【深度学习基础】基于PyTorch实现Inception-v4, Inception-ResNet-v1, Inception-ResNet-v2亲身实践
【深度学习基础】基于PyTorch实现Inception-v4, Inception-ResNet-v1, Inception-ResNet-v2亲身实践
- 1 论文关键信息
-
- 1.1 Inception-v4网络整体架构
- 1.2 Inception-ResNet-v1,Inception-ResNet-v2网络整体结构
- 2 Inception-v4, Inception-ResNet-v1和Inception-ResNet-v2的pytorch实现
-
- 2.1 注意事项和讨论
- 2.2各种Inception blocks及其代码实现
-
- 2.2.1 Stem
- 2.2.2 Inception-A
- 2.2.3 Reduction-A
- 2.2.4 Inception-B
- 2.2.5 Reduction-B
- 2.2.6 Inception-C
- 2.3 Inception-v4, Inception-ResNet-v1, Inception-ResNet-v2实现
- 2.4 定义构建函数并测试网络
1 论文关键信息
这篇论文阅读起来相对于Inception-v3提出的论文友好很多,网络的架构以及每个模块的结构都在图中给出了,并且这些图看得很舒服,一目了然。
论文地址:Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
这篇论文的主要围绕几点展开:
1、提出一种新的网络结构——Inception-v4;
2、将残差结构融入Inception网络中,以提高训练效率,并提出了两种网络结构Inception-ResNet-v1和Inception-ResNet-v2
3、提出一种残差网络的优化方法:
当使用残差结构的网络很深时(比如滤波器的数量达到1000个),在训练一定次数后,残差变量就会表现出稳定性——也就是说,只有网络前面部分的会传递误差,后面部分之后产生0。
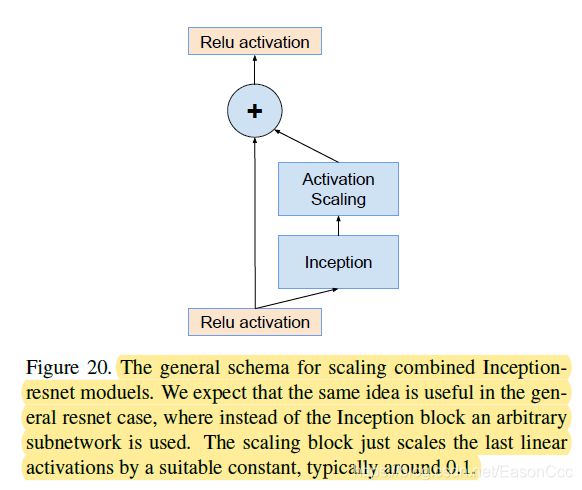
何凯明提出的思路是对残差网络进行两个阶段的训练:(1)先试用一个很小的学习率预热;(2)然后再用一个较高的学习率学习。但是作者发现当残差网络特别深时,哪怕使用一个特别小的学习率(0.00001)进行预热,
也难以避免这种梯度消失的现象。于是论文提出了一种对残差部分进行缩放的方式,一般采用0.1左右的缩放因子,如下图。这个缩放过程不是严格意义上的必须步骤。
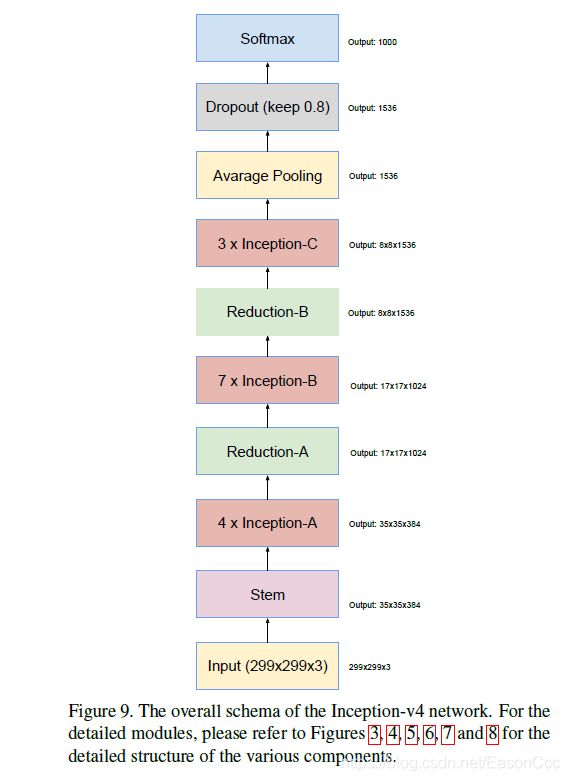
1.1 Inception-v4网络整体架构
考虑到配合代码看起来更加直观一些,网络中用到个各种Inception blocks将在博文的第二章介绍。
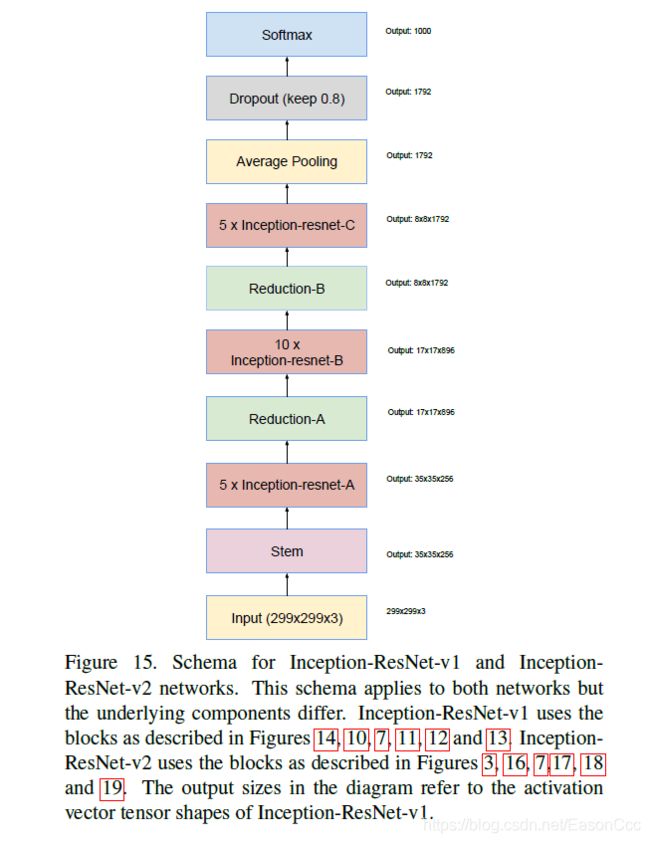
1.2 Inception-ResNet-v1,Inception-ResNet-v2网络整体结构
这里标示的滤波器数量是Inception-ResNet-v1的数量,v2需要自己根据结构来算。
2 Inception-v4, Inception-ResNet-v1和Inception-ResNet-v2的pytorch实现
2.1 注意事项和讨论
1、论文中提到,在Inception-ResNet结构中,Inception结构后面的1x1卷积后面不适用非线性激活单元。无怪乎我们可以再上面的图中看到,在Inception结构后面的1x1 Conv下面都标示Linear。
2、在Inception-ResNet结构中,BN层仅添加在传统的卷积层上面,而不添加在相加的结果上面。这么做不是出于精度的考虑,而是在Inception-ResNet的残差部分用了很多通道的1x1卷积,使得相加结果的维度很大,在这个部分不使用BN层可以节约很多GPU资源。
3、记得前面提到的"利用0.1左右的系数对残差部分进行缩放”吗? 在这里我想讨论一下这一点,在Inception后面的1x1卷积的作用我觉得就是起到两个作用:(1)对Inception结构的输出进行比例缩放,只不过这个缩放系数是学习得到的;(2)对特征进行升维度。我不清楚论文中说得缩放在Inception-ResNet结构中就意味着这个1x1卷积层。即使不是,这篇博文的复现在这里没有乘上这个缩放系数,因为我认为它已经学习了一个系数(并且论文中也提到这个缩放系数是非必须的)。
