6.5549e-02, -3.2896e-02, 2.6147e-02, -1.7230e-02,
8.6758e-02, -1.4608e-02, -8.7553e-02, -7.8356e-02, 7.3508e-02,
-6.6287e-03, 3.2445e-03, 4.2771e-02, 1.6711e-02, -9.7339e-03,
1.8356e-02, 8.2133e-02, 5.8495e-02, 2.1896e-02, -1.9515e-02,
4.5635e-02, 4.9553e-02, 6.5750e-02, 1.4359e-03, -5.5184e-02,
-2.4005e-02, 4.1542e-03, -5.3008e-02, 4.3737e-02, -8.1441e-02,
-6.3477e-03, -3.2300e-02, -2.7014e-02, 7.8015e-02, 3.1171e-02,
-7.1218e-02, -4.8229e-02, 6.4831e-02, 3.1426e-03, 3.5155e-02,
7.0181e-02, 7.6853e-02, 7.5148e-02, 6.6496e-02, -3.5201e-02,
6.1620e-02, -8.0127e-02, -6.0731e-02, -8.1545e-02, 5.2329e-02,
3.4222e-02, -3.3294e-02, 1.9992e-02, 8.7442e-02, -8.2247e-02,
-6.2127e-02, 9.7789e-03, 5.2960e-02, 1.2544e-02, 3.8694e-02,
-8.9400e-04, 8.6839e-02, -1.3664e-04, -6.2805e-02, -3.1600e-02,
-1.5621e-02, -7.9170e-02, -6.3270e-02, -3.4443e-02, 6.0702e-02,
4.0426e-02, -4.4049e-02, 7.5615e-02, 3.2658e-02, 7.6719e-05,
-1.6568e-02, -6.0935e-02, -7.8334e-02, -5.0843e-02, 3.5265e-02,
8.2918e-02, -1.1703e-02, 4.2792e-02, -2.1638e-02, 8.1203e-02,
7.2390e-02, 5.1223e-02, -2.9995e-02, 5.9169e-02, -4.4215e-02,
-5.9534e-02, 8.7776e-02, -6.9242e-02, -4.1378e-02, -5.9089e-03,
-2.5731e-02, 5.4990e-03, -1.4946e-02, 4.4629e-02, -5.5693e-02,
5.4679e-02, 4.8887e-02, -3.2876e-02, 5.8299e-02, -3.6360e-03,
8.2118e-02, 5.4893e-02, 8.5792e-02, -1.4165e-02, 6.2316e-02,
3.0707e-02, -2.0505e-03, 8.3190e-02, -4.6698e-03, -4.1325e-02,
1.2834e-02, -3.4875e-02, -3.5632e-02, -7.9326e-02, 8.3959e-02,
2.5515e-02, -6.2535e-02, 8.2259e-03, 1.6056e-02, 2.5417e-03,
9.4396e-03, -7.8076e-02, -3.2177e-02, -5.5346e-02, -4.9452e-02,
-7.5331e-02, 8.1705e-02, -8.7080e-02, 1.2553e-02, 7.7827e-02,
-3.2539e-02, -1.3828e-02, -8.4033e-02, -7.8187e-02, 1.8038e-02,
-6.0549e-02, 9.6873e-03, 8.8103e-02, 6.0122e-02, -4.4501e-02,
2.7200e-02, -2.9700e-02, 7.2213e-02, -7.7957e-02, -5.8321e-02,
4.1538e-03, 3.3013e-02, 5.8974e-02, -2.5956e-02, -7.1387e-02,
-6.4368e-02, 7.6615e-02, -1.6766e-02, 8.0093e-02, 6.8445e-02,
8.3135e-02, -7.3480e-02, 3.9200e-02, -1.9807e-02, 5.4121e-02,
6.0608e-02, -1.9772e-02, -7.2825e-03, 5.8620e-02, -8.8234e-02,
-3.2589e-03, -5.0743e-03, 1.0887e-02, -7.5440e-03, 7.1621e-02,
-4.9204e-02, 3.3991e-02, 6.5276e-02, -6.6759e-02, 4.1546e-02,
2.3619e-02, -2.9659e-02, -7.3076e-02, -8.2609e-02, -1.0342e-02,
8.2861e-02, 1.0027e-02, -2.5046e-02, 3.9917e-02, -2.7212e-02,
-2.1461e-02], requires_grad=True) torch.Size([256])
out.weight Parameter containing:
tensor([[ 0.0095, 0.0141, -0.0027, ..., 0.0513, 0.0086, 0.0472],
[ 0.0109, 0.0500, -0.0060, ..., -0.0260, 0.0032, -0.0464],
[-0.0083, -0.0227, -0.0512, ..., 0.0108, -0.0503, 0.0396],
...,
[ 0.0596, 0.0050, -0.0049, ..., 0.0406, 0.0231, 0.0435],
