使用 PowerFlex 在 Kubernetes 平台上部署 Microsoft SQL Server 大数据集群
简介
Microsoft SQL Server 2019通过SQL Server 2019大数据集群 (Big Data Clusters, BDC)推出了突破性的数据平台。Microsoft SQL Server大数据集群旨在解决当今大多数组织面临的大数据挑战。您可以使用SQL Server BDC来组织和分析大量的数据,也可以将高价值的关系型数据与大数据结合起来。本文描述了使用Dell PowerFlex软件定义存储在Kubernetes平台上部署SQL Server BDC的过程。
PowerFlex
Dell PowerFlex是一个统一的、软件定义的计算存储和网络解决方案,提供横向扩展的块和文件存储服务,旨在提供灵活性、弹性和简单性以及大规模的可预测的高性能和恢复能力。
PowerFlex平台提供多种消费选项,可帮助客户满足其项目和数据中心需求。PowerFlex设备和PowerFlex机架为客户提供了针对整个基础架构堆栈的全面IT运营管理(ITOM)和生命周期管理(LCM),以及完善的高性能、可扩展、弹性的存储服务。
PowerFlex软件定义存储具有统一的计算和网络,可提供灵活的部署架构,以帮助最好地满足特定的部署和架构需求。PowerFlex可以部署在两层架构中,以实现计算和存储的非对称扩展,也可以部署在单层(HCI)或混合架构中。

最新的基于PowerEdge 15G的PowerFlex节点采用英特尔®至强®Platinum处理器,性能更高的CPU,更多的内存,带来极高的性能。
Microsoft SQL Server大数据集群概述
Microsoft SQL Server大数据集群 (Big Data Clusters, BDC) 旨在以独特的方式应对大数据挑战,BDC通过构建大数据和数据湖环境解决了许多传统挑战。SQL Server大数据集群是Microsoft SQL Server 2019的附加功能。您可以查询外部数据源,将大数据存储在由SQL Server管理的HDFS中,或者使用集群查询来自多个外部数据源的数据。
您可以使用SQL Server大数据集群,将SQL Server和Apache SparkTM、Hadoop分布式文件系统 (Hadoop Distributed File System, HDFS) 等可扩展的集群部署为容器,运行在Kubernetes上。
1
在PowerFlex上部署
Kubernetes平台
对于这个测试,PowerFlex 3.6.0采用两层配置构建,具有六个仅计算(CO)节点和八个仅存储(SO)节点。我们使用PowerFlex Manager自动配置 PowerFlex 集群,其中包含VMware vSphere 7.0 U2上的仅计算节点,以及使用Red Hat Enterprise Linux 8.2的仅存储节点。
下图显示了使用PowerFlex 的Kubernetes平台上SQL Server BDC的逻辑架构。
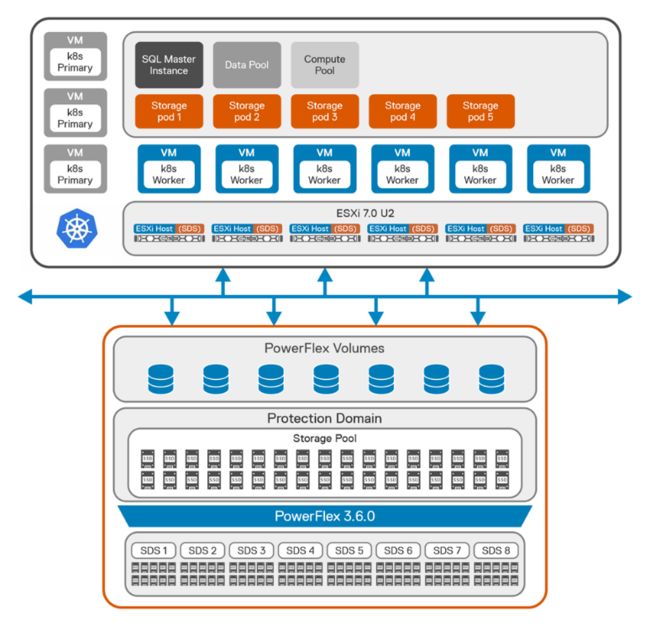
从存储角度来看,我们为SQL BDC从八个PowerFlex节点创建了一个保护域。然后,我们使用作为保护域成员的每个节点中安装的所有SSD创建了一个存储池。
部署PowerFlex集群后,我们在六个相同的仅计算节点上创建了十一个虚拟机,上面安装了Ubuntu 20.04。我在Kubernetes的工作节点上手动安装了PowerFlex的SDC组件。然后我们在虚拟机上配置了一个Kubernetes集群 (v1.20),其中有3个主节点和8个工作节点。
戴尔存储解决方案提供了CSI插件,使客户能够为基于容器的应用程序大规模提供持久存储。Kubernetes编排系统和Dell PowerFlex CSI插件的结合可以轻松配置容器和持久存储。
在该解决方案中,在我们安装Kubernetes集群后,配置了CSI 2.0来为SQL BDC工作负载提供持久卷。
2
在Kubernetes平台上部署
Microsoft SQL Server BDC
当具有CSI的Kubernetes集群准备就绪时,Azure data CLI将安装在客户端计算机上。
为了加速BDC的部署,我们建议使用本地专用注册表中的离线安装方法。虽然这意味着在创建和配置注册表时需要做一些额外的工作,但它消除了每个BDC主机从 Microsoft repository中提取容器映像的网络负载。在充当专用注册表的主机上,安装Docker并启用Docker repository。
BDC配置从默认设置修改为使用群集资源并满足工作负载要求。为了横向扩展BDC 资源池,需要调整副本数以使用集群的资源。
运行Spark 和Apache Hadoop YARN的配置值也根据每个节点可用的计算资源进行了调整。
为SQL master pod提供了20TB的存储空间,其中10TB作为日志空间。由于测试涉及运行TPC-DS工作负载,我们为五个storage pods配置了总共60TB的空间。
3
在PowerFlex上验证
SQL Server BDC
为了验证在PowerFlex上运行的大数据集群的配置并测试其可扩展性,我们使用Databricks®TPC-DS Spark SQL套件在集群上运行TPC-DS工作负载。该工具包允许您将整个TPC-DS工作负载作为Spark作业提交,该作业生成测试数据集并在其中运行一系列分析查询。由于此工作负载完全在SQL Server大数据集群的存储池内运行,因此环境被扩展为运行建议的最多五个storage pods。
我们为Kubernetes环境中的每个工作节点分配了一个storage pod,如下图所示。