2.2各种Inception blocks及其代码实现
2.2.1 Stem
(1) Inception-v4和Inception-ResNet-v2使用
图中,最顶上一层3x3,左边的3x3卷积stride应该等于2,属于笔误。
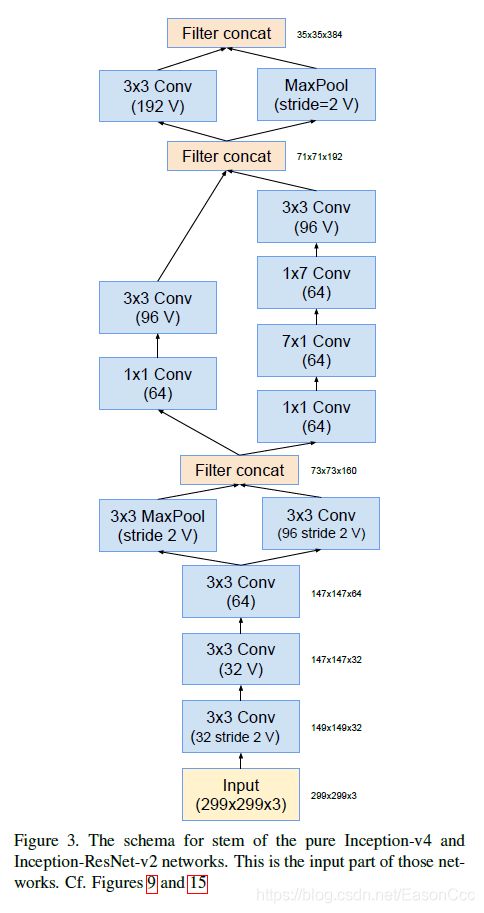
代码:
class Stem_v4_Res2(nn.Module):
"""
stem block for Inception-v4 and Inception-RestNet-v2
"""
def __init__(self):
super(Stem_v4_Res2, self).__init__()
self.step1 = nn.Sequential(
BN_Conv2d(3, 32, 3, 2, 0, bias=False),
BN_Conv2d(32, 32, 3, 1, 0, bias=False),
BN_Conv2d(32, 64, 3, 1, 1, bias=False)
)
self.step2_pool = nn.MaxPool2d(3, 2, 0)
self.step2_conv = BN_Conv2d(64, 96, 3, 2, 0, bias=False)
self.step3_1 = nn.Sequential(
BN_Conv2d(160, 64, 1, 1, 0, bias=False),
BN_Conv2d(64, 96, 3, 1, 0, bias=False)
)
self.step3_2 = nn.Sequential(
BN_Conv2d(160, 64, 1, 1, 0, bias=False),
BN_Conv2d(64, 64, (7, 1), (1, 1), (3, 0), bias=False),
BN_Conv2d(64, 64, (1, 7), (1, 1), (0, 3), bias=False),
BN_Conv2d(64, 96, 3, 1, 0, bias=False)
)
self.step4_pool = nn.MaxPool2d(3, 2, 0)
self.step4_conv = BN_Conv2d(192, 192, 3, 2, 0, bias=False)
def forward(self, x):
out = self.step1(x)
tmp1 = self.step2_pool(out)
tmp2 = self.step2_conv(out)
out = torch.cat((tmp1, tmp2), 1)
tmp1 = self.step3_1(out)
tmp2 = self.step3_2(out)
out = torch.cat((tmp1, tmp2), 1)
tmp1 = self.step4_pool(out)
tmp2 = self.step4_conv(out)
print(tmp1.shape)
print(tmp2.shape)
out = torch.cat((tmp1, tmp2), 1)
return out
(2) Inception-ResNet-v1使用

代码:
class Stem_Res1(nn.Module):
"""
stem block for Inception-ResNet-v1
"""
def __init__(self):
super(Stem_Res1, self).__init__()
self.stem = nn.Sequential(
BN_Conv2d(3, 32, 3, 2, 0, bias=False),
BN_Conv2d(32, 32, 3, 1, 0, bias=False),
BN_Conv2d(32, 64, 3, 1, 1, bias=False),
nn.MaxPool2d(3, 2, 0),
BN_Conv2d(64, 80, 1, 1, 0, bias=False),
BN_Conv2d(80, 192, 3, 1, 0, bias=False),
BN_Conv2d(192, 256, 3, 2, 0, bias=False)
)
def forward(self, x):
return self.stem(x)
2.2.2 Inception-A
说明:所有的inception block在实现的时候通过参数控制,方便以后自己使用时调整内部结构.
