30行代码用streamlit构建你的机器学习模型应用
Streamlit是一个快速构建数据分析和机器学习Web页面的开源Python库。
英文说明:A faster way to build and share data apps
先看一个极简的效果,将一个文本情感分类的模型部署在了HuggingFace的Space托管页面了。
效果如下

大家猜猜做出这个效果需要多少个行代码?100行? 300行?No,全部代码仅需10行,如下所示。
import streamlit as st
from transformers import pipeline
st.title('Text Classification')
pipe = pipeline("text-classification")
text = st.text_area("Enter some text:")
if text:
out = pipe(text)
st.json(out)这个项目部署在了huggingface的space页面中了,可以在网址中进行交互测试。
公众号后台回复关键词: streamlit ,获取本文源代码 和 HuggingFace部署的TextClassification和FasterRCNN演示项目地址。
# 安装
#!pip install streamlit -i https://pypi.tuna.tsinghua.edu.cn/simple
#备注,需要python3.7及以上版本。
# 环境测试
#streamlit hello一,HelloWorld范例
%%writefile demo.py
import streamlit as st
st.write("hello world")!streamlit run demo.py --server.port=8085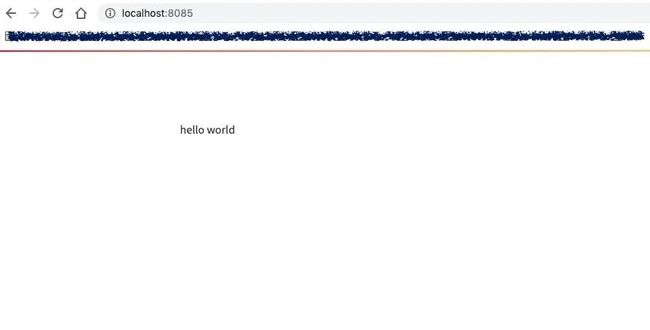
二,MarkDown范例
支持常用的markdown展示
st.markdown: 按照markdown语法呈现内容
st.header
st.subheader
st.code
st.caption: 注释说明
st.text
st.latex
%%writefile demo.py
import streamlit as st
# markdown
st.title('streamlit极简教程')
st.markdown('### 一. 安装')
st.text('和安装其他包一样,安装 streamlit 非常简单,一条命令即可')
code1 = '''pip install streamlit'''
st.code(code1, language='bash')
st.caption("需要python3.7以及以上环境")
st.markdown('### 二. 使用')
st.markdown('#### 1 生成 Markdown 文档')
code2 = '''import streamlit as st
st.markdown('Streamlit Demo')
st.header('标题')
st.text('普通文本')
'''
st.code(code2, language='python')
st.markdown('#### 2 生成 图表')
code3 = '''import streamlit as st
import pandas as pd
chart_data = pd.DataFrame(
np.random.randn(20, 3),
columns=['a', 'b', 'c'])
st.line_chart(chart_data)'''
st.code(code2, language='python')
st.markdown('### 三. 运行')
code4 = '''streamlit run demo.py'''
