OpenPose学习笔记
简介
OpenPose是基于卷积神经网络和监督学习并以caffe为框架写成的开源库,可以实现人的面部表情、躯干和四肢甚至手指的跟踪,不仅适用于单人也适用于多人,同时具有较好的鲁棒性。可以称是世界上第一个基于深度学习的实时多人二维姿态估计,是人机交互上的一个里程碑,为机器理解人提供了一个高质量的信息维度。作者均来自卡耐基梅隆大学(CMU)
项目地址:https://github.com/CMU-Perceptual-Computing-Lab/openpose
OpenPose中文文档:https://www.jianshu.com/p/3aa810b35a5d
资源链接
CMU团队的OpenPose项目可谓成果丰厚,此前已经发表了三篇CVPR,下面会给出原文链接,
Convolutional Pose Machines (2016CVPR)
Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields(2017CVPR)
Hand Keypoint Detection in Single Images using Multiview Bootstrapping(2017CVPR)
而OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields这篇论文则是作者们整理了前面3篇论文的成果发表在IEEE Transactions on Pattern Analysis and Machine Intelligence上,并且扩增了Foot数据集,实现了全身姿态估计(脸部、身体、手部、脚步)。
并且这个项目目前还在维护更新,最新版本为OpenPose v1.7.0,
下载地址:https://github.com/CMU-Perceptual-Computing-Lab/openpose/releases/tag/v1.7.0
算法流程
- 输入一幅或batchsize图像,经过卷积网络(vgg19前10层)提取特征,得到一组特征图,然后经过两个branch,分别再用CNN提取Part Confidence Maps和Part Affinity Fields;
- 得到上面两个信息后,使用 Bipartite Matching(偶匹配) 求出Part Association,将同一个人的关节点连接起来,由于PAF自身的矢量性,使得生成的偶匹配很正确,最终合并为一个人的整体骨架;
- 最后基于PAFs求Multi-Person Parsing,将多人检测问题转化为二分图匹配问题,并用Hungarian Algorithm(匈牙利算法)求得相连关键点最优匹配。

匈牙利算法是部图匹配最常见的算法,该算法的核心就是寻找增广路径,它是一种用增广路径求二分图最大匹配的算法。
二分图是图的一种特例,图中包含两个点群X、Y,同一个点群内无边,不同点群之间有边。
二分匹配即二分图上进行匹配,一个点群中的点只与另一个点群中的点进行唯一匹配,即任意两条边没有公共顶点 。
值得注意的是,Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields这篇论文作为OpenPose的主体部分,其前后的网络结构发生了一些变化,旧版的网络结构有两个并行的分支(PCM和PAF),而新版的结构改为先PAF后PCM的串行结构,这样在COCO测试集上的AP由原来的61.8提升至64.2。
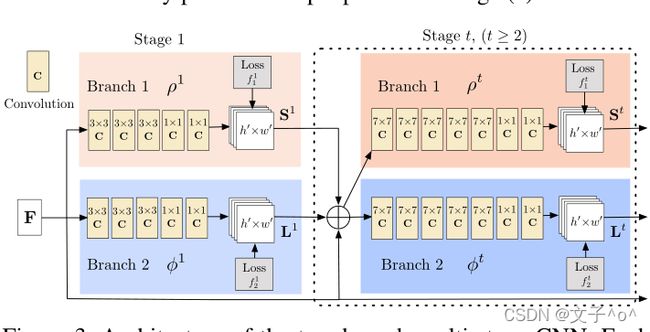
旧版OpenPose网络结构图