(1)Inception-v4使用
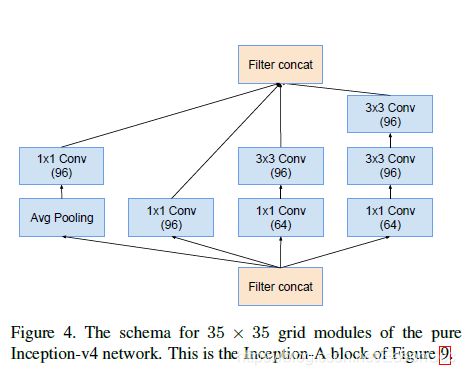
代码:
class Inception_A(nn.Module):
"""
Inception-A block for Inception-v4 net
"""
def __init__(self, in_channels, b1, b2, b3_n1, b3_n3, b4_n1, b4_n3):
super(Inception_A, self).__init__()
self.branch1 = nn.Sequential(
nn.AvgPool2d(3, 1, 1),
BN_Conv2d(in_channels, b1, 1, 1, 0, bias=False)
)
self.branch2 = BN_Conv2d(in_channels, b2, 1, 1, 0, bias=False)
self.branch3 = nn.Sequential(
BN_Conv2d(in_channels, b3_n1, 1, 1, 0, bias=False),
BN_Conv2d(b3_n1, b3_n3, 3, 1, 1, bias=False)
)
self.branch4 = nn.Sequential(
BN_Conv2d(in_channels, b4_n1, 1, 1, 0, bias=False),
BN_Conv2d(b4_n1, b4_n3, 3, 1, 1, bias=False),
BN_Conv2d(b4_n3, b4_n3, 3, 1, 1, bias=False)
)
def forward(self, x):
out1 = self.branch1(x)
out2 = self.branch2(x)
out3 = self.branch3(x)
out4 = self.branch4(x)
return torch.cat((out1, out2, out3, out4), 1)
(2)Inception-ResNet使用
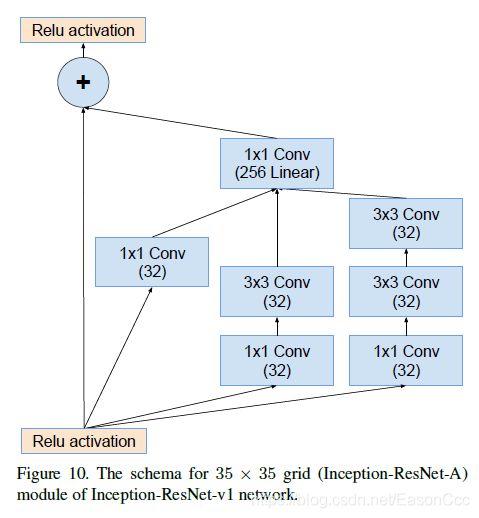
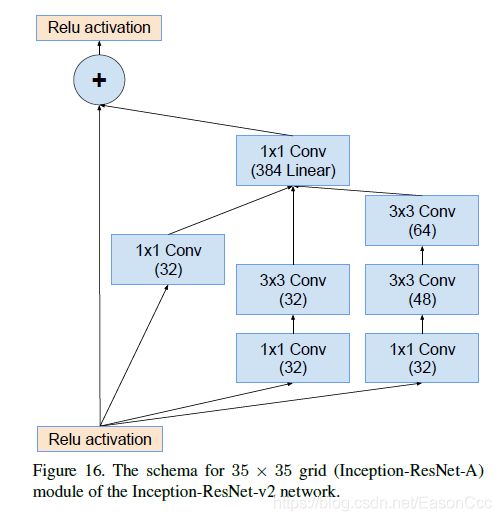
代码:
class Inception_A_res(nn.Module):
"""
Inception-A block for Inception-ResNet-v1\
and Inception-ResNet-v2 net
"""
def __init__(self, in_channels, b1, b2_n1, b2_n3, b3_n1, b3_n3_1, b3_n3_2, n1_linear):
super(Inception_A_res, self).__init__()
self.branch1 = BN_Conv2d(in_channels, b1, 1, 1, 0, bias=False)
self.branch2 = nn.Sequential(
BN_Conv2d(in_channels, b2_n1, 1, 1, 0, bias=False),
BN_Conv2d(b2_n1, b2_n3, 3, 1, 1, bias=False),
)
self.branch3 = nn.Sequential(
BN_Conv2d(in_channels, b3_n1, 1, 1, 0, bias=False),
BN_Conv2d(b3_n1, b3_n3_1, 3, 1, 1, bias=False),
BN_Conv2d(b3_n3_1, b3_n3_2, 3, 1, 1, bias=False)
)
self.conv_linear = nn.Conv2d(b1+b2_n3+b3_n3_2, n1_linear, 1, 1, 0, bias=True)
self.short_cut = nn.Sequential()
if in_channels != n1_linear:
self.short_cut = nn.Sequential(
nn.Conv2d(in_channels, n1_linear, 1, 1, 0, bias=False),
nn.BatchNorm2d(n1_linear)
)
def forward(self, x):
out1 = self.branch1(x)
out2 = self.branch2(x)
out3 = self.branch3(x)
out = torch.cat((out1, out2, out3), 1)
out = self.conv_linear(out)
out += self.short_cut(x)
return F.relu(out)
2.2.3 Reduction-A
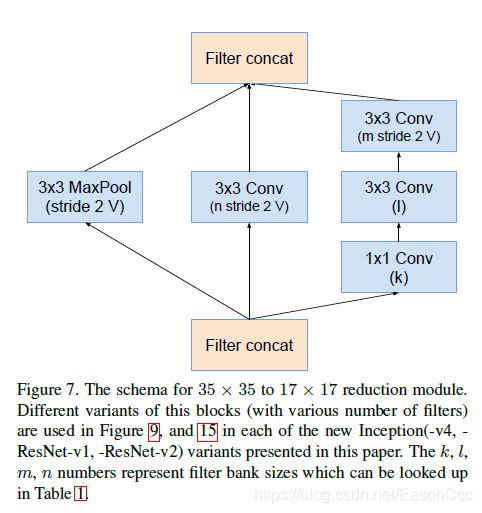