st.code(code4, language='bash')!streamlit run demo.py --server.port=8085
三,图表范例
支持以下图表展示:
st.table
st.dataframe
st.metric
st.json
st.line_chart
st.bar_chart
st.area_chart
st.map_chart
st.pyplot : matplotlib 的 figure
st.plotly_chart: plotly 的 figure
and more
%%writefile demo.py
import streamlit as st
import numpy as np
import pandas as pd
import plotly.express as px
st.title('streamlit图表范例')
st.header("一,Table/DataFrame示范")
df = pd.DataFrame(
np.random.randn(10, 5),
columns=('第%d列' % (i+1) for i in range(5))
)
#st.table(df)
st.dataframe(df.style.highlight_max(axis=0))
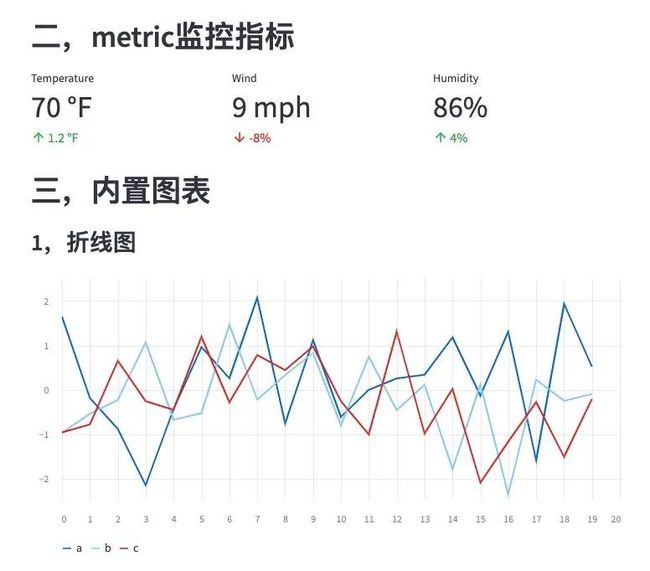
st.header("二,metric监控指标")
col1, col2, col3 = st.columns(3)
col1.metric("Temperature", "70 °F", "1.2 °F")
col2.metric("Wind", "9 mph", "-8%")
col3.metric("Humidity", "86%", "4%")
st.header("三,内置图表")
st.subheader("1,折线图")
chart_data = pd.DataFrame(
np.random.randn(20, 3),
columns=['a', 'b', 'c'])
st.line_chart(chart_data)
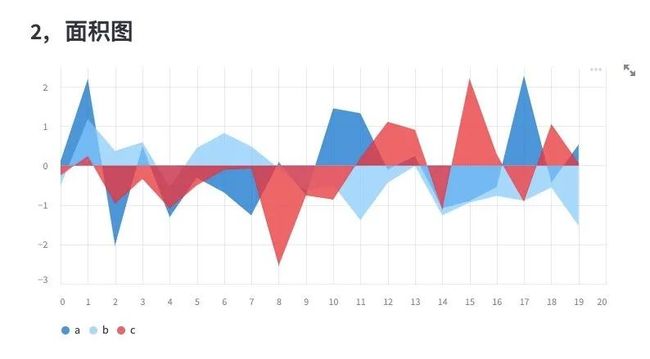
st.subheader("2,面积图")
chart_data = pd.DataFrame(
np.random.randn(20, 3),
columns = ['a', 'b', 'c'])
st.area_chart(chart_data)
st.subheader("3,柱形图")
chart_data = pd.DataFrame(
np.random.randn(50, 3),
columns = ["a", "b", "c"])
st.bar_chart(chart_data)
st.subheader("4,地图")
chart_data = pd.DataFrame(
np.random.randn(1000, 2) / [50, 50] + [37.76, -122.4],
columns=['lat', 'lon']
)
st.map(chart_data)
st.header("四,plotly图表")
fig = px.line(data_frame=px.data.stocks(),x="date",y=["GOOG","AAPL","AMZN","FB"])
st.plotly_chart(fig)!streamlit run demo.py --server.port=8085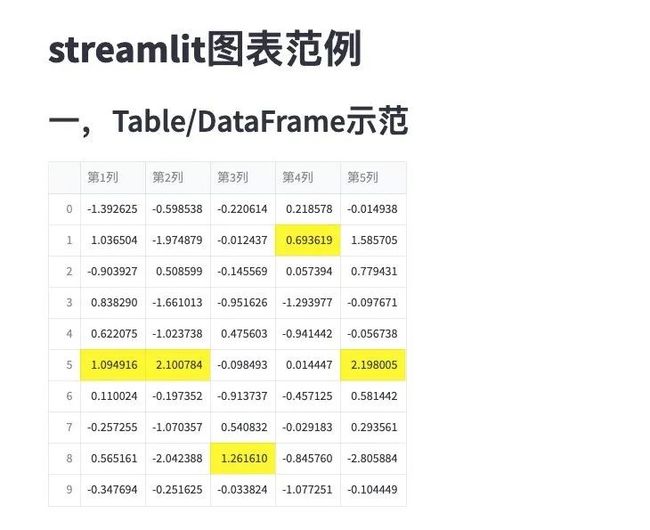
四,控件范例
streamlit支持非常丰富的交互式输入控件。
值得注意的是,当改变任何一个输入时,整个网页会重新计算和渲染。
button:按钮
download_button:文件下载
file_uploader:文件上传
checkbox:复选框
radio:单选框
selectbox:下拉单选框