在此解决方案中,采用Spark SQL TPC-DS工作负载来模拟数据库环境,该数据库环境对决策支持系统的多个适用方面进行建模,包括查询和数据维护。以高 CPU和I/O负载为特征,决策支持工作负载对SQL Server BDC集群配置施加负载,以在CPU、内存和I/O利用率方面获得最大的运营效率。标准结果由查询响应时间和查询吞吐量来衡量。
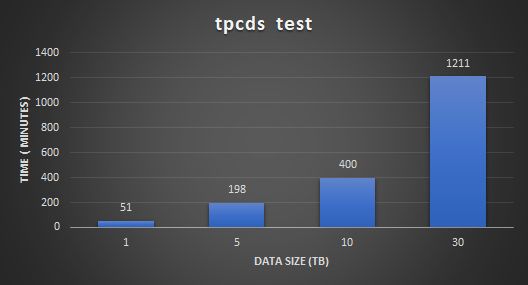
使用Databricks TPC-DS Spark SQL套件,工作负载作为Spark作业运行,分别对应1TB、5TB、10TB 和30TB工作负载。对于每个工作负载,仅更改数据集的大小。
我们在CURL命令中设置了具有不同比例因子的TPC-DS数据集。数据直接填充到 SQL Server大数据集群的HDFS存储池中。
下图显示了不同比例因子设置的数据生成所消耗的时间。数据生成时间还包括计算表统计信息的后期数据分析过程。

加载后,我们运行TPC-DS工作负载,以使用99个预定义的用户查询来验证Spark SQL的性能和可扩展性。查询以不同的用户模式为特征。
下图显示了性能和可扩展性测试结果。结果表明,在PowerFlex上运行Microsoft SQL Server大数据集群对不同的数据集具有线性可扩展性。这表明PowerFlex能够为不同类型的Spark SQL工作负载提供一致且可预测的性能。
下图显示了在30TB运行TPC-DS测试期间捕获的Grafana仪表板实例。从图中可以看出,在测试过程中实现了15GB/s的读取带宽。
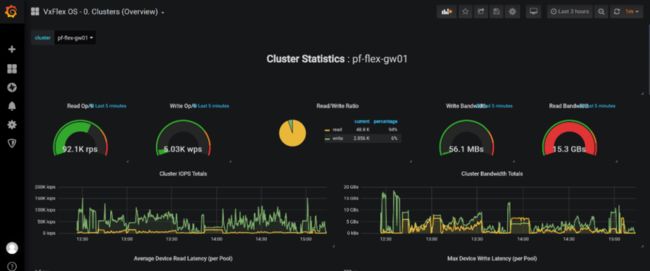
在这个最小的实验室硬件中,TPC-DS数据加载和查询执行没有存储瓶颈。工作节点上的CPU接近90%,表明更强大的节点可以提高性能。
总结
在PowerFlex上运行SQL Server大数据集群是开始在Kubernetes上运行现代化大数据工作负载的一种直接方式。该解决方案允许您使用现有IT基础架构和流程运行现代容器化工作负载。大数据集群允许大数据科学家利用Kubernetes的敏捷性进行创新和构建,而IT管理员则可以在他们熟悉的Sphere环境中管理安全的工作负载。
在此解决方案中,Microsoft SQL Server大数据集群部署在PowerFlex上,PowerFlex提供简化的云原生工作负载服务操作,并且可以在不妥协的情况下进行扩展。IT管理员可以为命名空间实施策略,并管理以应用程序为中心的管理访问和配额分配。以应用程序为中心的管理可帮助您使用企业级Kubernetes 构建开发人员就绪的基础架构,从而提供高级治理、可靠性和安全性。
Microsoft SQL Server大数据集群还与具有优化参数的Spark SQL TPC-DS工作负载一起使用。测试结果表明,部署在PowerFlex环境中的Microsoft SQL Server大数据集群除了数据仓库类型的操作外,还可以为大数据解决方案提供强大的分析平台。
点击阅读原文,了解更多PowerFlex内容
![]()
![]()
申耀的科技观察,由资深科技媒体人申斯基创办,19年企业级科技内容传播工作经验,长期专注产业互联网、企业数字化、ICT基础设施、汽车科技等内容的观察和思考。