三种网络架构分别使用的滤波器数量,k,l,m,如下表:

代码:
class Reduction_A(nn.Module):
"""
Reduction-A block for Inception-v4, Inception-ResNet-v1, Inception-ResNet-v2 nets
"""
def __init__(self, in_channels, k, l, m, n):
super(Reduction_A, self).__init__()
self.branch2 = BN_Conv2d(in_channels, n, 3, 2, 0, bias=False)
self.branch3 = nn.Sequential(
BN_Conv2d(in_channels, k, 1, 1, 0, bias=False),
BN_Conv2d(k, l, 3, 1, 1, bias=False),
BN_Conv2d(l, m, 3, 2, 0, bias=False)
)
def forward(self, x):
out1 = F.max_pool2d(x, 3, 2, 0)
out2 = self.branch2(x)
out3 = self.branch3(x)
return torch.cat((out1, out2, out3), 1)
2.2.4 Inception-B
(1)Inception-v4使用
第三条支路,滤波核尺寸为什么不是1x7和7x1的组合? 比较纳闷,按照之前一篇论文fractional的观点,这里应该是有点不妥的,那么是以下原因之一:
(1)笔误?
(2)实验发现用两个横向的1x7效果更好?
虽然深度学习是门实验学科,但是我选择让它看起来更加和谐,将最后一个1x7改成7x1,如果介意大家可以改回和图中一样。
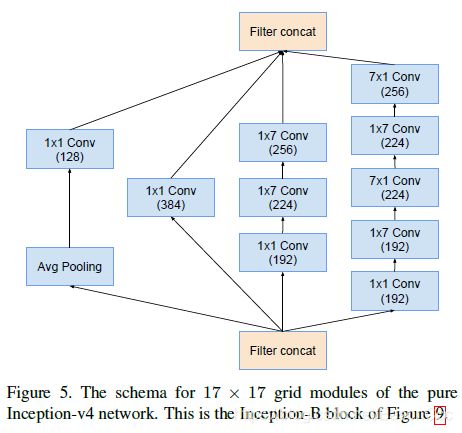
代码:
class Inception_B(nn.Module):
"""
Inception-B block for Inception-v4 net
"""
def __init__(self, in_channels, b1, b2, b3_n1, b3_n1x7, b3_n7x1, b4_n1, b4_n1x7_1,
b4_n7x1_1, b4_n1x7_2, b4_n7x1_2):
super(Inception_B, self).__init__()
self.branch1 = nn.Sequential(
nn.AvgPool2d(3, 1, 1),
BN_Conv2d(in_channels, b1, 1, 1, 0, bias=False)
)
self.branch2 = BN_Conv2d(in_channels, b2, 1, 1, 0, bias=False)
self.branch3 = nn.Sequential(
BN_Conv2d(in_channels, b3_n1, 1, 1, 0, bias=False),
BN_Conv2d(b3_n1, b3_n1x7, (1, 7), (1, 1), (0, 3), bias=False),
BN_Conv2d(b3_n1x7, b3_n7x1, (7, 1), (1, 1), (3, 0), bias=False)
)
self.branch4 = nn.Sequential(
BN_Conv2d(in_channels, b4_n1, 1, 1, 0, bias=False),
BN_Conv2d(b4_n1, b4_n1x7_1, (1, 7), (1, 1), (0, 3), bias=False),
BN_Conv2d(b4_n1x7_1, b4_n7x1_1, (7, 1), (1, 1), (3, 0), bias=False),
BN_Conv2d(b4_n7x1_1, b4_n1x7_2, (1, 7), (1, 1), (0, 3), bias=False),
BN_Conv2d(b4_n1x7_2, b4_n7x1_2, (7, 1), (1, 1), (3, 0), bias=False)
)
def forward(self, x):
out1 = self.branch1(x)
out2 = self.branch2(x)
out3 = self.branch3(x)
out4 = self.branch4(x)
return torch.cat((out1, out2, out3, out4), 1)
(2)Inception-ResNet使用
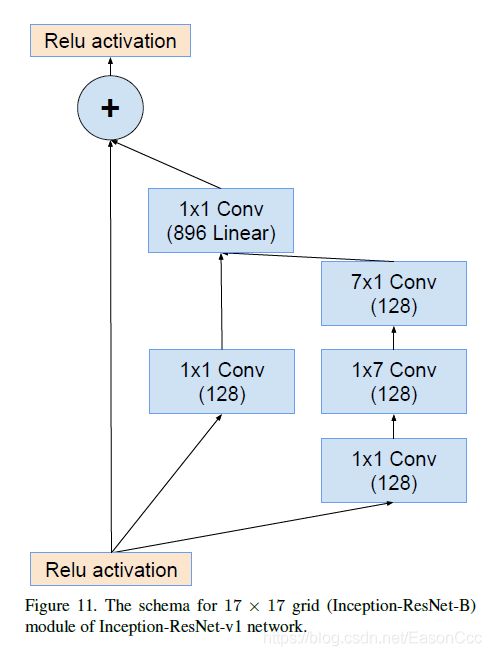
这里,我觉得下图中1x1 Conv linear的数量应该是1152,Reduction-A的输出是1152;这个block在v4和resnet-v1中输入输出都是一致的。当然也可能是作者调整了滤波器数量,我是按照1152的数量来复现的。