multiselect:下拉多选框
slider:滑动条
select_slider:选择条
text_input:文本输入框
text_area:文本输入区域
number_input:数字输入框,支持加减按钮
date_input:日期选择框
time_input:时间选择框
color_picker:颜色选择器
下面分别演示一些较高频的控件
1, button
2, selectbox
3, number_input
4, slider
5, text_input
6, text_area
7, download_button
8, file_uploader
%%writefile demo.py
import streamlit as st
import plotly.express as px
import time
import pandas as pd
st.title('streamlit控件范例')
st.header("1,button")
#button常用于启动一段费时代码的执行
if st.button("Start count sheep"):
msg = st.empty() #st.empty可以作为占位符
for i in range(1,11):
msg.write("{} sheep...".format(i))
time.sleep(0.3)
else:
pass #st.stop
st.header("2,selectbox")
stock = st.selectbox(label = "Choose a stock",options=["GOOG","AAPL","AMZN","FB"])
st.write('You selected:', stock)
fig = px.line(data_frame=px.data.stocks(),x="date",y=[stock])
st.plotly_chart(fig)
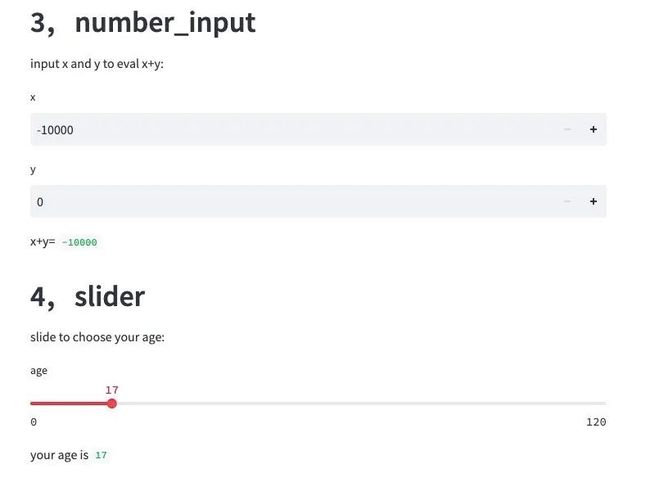
st.header("3,number_input")
st.write("input x and y to eval x+y:")
x = st.number_input("x",min_value=-10000,max_value=10000)
y = st.number_input("y",min_value=0,max_value=8)
st.write('x+y=', x+y)
st.header("4,slider")
st.write("slide to choose your age:")
age = st.slider(label="age",min_value=0,max_value=120)
st.write('your age is ', age)
st.header("5,text_input")
st.write("what's your name")
name = st.text_input(label="name",max_chars=100)
st.write("your name is ",name)
st.header("6,text_area")
st.write("give an introduction of yourself")
name = st.text_area(label="introduction",max_chars=1024)
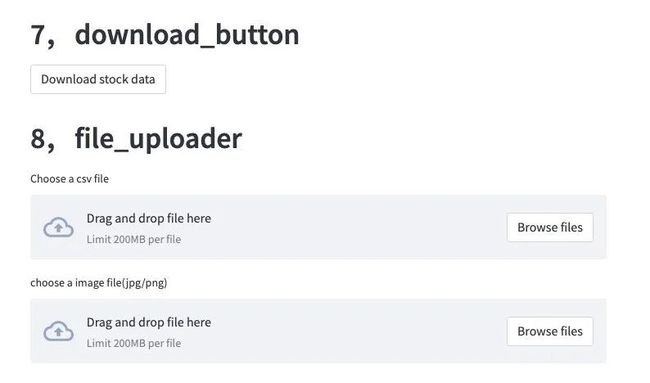
st.header("7,download_button")
@st.cache
def save_csv():
# IMPORTANT: Cache the conversion to prevent computation on every rerun
df = px.data.stocks()
return df.to_csv().encode('utf-8')
csv = save_csv()
