线上频繁发生Full GC 如何调优?如何快速定位OOM、cpu飙升、线程死锁等问题
文章目录
-
- 1. jvm调优命令、工具介绍
-
- ①:jps
- ②:jmap
-
- 查看应用中各实例生成情况
- 快速定位内存突然飙升导致的OOM异常
- 查看堆内存使用情况
- ③:Jstack
-
- 检测线程死锁
- 快速定位导致cpu飙升的线程堆栈信息
- ④:jvisualvm
- ⑤:jinfo
- ⑥:jstat
- 4. 线上频繁发生Full GC 如何调优?
-
- 1. 使用jstate进行GC样本采集
- 2. 结合JVM参数,分析堆内存对象流转模型
- 3. 根据老年代发生GC的规则进行调优
- 5. 内存泄漏和内存溢出
1. jvm调优命令、工具介绍
以下这些调优命令都是jdk包下自带的命令,在调优时可以直接使用!
①:jps
使用jps可以查看已启动的应用进程id,后续可以选择对应的进程 id 进行jvm调优。
②:jmap
查看应用中各实例生成情况
打开log.txt,文件内容如下:
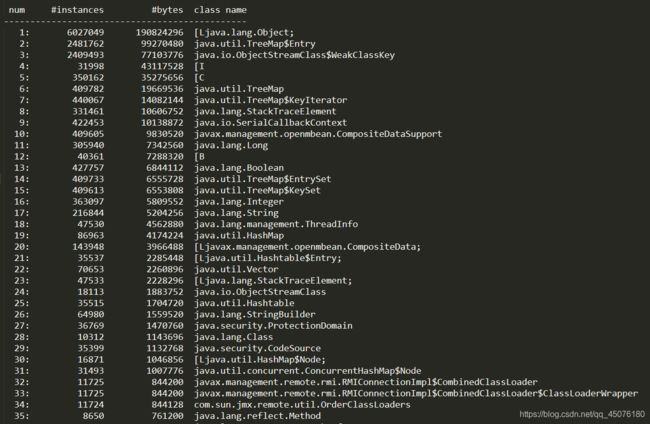
log.txt中各列名释义如下:
num:序号instances:实例数量bytes:占用空间大小class name:类名称,其中:[C is a char[],[S is a short[],[I is a int[],[B is a byte[],[[I is a int[][]
快速定位内存突然飙升导致的OOM异常
使用jmap -dump:format=b,file=eureka.hprof 14660可以导出这一时刻的堆快照信息(.hprof和.dump都是当前堆内存中的快照信息!)