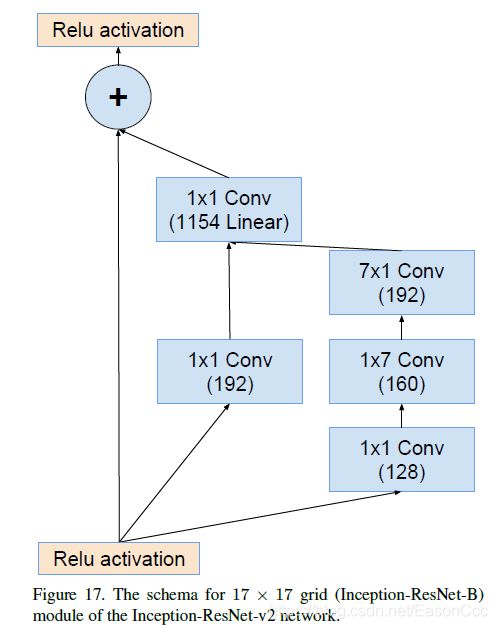
代码:
class Inception_B_res(nn.Module):
"""
Inception-A block for Inception-ResNet-v1\
and Inception-ResNet-v2 net
"""
def __init__(self, in_channels, b1, b2_n1, b2_n1x7, b2_n7x1, n1_linear):
super(Inception_B_res, self).__init__()
self.branch1 = BN_Conv2d(in_channels, b1, 1, 1, 0, bias=False)
self.branch2 = nn.Sequential(
BN_Conv2d(in_channels, b2_n1, 1, 1, 0, bias=False),
BN_Conv2d(b2_n1, b2_n1x7, (1, 7), (1, 1), (0, 3), bias=False),
BN_Conv2d(b2_n1x7, b2_n7x1, (7, 1), (1, 1), (3, 0), bias=False)
)
self.conv_linear = nn.Conv2d(b1 + b2_n7x1, n1_linear, 1, 1, 0, bias=False)
self.short_cut = nn.Sequential()
if in_channels != n1_linear:
self.short_cut = nn.Sequential(
nn.Conv2d(in_channels, n1_linear, 1, 1, 0, bias=False),
nn.BatchNorm2d(n1_linear)
)
def forward(self, x):
out1 = self.branch1(x)
out2 = self.branch2(x)
out = torch.cat((out1, out2), 1)
out = self.conv_linear(out)
out += self.short_cut(x)
return F.relu(out)
2.2.5 Reduction-B
(1) Inception-v4使用
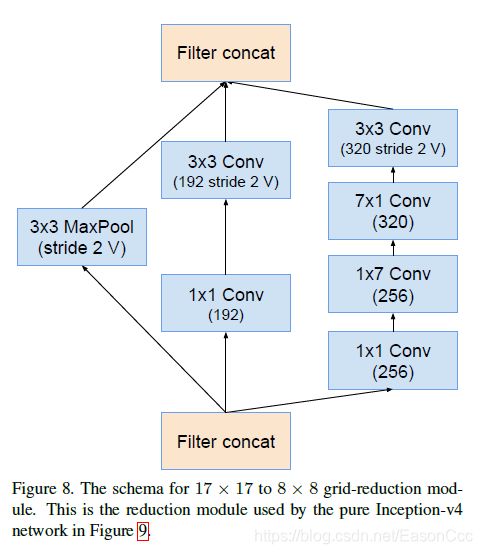
代码:
class Reduction_B_v4(nn.Module):
"""
Reduction-B block for Inception-v4 net
"""
def __init__(self, in_channels, b2_n1, b2_n3, b3_n1, b3_n1x7, b3_n7x1, b3_n3):
super(Reduction_B_v4, self).__init__()
self.branch2 = nn.Sequential(
BN_Conv2d(in_channels, b2_n1, 1, 1, 0, bias=False),
BN_Conv2d(b2_n1, b2_n3, 3, 2, 0, bias=False)
)
self.branch3 = nn.Sequential(
BN_Conv2d(in_channels, b3_n1, 1, 1, 0, bias=False),
BN_Conv2d(b3_n1, b3_n1x7, (1, 7), (1, 1), (0, 3), bias=False),
BN_Conv2d(b3_n1x7, b3_n7x1, (7, 1), (1, 1), (3, 0), bias=False),
BN_Conv2d(b3_n7x1, b3_n3, 3, 2, 0, bias=False)
)
def forward(self, x):
out1 = F.max_pool2d(x, 3, 2, 0)
out2 = self.branch2(x)
out3 = self.branch3(x)
return torch.cat((out1, out2, out3), 1)
(2) Inception-ResNet使用
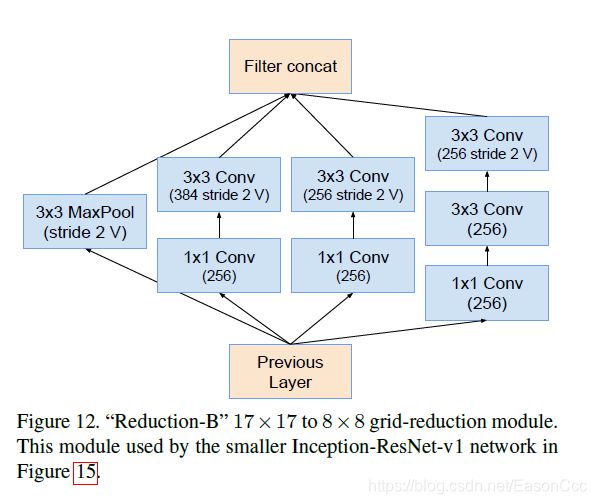
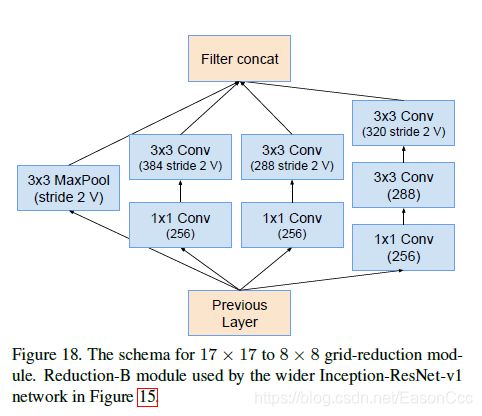
代码:
class Reduction_B_Res(nn.Module):
"""
Reduction-B block for Inception-ResNet-v1 \
and Inception-ResNet-v2 net
"""
def __init__(self, in_channels, b2_n1, b2_n3, b3_n1, b3_n3, b4_n1, b4_n3_1, b4_n3_2):
super(Reduction_B_Res, self).__init__()