st.download_button(
label="Download stock data",
data=csv,
file_name='stocks.csv',
mime='text/csv',
)
st.header("8,file_uploader")
csv_file = st.file_uploader("Choose a csv file")
if csv_file is not None:
try:
dfstocks = pd.read_csv(csv_file)
st.table(dfstocks)
except Exception as err:
st.write(err)
image_file = st.file_uploader("choose a image file(jpg/png)")
if image_file is not None:
try:
st.image(image_file)
except Exception as err:
st.write(err)!streamlit run demo.py --server.port=8085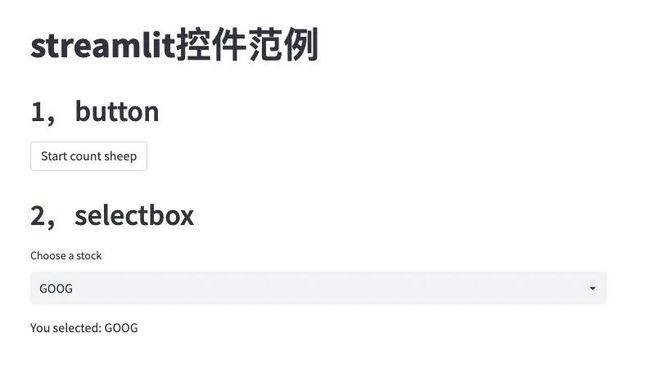


五,布局范例
Streamlit 是自上而下渲染的,组件在页面上的排列顺序与代码的执行顺序一致。
可以应用如下布局组件实现非自上而下的布局。
st.sidebar:侧边栏
st.columns:列布局
st.expander:隐藏
st.empty:占位符,可以后续更新其中内容。
st.container: 容器占位符,可以后续往其中添加内容。
%%writefile demo.py
import streamlit as st
import time
import pandas as pd
st.title('streamlit布局范例')
st.header("1,sidebar")
st.text("see the left side")
with st.sidebar:
st.subheader("配置参数")
optim = st.multiselect(label = "optimizer:",options = ["SGD","Adam","AdamW"])
lr = st.slider(label="lr:",min_value=1e-5,max_value=0.1)
early_stopping = st.checkbox(label = "early_stopping",value=True)
batch_size = st.number_input(label = "batch_size",min_value=1,max_value=64)
st.header("2,columns")
col1, col2, col3 = st.columns(3)
col1.metric("accuracy", "0.82", "+32%")
col2.metric("AUC", "0.89", "-8%")
col3.metric("recall", "0.92", "+4%")
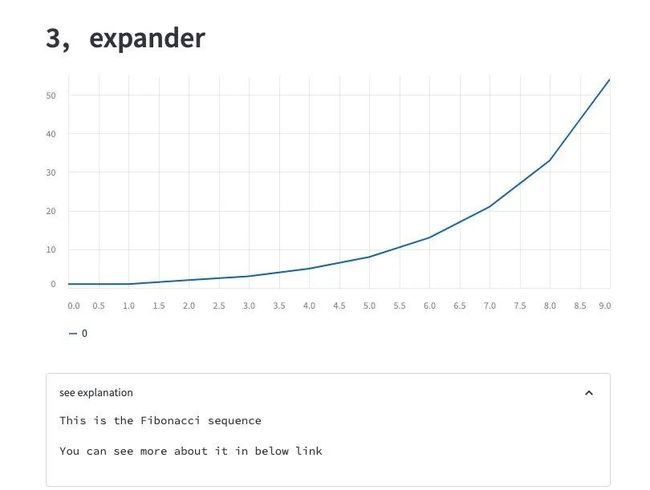
st.header("3,expander")
st.line_chart(data = [1,1,2,3,5,8,13,21,33,54])
with st.expander(label="see explanation"):
st.text("This is the Fibonacci sequence")
st.text("You can see more about it in below link")
st.markdown("[](https://baike.baidu.com/item/%E6%96%90%E6%B3%A2%E9%82%A3%E5%A5%91%E6%95%B0%E5%88%97/99145?fr=aladdin)")