新版OpenPose网络结构图
OpenPose的三大亮点
PAF-Part Affinity Fields (核心贡献)
我们知道人体姿态估计主要有top-down和bottem-up这两种方法。其中Top-down是先把图像中的一个个的人给检测出来,然后再用单人姿态估计方法检测每个个体的所有关键点,但是top-down方法的性能好坏取决于两个关键问题。其一是个体检测器的好坏,如果个体检测器效果不好,会严重影响后续关键点的检测。其二,它的计算时间和个体数正相关,个体数越多越耗费时间。
而openpose是 bottem-up方法,即先找出图像中的所有个体的关键点,然后再把这些关键点组装成一个个的人体骨架。但是这种办法还是有所缺陷,就是没办法很好的利用全局上下文信息。
为了解决这个问题,作者提出了PAF(Part Affinity Fields),部分亲和字段。PAF是一个2D矢量,它负责在图像域上编码肢体的位置和方向。同时,使用PCM(Part Detection Confidence Maps)标记每一个关键点的置信度(就是常说的“热图”,即论文中常见的heatmap)。通过两个分支,联合学习关键点位置和他们之间的联系。
PAF说白了就是用来描述两个关键点之间是否相连以及相应的方向信息的。
高鲁棒性
其实我也不知道为啥不少中文文献以及博客把robust翻译成鲁棒性,就叫健壮性或者稳定性不好吗(当然这是题外话)。
之所以说高鲁棒性是其亮点之一,是因为CMU为其提供了海量的高质量的数据,使得仅仅基于2D图像就可以实现鲁棒性很好的人体姿态检测。CMU采用自建的“球体”设备采集数据。大球上面镶嵌了480 VGA cameras+31 HD cameras+10 Kinect Ⅱ Sensors+5 DLP Projectors。并且,全部实现了硬件同步。财大气粗的CMU为了这个项目可是砸了不少美刀,你问球体长啥样,可以自行去YouTube上搜搜看。
一体化实时监测
前面提到,在2018年得时候CMU又扩充了Foot数据集,现在的OpenPose可以做到同时检测人脸、人体、人手、人脚。
OpenPose新版与旧版的不同
这里直接翻译原文的摘要,因为作者在摘要中已经写得很明晰了,告诉了我们它新加了什么东西。
原文摘要
首先,我们证明了PAF精化对于最大限度地提高准确率是至关重要的,而身体部位预测精化并不那么重要。我们增加了网络深度,但删除了身体部分的精化阶段(3.1节和3.2节)。这种精细化的网络将速度和准确率分别提高了约200%和7%(5.2节和5.3节)。其次,我们给出了一个带有15K个人类足部实例的带注释的足部数据集1,该数据集已公开出租(第4.2节),并且我们展示了包含躯干和脚部关键点的组合模型可以在保持仅人体模型的速度的同时保持其准确性(第5.5节)。第三,通过将该方法应用于车辆关键点估计任务(第5.6节),证明了该方法的普适性。最后,这项工作证明了OpenPose的发布[4]。这个开源的库是第一个可用于多人2D姿势检测的实时系统,包括身体、脚、手和面部关键点(第4节)。我们还包括与MaskR-CNN[5]和Alpha-Ppose[6]的运行时比较,显示了我们自下而上方法的计算优势(第5.3节)。
首先,作者他们通过实验证明PAF的refinement能最大限度的提升预测的准确率,而PCM的refinement并不那么重要,这也是网络结构变化的原因,具体可见原文TABLE5。所以最终网络结构是采用了5个PAF+PCM。(作者他们也进行了实验,不同stage的PAF和CM搭配进行测试。)
其次,增加了网络深度,通过用3个连续的3×3核来代替每个7×7卷积核,在保留感受野的同时减少了计算量,并且3个卷积核的输出是级联的,采用类似于DenseNet的结构。

最后,扩增了foot数据集,全新的组合模型(5 PAF - 1 CM)的推理速度以及准确性丝毫不差于单人体检测模型,原文TABLE4可见新的组合模型提升了6.9个点。
事实上,相比于MaskR-CNN、Alpha-Pose等方法,openpose的AP(COCO测试集的评价指标)是不如它们的,要论它的优势在哪的话,我想应该是他的推理速度要稍胜一筹,尤其当图像中的person超过20人时,openpose的推理速度要明显强过MaskR-CNN、Alpha-Pose等baseline的。


最后,怎么在自己的电脑部署OpenPose呢?或者说想自己试试OpenPose的效果,这里我放出B站上的一个学习视频以及一篇博客交你怎么在window上变异openpose,话不多说,上连接
B站视频:https://www.bilibili.com/video/BV14Z4y1V7fo?spm_id_from=333.999.header_right.history_list.click
博客教程:https://xugaoxiang.com/2021/05/29/build-openpose-for-windows-python-api/
参考资料:
https://www.jianshu.com/p/3aa810b35a5d
https://zhuanlan.zhihu.com/p/37526892
https://blog.csdn.net/cjnewstar111/article/details/115284760
https://blog.csdn.net/htt789/article/details/80283370
https://blog.csdn.net/weixin_38369492/article/details/104482481
再补充一个讲匈牙利算法的优秀博客:
https://blog.csdn.net/u013384984/article/details/90718287?spm=1001.2101.3001.6650.2&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-2.pc_relevant_aa&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-2.pc_relevant_aa&utm_relevant_index=4
写在最后,这是我第一次写博客,这篇博客只是记录一下自己学习openpose的过程,上面的不少内容是借鉴了别人优秀博客整理出来,知道自己写的太菜了,轻喷。