self.branch2 = nn.Sequential(
BN_Conv2d(in_channels, b2_n1, 1, 1, 0, bias=False),
BN_Conv2d(b2_n1, b2_n3, 3, 2, 0, bias=False),
)
self.branch3 = nn.Sequential(
BN_Conv2d(in_channels, b3_n1, 1, 1, 0, bias=False),
BN_Conv2d(b3_n1, b3_n3, 3, 2, 0, bias=False)
)
self.branch4 = nn.Sequential(
BN_Conv2d(in_channels, b4_n1, 1, 1, 0, bias=False),
BN_Conv2d(b4_n1, b4_n3_1, 3, 1, 1, bias=False),
BN_Conv2d(b4_n3_1, b4_n3_2, 3, 2, 0, bias=False)
)
def forward(self, x):
out1 = F.max_pool2d(x, 3, 2, 0)
out2 = self.branch2(x)
out3 = self.branch3(x)
out4 = self.branch4(x)
return torch.cat((out1, out2, out3, out4), 1)
2.2.6 Inception-C
(1)Inception-v4使用
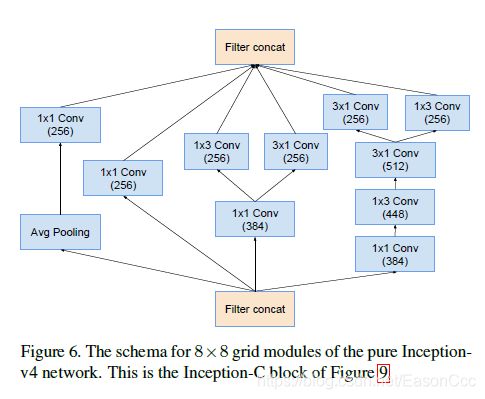
代码:
class Inception_C(nn.Module):
"""
Inception-C block for Inception-v4 net
"""
def __init__(self, in_channels, b1, b2, b3_n1, b3_n1x3_3x1, b4_n1,
b4_n1x3, b4_n3x1, b4_n1x3_3x1):
super(Inception_C, self).__init__()
self.branch1 = nn.Sequential(
nn.AvgPool2d(3, 1, 1),
BN_Conv2d(in_channels, b1, 1, 1, 0, bias=False)
)
self.branch2 = BN_Conv2d(in_channels, b2, 1, 1, 0, bias=False)
self.branch3_1 = BN_Conv2d(in_channels, b3_n1, 1, 1, 0, bias=False)
self.branch3_1x3 = BN_Conv2d(b3_n1, b3_n1x3_3x1, (1, 3), (1, 1), (0, 1), bias=False)
self.branch3_3x1 = BN_Conv2d(b3_n1, b3_n1x3_3x1, (3, 1), (1, 1), (1, 0), bias=False)
self.branch4_1 = nn.Sequential(
BN_Conv2d(in_channels, b4_n1, 1, 1, 0, bias=False),
BN_Conv2d(b4_n1, b4_n1x3, (1, 3), (1, 1), (0, 1), bias=False),
BN_Conv2d(b4_n1x3, b4_n3x1, (3, 1), (1, 1), (1, 0), bias=False)
)
self.branch4_1x3 = BN_Conv2d(b4_n3x1, b4_n1x3_3x1, (1, 3), (1, 1), (0, 1), bias=False)
self.branch4_3x1 = BN_Conv2d(b4_n3x1, b4_n1x3_3x1, (3, 1), (1, 1), (1, 0), bias=False)
def forward(self, x):
out1 = self.branch1(x)
out2 = self.branch2(x)
tmp = self.branch3_1(x)
out3_1 = self.branch3_1x3(tmp)
out3_2 = self.branch3_3x1(tmp)
tmp = self.branch4_1(x)
out4_1 = self.branch4_1x3(tmp)
out4_2 = self.branch4_3x1(tmp)
return torch.cat((out1, out2, out3_1, out3_2, out4_1, out4_2), 1)
(2)Inception-ResNet使用
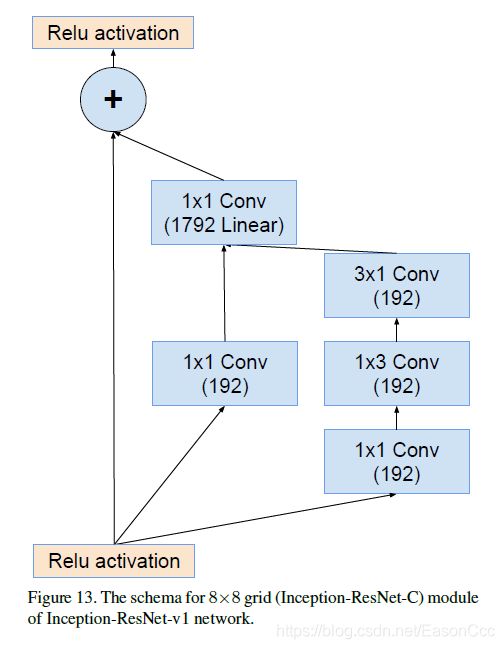
下图中,这里1x1 Conv Linear我按照2144来复现的,和输入数量相同。