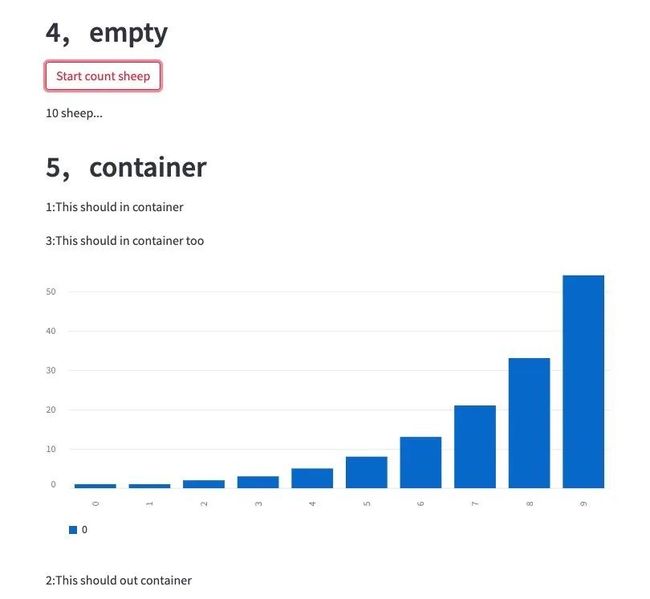
st.header("4,empty")
#st.empty可以作为占位符
if st.button("Start count sheep"):
msg = st.empty() #st.empty可以作为占位符
for i in range(1,11):
msg.write("{} sheep...".format(i))
time.sleep(0.3)
else:
pass #st.stop
st.header("5,container")
container = st.container()
container.write("1:This should in container")
st.write("2:This should out container")
container.write("3:This should in container too")
container.bar_chart(data = [1,1,2,3,5,8,13,21,33,54])!streamlit run demo.py --server.port=8085
六,状态范例
Streamlit支持如下状态范例。
st.progress:进度条,如游戏加载进度
st.spinner:等待提示
st.info:显示常规信息
st.warning:显示报警信息
st.success:显示成功信息
st.error:显示错误信息
st.exception:显示异常信息
st.balloons:页面底部飘气球,表示庆祝
st.snow: 页面飘雪,表示庆祝
%%writefile demo.py
import streamlit as st
import time
if st.button("Start count sheep"):
with st.spinner('Wait for it...'):
bar = st.progress(0)
msg = st.empty() #st.empty可以作为占位符
max_num = 20
for i in range(1,max_num+1):
msg.write("{} sheep...".format(i))
time.sleep(0.3)
bar.progress((i*100)//max_num)
time.sleep(1)
st.success("You count 20 sheep! congratulations")
st.balloons()
time.sleep(1)
st.snow()
else:
pass!streamlit run demo.py --server.port=8085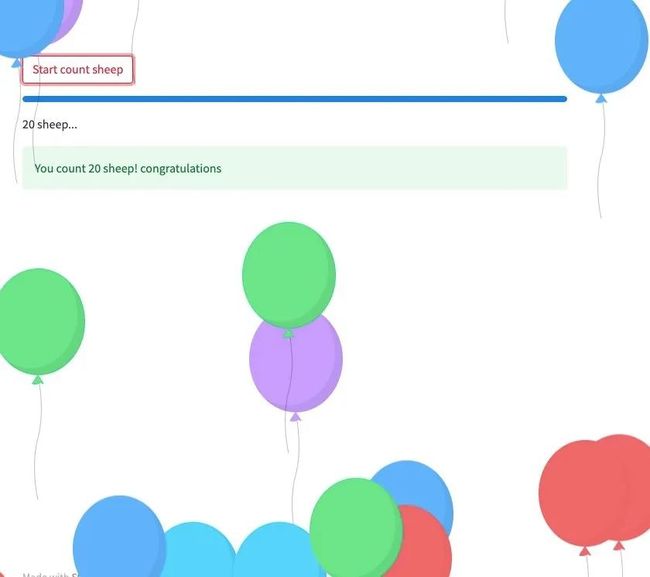
七,综合范例
下面示范一个用streamlit实现一个FasterRCNN的网页交互APP范例。
%%writefile demo.py
import numpy as np
from PIL import Image,ImageColor,ImageDraw,ImageFont
import torch
from torch import nn
import torchvision
from torchvision import datasets, models, transforms
import streamlit as st
# 可视化函数
def plot_detection(image,prediction,idx2names,min_score = 0.8):
image_result = image.copy()
boxes,labels,scores = prediction['boxes'],prediction['labels'],prediction['scores']
draw = ImageDraw.Draw(image_result)