[ 0.0562, 0.0624, 0.0522, ..., 0.0311, -0.0034, 0.0553],
[-0.0130, -0.0108, -0.0064, ..., 0.0567, -0.0260, 0.0179]],
requires_grad=True) torch.Size([10, 256])
out.bias Parameter containing:
tensor([-0.0549, 0.0200, -0.0585, -0.0196, 0.0322, 0.0346, -0.0047, 0.0268,
0.0280, -0.0420], requires_grad=True) torch.Size([10])
使用TensorDataset和DataLoader
from torch.utils.data import TensorDataset, DataLoader
bs = 64
train_ds = TensorDataset(x_train, y_train)
train_dl = DataLoader(dataset = train_ds, batch_size = bs, shuffle = True)
valid_ds = TensorDataset(x_valid, y_valid)
valid_dl = DataLoader(dataset = valid_ds, batch_size = bs * 2)
def get_dataloader(train_ds, valid_ds, batch_size):
return (
DataLoader(dataset = train_ds, batch_size = batch_size, shuffle = True),
DataLoader(dataset = valid_ds, batch_size = batch_size * 2)
)
一般在训练模型时加上model.train(),这样会正常使用Batch Normalization和 Dropout
测试的时候一般选择model.eval(),这样就不会使用Batch Normalization和 Dropout
import numpy as np
def loss_batch(model, loss_func, xb, yb, opt=None):
# 前向计算
loss = loss_func(model(xb), yb)
if opt is not None:
# 梯度置0
opt.zero_grad()
# 反向传播
loss.backward()
# 更新参数
opt.step()
return loss.item(), len(xb)
def fit(steps, model, loss_func, opt, train_dl, valid_dl):
for step in range(steps):
model.train()
for xb, yb in train_dl:
loss_batch(model, loss_func, xb, yb, opt)
model.eval()
with torch.no_grad():
losses, nums = zip(*[loss_batch(model, loss_func, xb, yb) for xb, yb in valid_dl])
val_loss = np.sum(np.multiply(losses, nums)) / np.sum(nums)
print('当前step:'+str(step), '验证集损失:'+str(val_loss))
from torch.optim import SGD
def get_model():
model = Mnist_NN()
return model, SGD(model.parameters(), lr = 0.001)
train_dl, valid_dl = get_dataloader(train_ds, valid_ds, bs)
model, opt = get_model()
fit(25, model, loss_func, opt, train_dl, valid_dl)
当前step:0 验证集损失:2.275792053222656
当前step:1 验证集损失:2.2407693840026854
当前step:2 验证集损失:2.187168152999878
当前step:3 验证集损失:2.0995729919433592
当前step:4 验证集损失:1.957993221282959
当前step:5 验证集损失:1.7496695947647094
当前step:6 验证集损失:1.4938231435775757
当前step:7 验证集损失:1.246651389503479
当前step:8 验证集损失:1.0482983011245728
当前step:9 验证集损失:0.9003914960861206
当前step:10 验证集损失:0.7902145584106446
当前step:11 验证集损失:0.7077002679824829
当前step:12 验证集损失:0.6448616947174072
当前step:13 验证集损失:0.5954384657859803
当前step:14 验证集损失:0.5561129764556885
当前step:15 验证集损失:0.524388509464264
当前step:16 验证集损失:0.49813378930091856
当前step:17 验证集损失:0.4757344177246094
当前step:18 验证集损失:0.4564040184020996
当前step:19 验证集损失:0.4398327290534973
当前step:20 验证集损失:0.4252701699256897
当前step:21 验证集损失:0.4126383014202118
当前step:22 验证集损失:0.40154306089878083
当前step:23 验证集损失:0.39144011669158935
当前step:24 验证集损失:0.3828064109802246