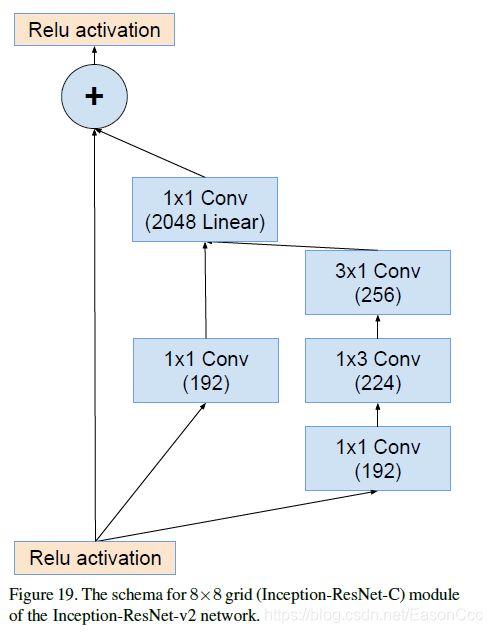
代码:
class Inception_C_res(nn.Module):
"""
Inception-C block for Inception-ResNet-v1\
and Inception-ResNet-v2 net
"""
def __init__(self, in_channels, b1, b2_n1, b2_n1x3, b2_n3x1, n1_linear):
super(Inception_C_res, self).__init__()
self.branch1 = BN_Conv2d(in_channels, b1, 1, 1, 0, bias=False)
self.branch2 = nn.Sequential(
BN_Conv2d(in_channels, b2_n1, 1, 1, 0, bias=False),
BN_Conv2d(b2_n1, b2_n1x3, (1, 3), (1, 1), (0, 1), bias=False),
BN_Conv2d(b2_n1x3, b2_n3x1, (3, 1), (1, 1), (1, 0), bias=False)
)
self.conv_linear = nn.Conv2d(b1 + b2_n3x1, n1_linear, 1, 1, 0, bias=False)
self.short_cut = nn.Sequential()
if in_channels != n1_linear:
self.short_cut = nn.Sequential(
nn.Conv2d(in_channels, n1_linear, 1, 1, 0, bias=False),
nn.BatchNorm2d(n1_linear)
)
def forward(self, x):
out1 = self.branch1(x)
out2 = self.branch2(x)
out = torch.cat((out1, out2), 1)
out = self.conv_linear(out)
out += self.short_cut(x)
return F.relu(out)
2.3 Inception-v4, Inception-ResNet-v1, Inception-ResNet-v2实现
代码:
class Inception(nn.Module):
"""
implementation of Inception-v4, Inception-ResNet-v1, Inception-ResNet-v2
"""
def __init__(self, version, num_classes):
super(Inception, self).__init__()
self.version = version
self.stem = Stem_Res1() if self.version == "res1" else Stem_v4_Res2()
self.inception_A = self.__make_inception_A()
self.Reduction_A = self.__make_reduction_A()
self.inception_B = self.__make_inception_B()
self.Reduction_B = self.__make_reduction_B()
self.inception_C = self.__make_inception_C()
if self.version == "v4":
self.fc = nn.Linear(1536, num_classes)
elif self.version == "res1":
self.fc = nn.Linear(1792, num_classes)
else:
self.fc = nn.Linear(2144, num_classes)
def __make_inception_A(self):
layers = []
if self.version == "v4":
for _ in range(4):
layers.append(Inception_A(384, 96, 96, 64, 96, 64, 96))
elif self.version == "res1":
for _ in range(5):
layers.append(Inception_A_res(256, 32, 32, 32, 32, 32, 32, 256))
else:
for _ in range(5):
layers.append(Inception_A_res(384, 32, 32, 32, 32, 48, 64, 384))
return nn.Sequential(*layers)
def __make_reduction_A(self):
if self.version == "v4":