for idx in range(boxes.shape[0]):
if scores[idx] >= min_score:
x1, y1, x2, y2 = boxes[idx][0], boxes[idx][1], boxes[idx][2], boxes[idx][3]
name = idx2names.get(str(labels[idx].item()))
score = scores[idx]
draw.rectangle((x1,y1,x2,y2), fill=None, outline ='lawngreen',width = 2)
draw.text((x1,y1),name+":\n"+str(round(score.item(),2)),fill="red")
return image_result
# 加载模型
@st.cache()
def load_model():
num_classes = 91
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True,num_classes = num_classes)
if torch.cuda.is_available():
model.to("cuda:0")
model.eval()
model.idx2names = {'0': 'background', '1': 'person', '2': 'bicycle', '3': 'car',
'4': 'motorcycle', '5': 'airplane', '6': 'bus', '7': 'train', '8': 'truck', '9': 'boat',
'10': 'traffic light', '11': 'fire hydrant', '13': 'stop sign',
'14': 'parking meter', '15': 'bench', '16': 'bird', '17': 'cat',
'18': 'dog', '19': 'horse', '20': 'sheep', '21': 'cow', '22': 'elephant',
'23': 'bear', '24': 'zebra', '25': 'giraffe', '27': 'backpack',
'28': 'umbrella', '31': 'handbag', '32': 'tie', '33': 'suitcase',
'34': 'frisbee', '35': 'skis', '36': 'snowboard', '37': 'sports ball',
'38': 'kite','39': 'baseball bat', '40': 'baseball glove', '41': 'skateboard',
'42': 'surfboard', '43': 'tennis racket', '44': 'bottle', '46': 'wine glass',
'47': 'cup', '48': 'fork', '49': 'knife', '50': 'spoon', '51': 'bowl',
'52': 'banana', '53': 'apple', '54': 'sandwich', '55': 'orange',
'56': 'broccoli', '57': 'carrot', '58': 'hot dog', '59': 'pizza',
'60': 'donut', '61': 'cake', '62': 'chair', '63': 'couch',
'64': 'potted plant', '65': 'bed', '67': 'dining table',
'70': 'toilet', '72': 'tv', '73': 'laptop', '74': 'mouse',
'75': 'remote', '76': 'keyboard', '77': 'cell phone',
'78': 'microwave', '79': 'oven', '80': 'toaster',
'81': 'sink', '82': 'refrigerator', '84': 'book',
'85': 'clock', '86': 'vase', '87': 'scissors',
'88': 'teddybear', '89': 'hair drier', '90': 'toothbrush'}
return model
def predict_detection(model,image_path,min_score=0.8):
# 准备数据
inputs = []
img = Image.open(image_path).convert("RGB")
img_tensor = torch.from_numpy(np.array(img)/255.).permute(2,0,1).float()
if torch.cuda.is_available():
img_tensor = img_tensor.cuda()
inputs.append(img_tensor)
# 预测结果
with torch.no_grad():
predictions = model(inputs)
# 结果可视化
img_result = plot_detection(img,predictions[0],
model.idx2names,min_score = min_score)
return img_result
st.title("FasterRCNN功能演示")
st.header("FasterRCNN Input:")
image_file = st.file_uploader("upload a image file(jpg/png) to predict:")
if image_file is not None:
try:
st.image(image_file)
except Exception as err:
st.write(err)
else:
image_file = "horseman.png"
st.image(image_file)
min_score = st.slider(label="choose the min_score parameter:",min_value=0.1,max_value=0.98,value=0.8)
st.header("FasterRCNN Prediction:")
with st.spinner('waitting for prediction...'):
model = load_model()
img_result = predict_detection(model,image_file,min_score=min_score)
st.image(img_result)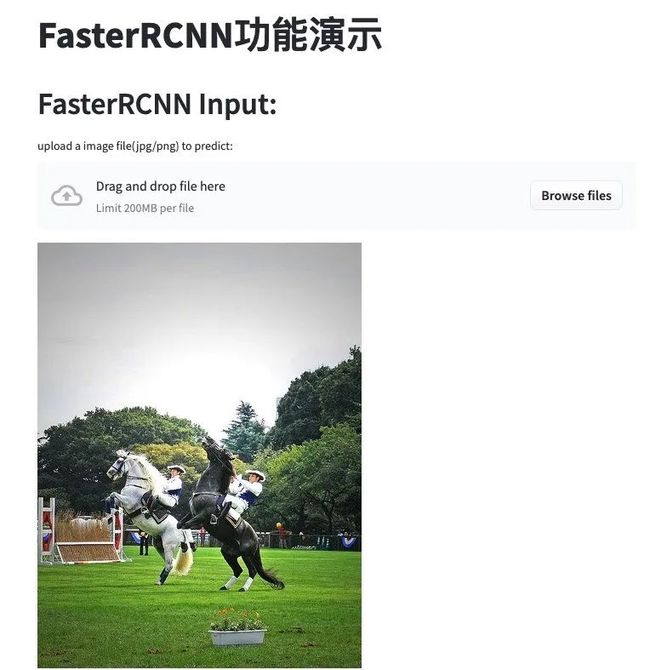

八,部署到HuggingFace
为了便于向合作伙伴展示我们的模型App,可以将stremlit的模型部署到 HuggingFace的 Space托管空间中,完全免费的哦。
方法如下:
1,注册huggingface账号:https://huggingface.co/join
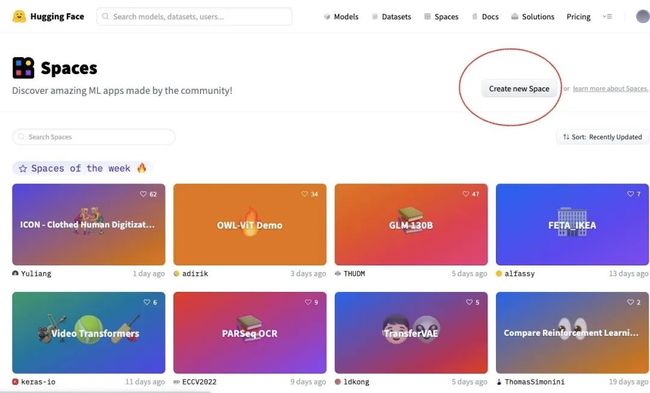
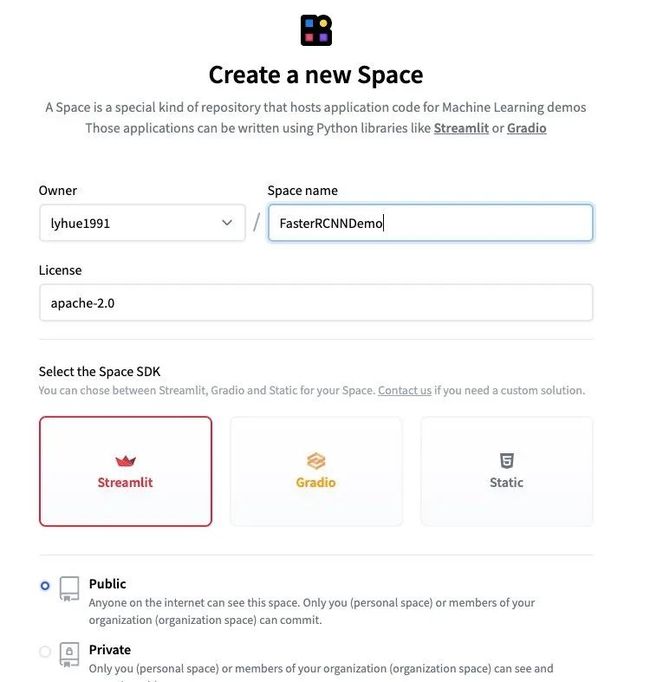
2,在space空间中创建项目:https://huggingface.co/spaces
3,创建好的项目有一个Readme文档,根据说明操作即可。
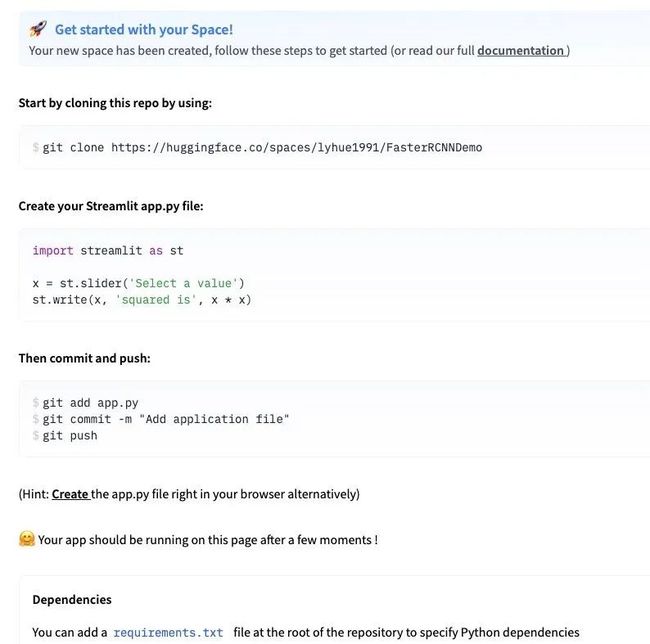
以上。
公众号后台回复关键词:streamlit,获取本文源代码 和 HuggingFace部署的TextClassification和FasterRCNN演示项目地址。