也可以在jvm参数中设置内存溢出(OOM)时自动导出dump文件,保护事故现场(内存很大的时候,可能会导不出来),参数设置如下:
-XX:+HeapDumpOnOutOfMemoryError-XX:HeapDumpPath=./ (路径)
调小堆内存,模拟OOM异常:
public class OOMTest {
public static List<Object> list = new ArrayList<>();
// JVM设置 :可在堆内存溢出时,及时导出dump文件
// -Xms10M -Xmx10M -XX:+PrintGCDetails -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=D:\jvm.dump
public static void main(String[] args) {
List<Object> list = new ArrayList<>();
int i = 0;
int j = 0;
while (true) {
list.add(new User(i++, UUID.randomUUID().toString()));
new User(j--, UUID.randomUUID().toString());
}
}
}
上述代码由于堆内存只有10M,所以很快会发生oom,然后会根据配置的JVM参数自动导出dump文件。导出的这个jvm.dump 快照信息可以放在jvisualvm中进行解析,解析效果与jmap类似,但在jvisualvm中观看更加直观!
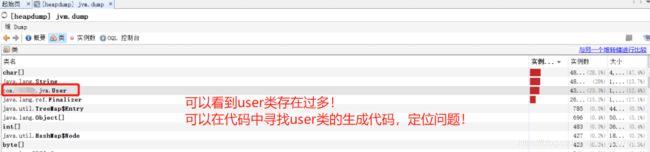
可以看到user类的实例数明显不正常,可根据代码中user的生成快速定位问题!
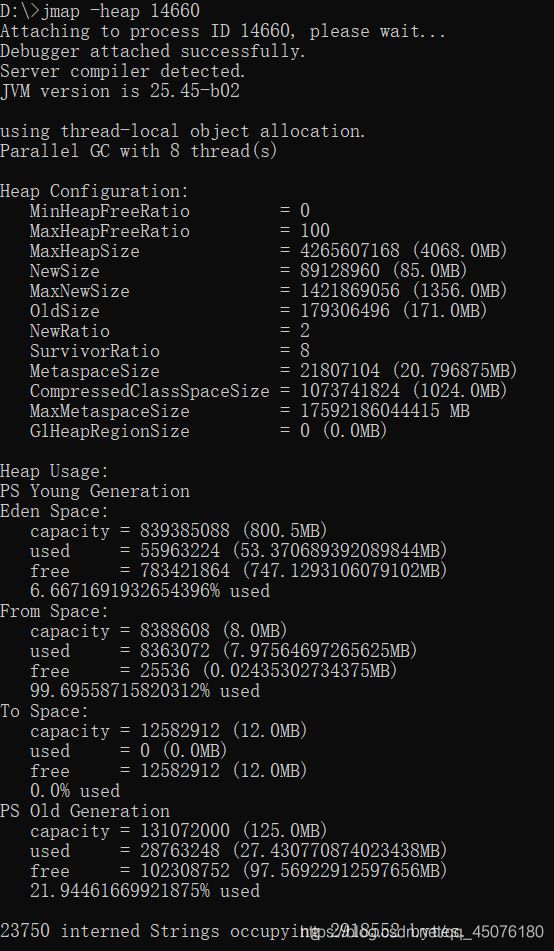
查看堆内存使用情况
查看命令:jmap -heap 14660
③:Jstack
检测线程死锁
线程死锁代码如下
public class DeadLockTest {
private static Object lock1 = new Object();
private static Object lock2 = new Object();
public static void main(String[] args) {
//线程1:占有lock1,想要获取lock2
new Thread(() -> {
synchronized (lock1) {
try {
System.out.println("thread1 begin");
Thread.sleep(5000);
} catch (InterruptedException e) {
}
synchronized (lock2) {
System.out.println("thread1 end");
}
}
}).start();
//线程2:占有lock2,想要获取lock1
new Thread(() -> {
synchronized (lock2) {
try {
System.out.println("thread2 begin");
Thread.sleep(5000);
} catch (InterruptedException e) {
}
synchronized (lock1) {
System.out.println("thread2 end");
}
}
}).start();
System.out.println("main thread end");
}
}
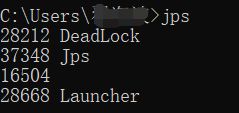
上述代码发生死锁后,先使用jps找到死锁进程id :28212
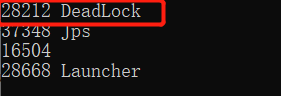
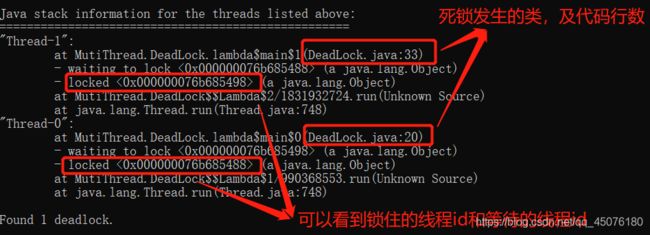
然后执行jstack命令:jstack 28212:执行完毕会发现 Thread1 和Thread0 是阻塞状态

其中上图中各参数释义如下:
"Thread-1"线程名prio=5优先级=5tid=0x000000001fa9e000线程idnid=0x2d64线程对应的本地线程标识nidjava.lang.Thread.State: BLOCKED线程状态
那么使用jstack命令已经知道了线程发生了死锁,那么死锁具体在java代码中的哪个类,哪一行代码上呢?在cmd窗口的最底部可以看到:
这个死锁也可以使用jvisualvm来轻松的自动检测死锁:当程序发生死锁后,打开jvisualvm,进入应用,点击线程可以看到检测到死锁标志,并在dump中可以查看死锁信息:

同样的还有MAT等工具也可以做到快速定位MAT的使用
快速定位导致cpu飙升的线程堆栈信息
cpu占用过高无非是cpu密集型的操作过多,正常操作时基本很少出现cpu占用过高的情况。但如果我们的代码有bug,比如在生产中,有一个线程发生了死循环,应用被严重拖慢,此时就需要快速定位cpu过高的原因并排除,下面模拟一个死循环导致cpu占用过高的情况!
public class Math {
public static final int initData = 666;
public static User user = new User();
public int compute() { //一个方法对应一块栈帧内存区域
int a = 1;
int b = 2;
int c = (a + b) * 10;
return c;
}
public static void main(String[] args) {
Math math = new Math();
//死循环执行方法,cpu占用率必会飙升
while (true){
math.compute(); //位于idea的第22行
}
}
}
当然还有一种就是多核CPU开很多线程去跑任务也会导致cpu满载,比如
Executors.newCachedThreadPool():core是0,最大线程数无限大,无限创建线程的话,会导致cpu占用100%,因为cpu要不停的调度线程去执行任务

Executors.newFixedThreadPool(10):固定大小 core = 自定义的线程数,但阻塞队列是LinkedBlockQueue无界队列,对任务来者不拒,会导致OOM内存溢出

在服务器上运行上述代码就会导致服务器cpu飙升,接下来进行快速定位!
-
在服务器上使用
top指令,显示所有进程的cpu占用情况,找到占用最高的,明显不正常的进程id

-
使用命令
top -p < pid >指令,精确的定位到占用cpu过高的进程id(21919),pid是你的java进程号,比如21919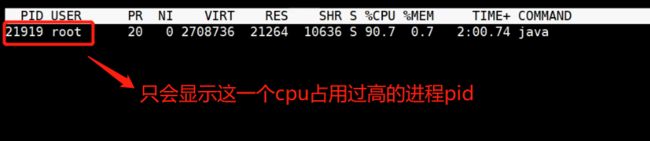
-
然后按
H,显示这个21919进程中所有的线程
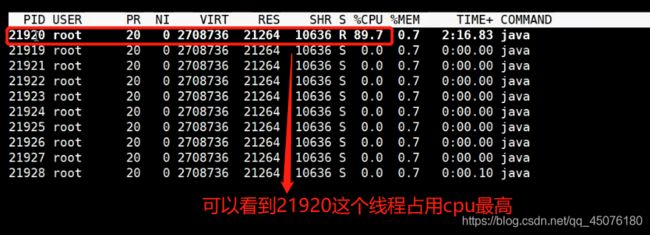
-
把
21920这个线程转换为十六进制为55a0,注意把十六进制的大写字母转换为小写 -
因为
jstack可以定位到代码位置,所以执行jstack 21919|grep -A 10 55a0,得到21919进程中的线程堆栈信息中55a0这个线程所在行的后面10行,从堆栈中可以发现导致cpu飙高的调用方法

-
找到了导致cpu飙高的代码位置,接下来就去该位置排查问题即可!
④:jvisualvm
jvisualvm是jdk提供的一个可视化界面,可以看做是对jmap、jstack、jinfo等命令的一个可视化实现,使用jvisualvm可以更加直观的查看堆内存信息、检测死锁,GC等情况!
这里介绍以下jvisualvm如何连接远程服务器的项目(一般生产上不会这么用,生产中为了安全起见,不会开放ivisualvm的连接端口,这里只做拓展)
远程服务器的项目如果是springboot项目的话,使用java -jar启动时需要添加以下配置:
java -Dcom.sun.management.jmxremote.port=8888 -Djava.rmi.server.hostname=192.168.65.60 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false -jar microservice-eureka-server.jar
上述配置中:
- -Dcom.sun.management.jmxremote.port 为远程机器的JMX端口
- -Djava.rmi.server.hostname 为远程机器IP
然后使用jvisualvm的远程连接选项,即可连接:
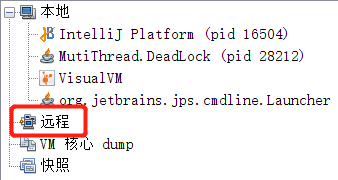
⑤:jinfo
jinfo最主要作用是:查看正在运行的Java应用程序的扩展参数
- 查看
jvm启动时配置的参数

- 查看
java系统参数
当然这些参数的查看也可以在jvisualvm中查看,因为jvisualvm可以看做是对这些普通参数的整合

⑥:jstat
jstat可以动态的查看堆内存各部分(Eden、s0、s1、老年代、元空间)的使用情况
命令格式如下:jstat [-命令选项] [进程id] [间隔时间(毫秒)] [查询次数]
如:jstat -gc 21968 1000 10 代表的是:查看21968进程的gc情况,每隔一秒打印一次,一共打印10次!
注意:jstat打印的GC使用情况是自项目启动时开始计算的!!!
其中jstat的【-命令选项】有以下几种:
垃圾回收统计
jstat -gc pid
jstat的这种用法最多,可以评估程序内存使用及GC压力整体情况
![]()
上图的参数释义如下
- S0C:第一个幸存区的大小,单位KB
- S1C:第二个幸存区的大小
- S0U:第一个幸存区的已使用大小
- S1U:第二个幸存区的已使用大小
- EC:伊甸园区的大小
- EU:伊甸园区的已使用大小
- OC:老年代大小
- OU:老年代已使用大小
- MC:方法区大小(元空间)
- MU:方法区使用大小
- CCSC:压缩类空间大小
- CCSU:压缩类空间已使用大小
- YGC:年轻代垃圾回收次数
- YGCT:年轻代垃圾回收消耗时间,单位s
- FGC:老年代垃圾回收次数
- FGCT:老年代垃圾回收消耗时间,单位s
- GCT:垃圾回收消耗总时间,单位s
堆内存统计
jstat -gccapacity pid
![]()
- NGCMN:新生代最小容量
- NGCMX:新生代最大容量
- NGC:当前新生代容量
- S0C:第一个幸存区大小
- S1C:第二个幸存区的大小
- EC:伊甸园区的大小
- OGCMN:老年代最小容量
- OGCMX:老年代最大容量
- OGC:当前老年代大小
- OC:当前老年代大小
- MCMN:最小元数据容量
- MCMX:最大元数据容量
- MC:当前元数据空间大小
- CCSMN:最小压缩类空间大小
- CCSMX:最大压缩类空间大小
- CCSC:当前压缩类空间大小
- YGC:年轻代gc次数
- FGC:老年代GC次数
新生代垃圾回收统计
jstat -gcnew pid

新生代内存统计
jstat -gcnewcapacity pid
老年代垃圾回收统计
jstat -gcold pid

老年代内存统计
jstat -gcoldcapacity pid

元数据空间统计
jstat -gcmetacapacity pid

4. 线上频繁发生Full GC 如何调优?
如果已上线的系统中频繁发生Full GC 导致系统卡顿,那么我们应该如何分析、定位、解决系统卡顿问题呢?主要分为以下几步!
GC样本采集- 结合
GC样本和JVM参数配置,分析堆内存中的对象流转情况 - 结合对象挪动到老年代那些规则,验证并调优
1. 使用jstate进行GC样本采集
如果是因为Full GC导致的系统卡顿,我们首先要对GC情况进行一些数据采集,可以有效帮助我们分析对象在JVM中的流转情况。可以使用 jstat gc -pid 2000 10000命令,每两秒实时打印一次GC情况,如下所示:
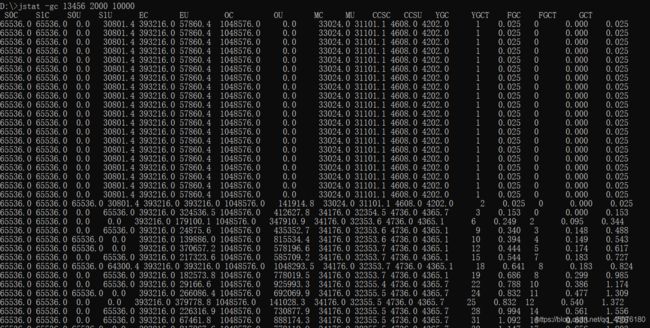
由于jstate打印的GC使用情况是从项目启动时开始计算的,所以根据以上数据可以预估自启动到现在为止,期间发生的Full GC次数和耗时,完成GC样本的采集!
采集数据如下:(举个例子)
- 系统运行时间:7天
- 期间发生的Full GC次数和耗时:500多次,200多秒
- 期间发生的Young GC次数和耗时:1万多次,500多秒
根据GC样本,大致算下来:
- 每天会发生70多次
Full GC,平均每小时3次,每次Full GC在400毫秒左右; - 每天会发生1000多次
Young GC,每分钟会发生1次,每次Young GC在50毫秒左右。
2. 结合JVM参数,分析堆内存对象流转模型
有了GC样本,还需要结合jvm参数配置,才能准确判断堆内存的对象流转情况!
JVM参数设置如下:
-Xms1536M -Xmx1536M -Xmn512M -Xss256K -XX:SurvivorRatio=6 -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M
-XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly
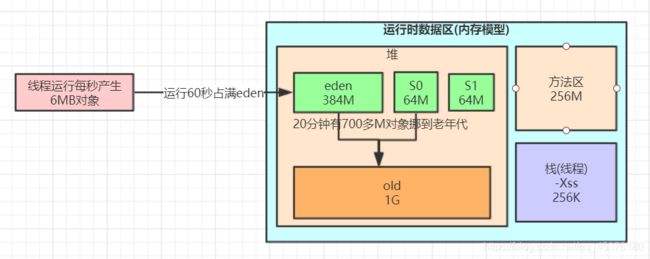
集合GC样本和jvm参数得出:
- 每60秒对象占满Eden区,Eden内存大小为384M
- 每20分钟有700多兆进入老年代
总结出一个JVM对象的流转模型:
3. 根据老年代发生GC的规则进行调优
哪些情况下老年代可能频繁发生Full GC 点击查看哪些对象会进入老年代!
- 频繁产生大对象直接进入老年代
- 动态年龄判断机制
- 老年代空间担保机制
因为我们也无法一眼看出问题出在哪,只能缩小问题范围进行排除。根据上边这些情况,尝试调整堆中年轻代和老年代的内存分配,并结合jatate命令查看gc样本,逐个验证或者排除某个情况,最终找出问题所在。
注意:
- 默认的老年代空间担保机制,可能使
Full GC次数是Young GC次数的两倍。因为老年代空间担保机制使得Young GC时先判断老年代空间是否足够,如果不够,先进行一次Full GC。然后再进行Young GC,很有可能Young GC后,对象被挪入老年代又触发了-XX:CMSInitiatingOccupancyFraction=75配置的老年代Full GC比例,再次触发Full GC,造成非常频繁的Full GC,甚至是Young GC的两倍! - 大对象进入老年代可能是一批对象进入进入老年代,可以使用
Jmap或者jvisualvm查看对象的实例个数,如果发现某个对象(例如:User对象)个数异常,问题很有可能就在这个对象上。 - 代码里全文搜索生成对象的地方(适合只有少数几处地方的情况),去排查异常。但如果生成
User对象的地方太多,无法定位具体代码,我们可以使用jstack或jvisualvm同时分析下占用cpu较高的线程,一般有大量对象不断产生,对应的方法代码肯定会被频繁调用,占用的cpu必然较高,由于jstack可以定位cpu占用较高的代码位置,所以到该位置查看一下代码是否有问题!
以上就是一些解决频繁Full GC的一些思路,但具体问题还是要具体分析,以上思路仅供参考!
5. 内存泄漏和内存溢出
内存泄露(无法释放已申请的内存) 本意是申请的内存空间没有被正确释放,导致后续程序里这块内存被永远占用(不可达),而且指向这块内存空间的指针不再存在时,这块内存也就永远不可达了,内存空间就这么一点点被蚕食,借用别人的比喻就是:比如有10张纸,本来一人一张,画完自己擦了还回去,别人可以继续画,现在有个坏蛋要了纸不擦不还,然后还跑了找不到人了,如此就只剩下9张纸给别人用了,这样的人多起来后,最后大家一张纸都没有了。
内存溢出(申请不到足够的内存) 是指存储的数据超出了指定空间的大小,这时数据就会越界,举例来说,常见的溢出,是指在栈空间里,分配了超过数组长度的数据,导致多出来的数据覆盖了栈空间其他位置的数据,这种情况发生时,可能会导致程序出现各种难排查的异常行为,或是被有心人利用,修改特定位置的变量数据达到溢出攻击的目的。而Java中的内存溢出,一般指OOM
比如一个hashmap,不断往里面放缓存数据,但是很少考虑这个map的容量问题,结果这个缓存map越来越大,一直占用着老年代的很多空间,时间长了就会导致full gc非常频繁,这就是一种内存泄漏,对于一些老旧数据没有及时清理导致一直占用着宝贵的内存资源,时间长了除了导致full gc,还有可能导致OOM。