return Reduction_A(384, 192, 224, 256, 384) # 1024
elif self.version == "res1":
return Reduction_A(256, 192, 192, 256, 384) # 896
else:
return Reduction_A(384, 256, 256, 384, 384) # 1152
def __make_inception_B(self):
layers = []
if self.version == "v4":
for _ in range(7):
layers.append(Inception_B(1024, 128, 384, 192, 224, 256,
192, 192, 224, 224, 256)) # 1024
elif self.version == "res1":
for _ in range(10):
layers.append(Inception_B_res(896, 128, 128, 128, 128, 896)) # 896
else:
for _ in range(10):
layers.append(Inception_B_res(1152, 192, 128, 160, 192, 1152)) # 1152
return nn.Sequential(*layers)
def __make_reduction_B(self):
if self.version == "v4":
return Reduction_B_v4(1024, 192, 192, 256, 256, 320, 320) # 1536
elif self.version == "res1":
return Reduction_B_Res(896, 256, 384, 256, 256, 256, 256, 256) # 1792
else:
return Reduction_B_Res(1152, 256, 384, 256, 288, 256, 288, 320) # 2144
def __make_inception_C(self):
layers = []
if self.version == "v4":
for _ in range(3):
layers.append(Inception_C(1536, 256, 256, 384, 256, 384, 448, 512, 256))
elif self.version == "res1":
for _ in range(5):
layers.append(Inception_C_res(1792, 192, 192, 192, 192, 1792))
else:
for _ in range(5):
layers.append(Inception_C_res(2144, 192, 192, 224, 256, 2144))
return nn.Sequential(*layers)
def forward(self, x):
out = self.stem(x)
out = self.inception_A(out)
out = self.Reduction_A(out)
out = self.inception_B(out)
out = self.Reduction_B(out)
out = self.inception_C(out)
out = F.avg_pool2d(out, 8)
out = F.dropout(out, 0.2, training=self.training)
out = out.view(out.size(0), -1)
print(out.shape)
out = self.fc(out)
return F.softmax(out)
2.4 定义构建函数并测试网络
代码:
def inception_v4(classes=1000):
return Inception("v4", classes)
def inception_resnet_v1(classes=1000):
return Inception("res1", classes)
def inception_resnet_v2(classes=1000):
return Inception("res2", classes)
def test():
net = inception_v4()
# net = inception_resnet_v1()
# net = inception_resnet_v2()
summary(net, (3, 299, 299))
test()
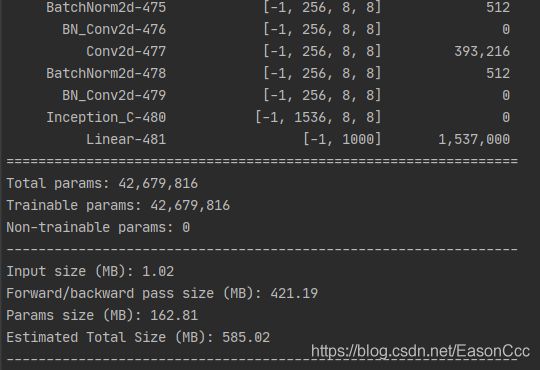
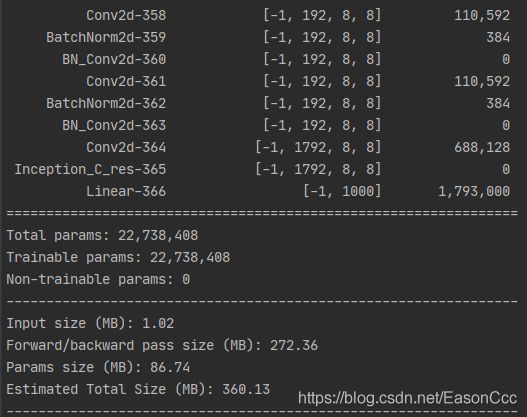
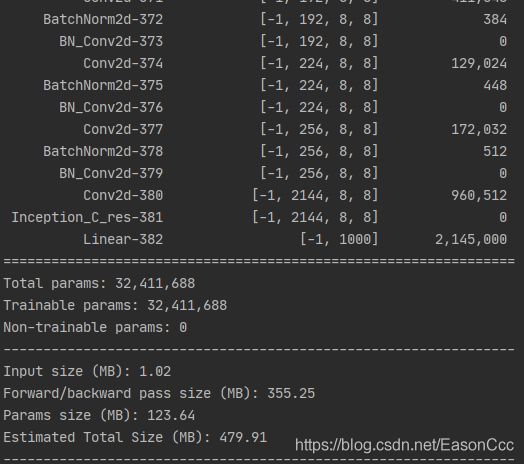
测试结果: