word2vec梳理--part2--负采样
在word2vec的第2部分(第1部分在这里(https://blog.csdn.net/fengrucheng/article/details/115705827)),将介绍对skip-gram模型的一系列优化,这些优化使得训练切实可行,因此非常重要。
首先再明确一下我们的任务本质:skip模型--输入中间词,输出周围词(这与CBOW模型不同--输入周围词,输出中间词)
当你看一些关于Word2Vec的skip-gram模型的教程时,你可能已经注意到了一些东西——这是一个巨大的神经网络!
在之前给出的例子中,我们有300维的词向量,以及10000个单词的词汇表。回想一下,神经网络有两个权重矩阵:一个隐藏层和一个输出层。这两个层都有一个权重矩阵,每个权重为300 x 10000=300万!
在这么大的神经网络上运行梯度下降会很慢。更糟糕的是,为了避免过度拟合,你需要大量的训练数据来调整那么多的权重。数以百万计的权重乘以数十亿的训练样本意味着,训练这个模型非常困难。
Word2Vec的作者在他们的第二篇论文(https://arxiv.org/pdf/1310.4546.pdf)中提出了以下两个创新点:
- 对常用词的子采样,减少训练样本数。
- “负采样”来修改优化目标,使得每个训练样本只更新模型权重的一小部分。
值得注意的是,对频繁词进行二次采样以及负采样,不仅减少了训练过程中的计算负担,而且提高了生成的词向量的质量。
常用词的子采样:
在之前的文章中,我们已经讲过如何构造词对形成训练集,这里我们再提一遍。下面的例子是从“The quick brown fox jumps over the lazy dog”这句话中提取的一些训练样本(单词对)。以蓝色突出显示的单词是输入单词。(为了方便,这里窗口大小取值为2)

像“the”这样的常用词有两个“问题”:
- 单词对(“fox”,“the”)并没有告诉我们太多关于“fox”的意思,因为“the”几乎出现在每个单词的上下文中。
- 更多类似(“the”,…)的样本,只能使我们得到一个更好的“the”词向量。
Word2Vec实现了一个“子采样”方案来解决这个问题。对于在训练样本中遇到的每一个词,我们都有可能从样本集中删除它,删掉这个词的概率与这个词的频率有关。
以窗口大小为10为例,从文本中删除“the”意味着:
- 当训练剩下的单词时,“the”不会出现在任何上下文窗口中,不会参与组成任何单词对。
- 将减少10个训练样本,即所有之前包含“the”的单词对。
注意到这两点都有助于解决前面提到的两个问题。
采样概率:
在word2vec的C代码实现里有一个公式,用于计算在词汇表中保留给定单词的概率。
wi是单词,z(wi)是语料库中该单词的频率。例如,如果单词“peanut”在10亿个单词的语料库中出现1000次,那么z('peanut')=1E-6。
代码中还有一个名为“sample”的参数,它控制子采样的概率,默认值为0.001。“sample”值越小意味着被过滤的可能性就越大,剩余的概率越小。
P(wi)是最终保留单词的概率:
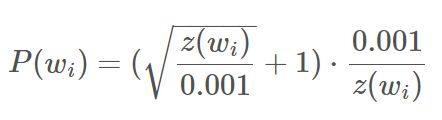
该函数的曲线如下:

语料库中应该没有占过大比例的词,所以我们应该注意x轴非常小对应的部分。
下面是这个函数中一些有趣的地方(同样使用默认的示例值0.001):
- 当z(wi)<=0.0026时,P(wi)=1.0(100%的概率保留)。
- 这意味着只有占比超过0.26%的词会被再抽样。
- 当z(wi)=0.00746时,P(wi)=0.5(50%的概率保留)。
- 当z(wi)=1.0时,P(wi)=0.033(保留的概率为3.3%)。
- 即语料库完全由wi组成,这当然是不可能的。
您可能注意到,论文中函数的定义与C代码中的实现略有不同,但我认为C实现更权威。
负采样:
训练一个神经网络意味着,读入一个训练样本,会微调所有的神经元权值,以便更准确地预测。换句话说,每个训练样本都将微调神经网络中的所有权重。
正如前面所讨论的,巨大的词典意味着skip-gram网络有大量的权值,对每一个样本,所有这些权值都会被微调更新(尤其是输出层的权重)。而这样的样本,我们有数十亿个!
负采样通过让每个样本只更新一小部分权重,而不是全部权重来解决这个问题。下面是它的工作原理。
以输入词对为(“fox”,“quick”)为例,网络的“label”或“correct output”是一个独热向量(one-hot)。即,“quick”对应的输出为1,而其他所有输出神经元,输出为0。
负采样的操作是:随机选择少量的负样本(比如5个)来更新权重(负样本是希望网络输出为0的词)。正样本(即当前示例中的“quick”词)对应的权重依然会更新。(文章中提到,对于较小的数据集,选择5-20个单词很有效;而对于较大的数据集,你可以只使用2-5个单词。)
回想一下,我们模型的输出层有一个300 x 10000的权重矩阵。使用了负采样,我们只需要更新正样本的权重(“quick”),再加上采样的其他5个负样本的权重。即,每次共有6*1800个权值更新,只占输出层3M个权重的0.06%!
在隐藏层,只更新了输入单词的权重(无论是否负采样,在隐藏层都是查表操作)。
负样本的选择
“负样本”(即训练输出0的5个词)是使用“单谱分布”来选择的,其中频率越高的单词越有可能被选为负样本。
例如,将整个训练语料库作为一个单词列表,并从列表中随机选取5个否定样本。在这种情况下,选择“couch”一词的概率,等于“couch”出现在语料库中的次数,除以语料库中出现的单词总数。这可以用以下公式表示:

作者在论文中提到,他们对这个等式做了很多改变,其中表现最好的一个是将使用了3/4次方:

如果对这个函数做抽样比较,可以发现与更简单的公式相比,这个公式有增加不太频繁单词的概率,和减少更频繁单词的概率的趋势。
词对和短语
word2vec的第二篇论文还包含了一个值得讨论的创新点。作者指出,像“Boston Globe”(一份报纸)这样的词对与单独的词“Boston”和“Globe”的含义有很大不同。因此,对于“波士顿环球报”(Boston Globe),无论它出现在文本中的什么地方,都应该视为一个具有自己的词向量表示的单词。
你可以在已发布的模型中看到这个结果。模型是根据Google新闻数据集的1000亿个词训练出来的。模型中添加的短语,将词汇量扩大到了300万个单词!
如果你对他们的词汇量感兴趣,这里(http://mccormickml.com/2016/04/12/googles-pretrained-word2vec-model-in-python/)有一篇文章。你也可以在这里(https://github.com/chrisjmccormick/inspect_word2vec/tree/master/vocabulary)浏览他们的词汇表。