葵花宝典之C语言冷知识(二)
目录
(一)图形的打印
判断类型
逻辑简单易找规律型。
存在坐标规律的图案打印
(二)中值的表达形式
(x+y)/2 表达错误的原因
有符号数据边界值的分析
修改方式 mid = min +(max-min)/2
(三)与字符相关的经验
单个字符与字符串的表达形式及区别
NUM 1 :单引号内的是字符,双引号内的是字符串。
NUM 2 :多个字符串为了简洁用二维数组进行表示。
NUM 3 :双引号表示的不仅是字符串其本质是存放字符串数据的首地址
(四)对于浮点数的计算以及Math函数使用注意事项
对于浮点数的计算的注意事项
对于Math函数的使用注意事项
(五)强转操作符的定义
( *(void (*)())0)();
首先我们要清楚的就是函数的优先级
之后将括号一层一层剥离
PART 1:(内容1)()
PART 2:*(内容2)0
PART 3:void(*)()
PART 3:内容为一个函数指针用于找到函数,进一步调用该函数
PART 2:我们()0为强转操作,将0强转为一个函数的地址然后再解引用,调用我们地址为0的函数。
PART 1:调用该位置的函数形参为void
强转操作符的表达形式
(函数指针) float(*h)(); ———— (float(*)())
(整型变量) int a; ———— (int)
(指针数组) int * arr[3]; ———— (int * [3])
(数组指针) int (*parr[3])[5]; ———— (int(*[3])[5])
本期我们的C语言冷知识系列同样精选了五个超实用的C语言知识,有时候对于这些只是一不小心的忽略就可能导致运行上面的错误,我们冷知识系列要做的就是总结经验让大家少走弯路,解决时间变得更好。那么我们直奔主题,来向大家开始我们本期的内容吧!
(一)图形的打印
对于经常刷题的伙伴们可能发现了经常会遇到那些需要打印图形的题目,他们或多或少都是有规律的形状。面对这类图形打印问题不能说是不会写,但是大致会解决的很麻烦,往往都得利用好几个循环嵌套才可以将题目完美的解出来。那么小伙伴们可能会问了,有没有什么技巧呢?当然有。那么我们就快来看看吧!
判断类型
首先我们要做的就是分析题目判断题目的类型。题目的类型大致分为两种。针对不同的类型我们需要采用不同的解决方案,才可以是我们的效率最大化。
逻辑简单易找规律型。
这种的我们只需要看一眼不需要太复杂的逻辑前面放几个空格,在打印几个星号。像这种特别容易找到规律的,我们就可以利用图案之间的规律进行进行图形的构建。比如我们下面的题目:
//直角三角形图案的打印
#include
int main()
{
int i = 0, j = 0, n = 0;
while (scanf("%d", &n) != EOF)
{
for (i = 1; i <= n; i++)
{
for (j = 0; j < i; j++)
{
printf("*");
if (j < i - 1)
{
printf(" ");
}
}
printf("\n");
}
}
return 0;
} 我们很容易就可以将我们的规律表达出来的,就采用直接循环表达规律。还有一个比较典型的例子:

我们同样可以很快的找出规律,并且和容易就将我们的规律就表达出来的(空格n-0,*每排递增)我们完全可以直接将这些规律利用循环嵌套的形式表示出来,以达到解决问题的效果。
//箭型的打印
#include
int main()
{
int i = 0, j = 0,a=0, n = 0;
while (scanf("%d", &n)!=EOF)
{
//打印上半部分规律图案
for (i = 1; i <= n + 1; i++)
{
for (a = 0; a < n-i+1; a++)
{
printf(" ");
}
for (j = 0; j < i; j++)
{
printf("*");
}
printf("\n");
}
//打印下半部分规律图案
for (i = n; i >= 1; i--)
{
for (a = 0; a < n - i + 1; a++)
{
printf(" ");
}
for (j = 0; j < i; j++)
{
printf("*");
}
printf("\n");
}
}
return 0;
} 当然我们的我们博客介绍的目标并不是这种冗长的打印方法,我们需要对他们的另一个分支进行介绍。
存在坐标规律的图案打印
我们在本次博客中主要想向大家展示的新思想是对于存在坐标规律图案的打印的方式。我们先看例题:

打印一个空心的正方形,对于我们第一种方法我们该会怎么办?寻找行数与列数和空格之间的规律?但是你会发现光是总结规律化的时间就不比之前编写一个代码的时间短,更别提到后面编写拥有复杂逻辑的代码了。那么我们就需要换一个角度进行思考了。
我们需要考虑的就是需要打印的图形是否存在坐标方面的规律。就像我们本题中的,每行第一行和最后一行均有 * 。每列第一列和最后一列均有 * 。
那么这就好办了,说到坐标,大家想到的应该是什么?当然是数组了!我们可以将需要打印的空心正方体看成一个 n*n 的数组。我们要做的只是向其中填写元素就行了。然后利用循环嵌套对二位数组进行打印 [ 0 ] [ i ] 和 [ n-1 ] [ i ] 上面我们需要全部打印上 * ,[ i ] [ 0 ] 和 [ i ] [ n-1 ] 上我们也需要全部打印成 * 。其余的位置上我们全部放上空格即可。
//空心正方形的打印
#include
int main()
{
int i = 0, j = 0, n = 0;
while (scanf("%d", &n) != EOF)
{
for (i = 1; i <= n; i++)
{
for (j = 0; j < n; j++)
{
if (i == 1 || i == n)
{
printf("* ");
}
else if((i!=1&&i!=n)&&(j==0||j==n-1))
{
printf("* ");
}
else
{
printf(" ");
}
}
printf("\n");
}
}
} 是不是逻辑一下子清晰不少呢?相对应的我们代码的编写也简单不少。所以我们在做图形打印题的时候要现在大脑中比较一下直接寻找规律与寻找坐标规律打印图形编码的快慢程度,最终使我们的效率提高。对比我们上面的打印箭型的题目来说,打印箭型最好的方法就是寻找规律,因为他们并没有特别的坐标规律。多动脑会让我们变得更加高效优秀!
(二)中值的表达形式
说到中值大家会想到什么?当我们拥有两个数字的时候将两个数字相加之后的和除以二?我们之前上数学课就是这么学的,一定没什么问题吧?但是我只能很遗憾地告诉你,这样的中值表达形式也只有在数学上可以这么表达,而到了我们程序设计当中中值这样表达就会出现意想不到的错误了。
(x+y)/2 表达错误的原因
这个原因需要从C语言数据的存储形式开始说起。
总所周知的是:C语言中的数字分为有符号数以及无符号数。有符号数最高位为符号位,无符号数全部为计数位。所以一般我们无符号数的取值范围是有符号数的两倍。
同时由于我们不同的数据类型所占的字节数的长度不同所以每一种数据都会有一定的界限值。一旦超越了数据本身的界限值的话就会出现“循环”的现象。因此我们需要特别注意的就是对有符号数据的计算。
那我们占一个字节的 char 类型数据进行举例。我们知道的是 char 类型数据占一个字节的位置,所以对于有符号数来说其表示的范围也就是:-128—127 。
当我们输入一个大于127的数字的时候就会发现打印的数字数字不再是我们的正数了,而是一个负数,这就是我们有符号数的正数表达到达了界限所造成的。实际情况如下图所示:

从上面我们先知道有符号数据存储存在这样的现象之后在进一步对其进行更深层次的分析。
有符号数据边界值的分析
我们经过上面的现象之后就会发现其实有符号数据在计算机中存储其实是有一定的边界的,而这个边界值就是我们该类型的无符号数据所表示值。
就比如说:char 正数范围加上负数的范围之和是无符号 char 的范围。正数和负数的值又正好从中间划分开来。我们就可以为了便于理解将我们的数据类型的表示形式化为一个密闭的圆进行理解。如下图所示:

我们可以发现上面实际输入的数据一旦超出了边界的限制就会变成负数,这就是上面我们说的(x+y)/ 2 可能出错的原因,数据 x + y 的值一旦超出了边界的话就会变成负数,那么一个负数即使除以二的话也是负数,与我们预期的结果大相径庭。那么我们应该怎么表达两个数的中值呢?我们接下来就来介绍。
修改方式 mid = min +(max-min)/2
这一步就是我们修改的过程了,试想这两个数据的中间值那不就是较小的数据加上两个数据的差值的二分之一吗?我们不妨同样用来验证一下我们这个思路:
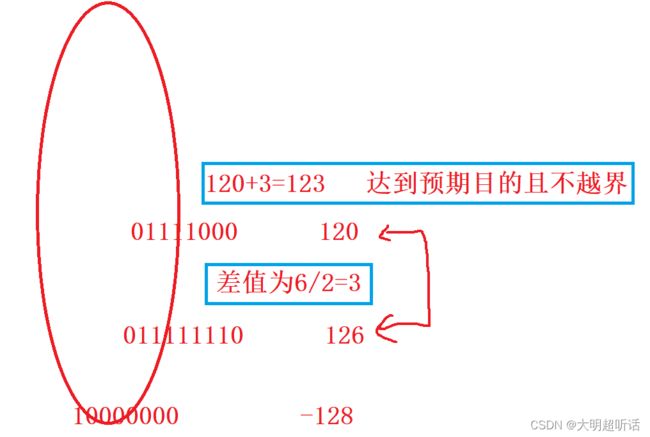
经过验证之后这样就可以避免我们由于数据超出边界导致出现负数的情况并且可以达到我们的预期效果。所以我们通常要表达中值的时候 mid = max+(max-min)/2 是最规范的表达形式(经查阅资料后的结论)。
(三)与字符相关的经验
单个字符与字符串的表达形式及区别
NUM 1 :单引号内的是字符,双引号内的是字符串。
相信这个规律大多小伙伴们早都已经发现了,我们想要在此让大家注意的目标也不是这一点。
NUM 2 :多个字符串为了简洁用二维数组进行表示。
通常我们知道的是,对于一个单个的字符串我们通常将它放到一个一维数组中进行使用,这是因为我们将他们每一个字母当作是一个数组中的元素看待,所以我们就需要知道当我们需要表达多个数组的时候就可以将多个字符串放到一个二维数组中进行引用便于管理以及缩减篇幅。
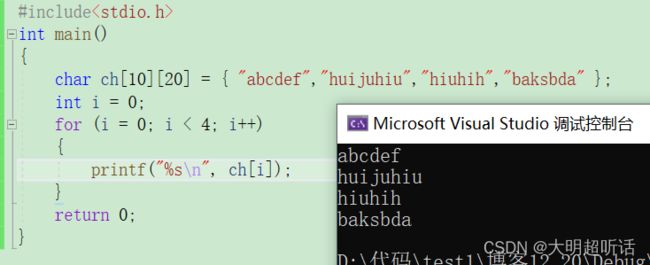
#include
int main()
{
char ch[10][20] = { "abcdef","huijuhiu","hiuhih","baksbda" };
int i = 0;
for (i = 0; i < 4; i++)
{
printf("%s\n", ch[i]);
}
return 0;
} 需要我们特别注意的重点是字符串二维数组和普通的二维数组具有一样的性质,一维数据表示字符串的个数,二维数据表达的是字符串的最大长度,但是需要注意的是,字符串中会默认放置一个 ' \ 0 ' 因此我们需要对二维数据中的值进行特别注意防止在调用的时候出现数组越界的情况。
NUM 3 :双引号表示的不仅是字符串其本质是存放字符串数据的首地址
不知道大家发觉了没有,我们第一次学习C语言所要求写的程序都会是 Hello World !这串字符串是直接用双引号放在 printf 当中的,但是你想过吗?这就仅仅是一个字符串吗?我们正规的字符串形式的打印不应该是 printf("%s","Hello World!"); 吗?为什么这样也可以?
追根求底你会发现其实 printf 的本质也是对于指针内容的打印,我们放入printf中打印的字符串其实都是指明一个字符串的首地址之后就开始向后一步一步进行打印,直到遇到 ' \ 0 ' 停止。
printf 可以直接打印一个字符串的原因也是双引号括住的字符串其实就是一个地址,这个地址也就是字符串的首地址。我们还可形式进行验证:
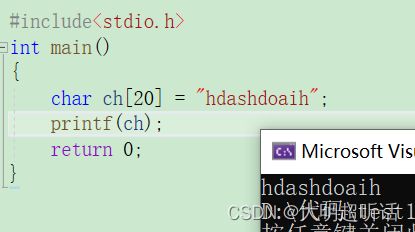
假如我们 printf 检测的字符串表达的是存储字符串的首地址的话我们就可以利用数组来验证我们的猜想,因为数组所表达的意思也是存储数据的首地址。那么也就是说我们直接将数组名放置于printf也可以直接打印出我们想要的结果,事实也确实如同我们想的一样,进一步验证了我们的结论:字符串的深度含义是字符的首地址,printf 对于字符串打印的接受本质上是对于字符串首地址的接受。
(四)对于浮点数的计算以及Math函数使用注意事项
对于浮点数的计算的注意事项
这一部分我想对大家说的是一个属于做题习惯上面的问题:需要特别注意的是,当我们在进行浮点数计算的时候我们需要特别注意计算中的数据命名类型,对于我们自己编写的程序,一旦存在浮点数的计算(加减乘除)最好还是将数据都定义成 double 类型为好。这一部分原因还是与浮点数在数据内存中的存储有关。
据我们所知浮点数在内存中都是近似存储的可能因为表达不到位而出现精度上的错误,因此我们为了提高精度,减小数据在计算的时候因为精度造成的计算误差我们最好将小数定义成 double 类型的数据。错误样例如下:
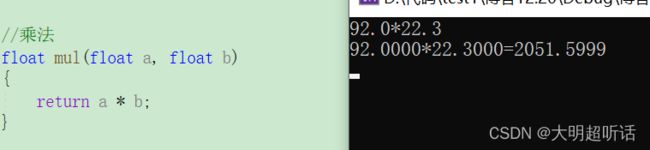
如图我们上面的数据很显然是一个错误,92.0*22.3 不可能出现小数位为 5999 的形式,我们可以通过监视窗口观察到出现这种错误的原因。
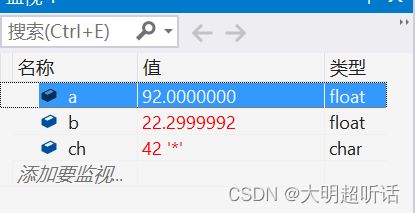
我们可以发现的是我们 92.0 存储的数据没有变化,但是我们 22.3 的数据在内存中存储的却是 22.2999992 这样一个只能说在约等上等于我们 22.3 的一个数据。这也就是我们结果出现错误的原因。同样的,加入我们家数据的类型定义为 double 类型在此进行观察。

我们可以发现的是同样存在误差,但是误差并不影响我们的计算结果,这就是我们使用double 类型的好处,因此我再次特别想大家提出建议,对于小数的计算还是最好使用 double 类型进行定义的好这样可以减少了不必要的错误。毕竟OJ的疯狂你想象不到,成百上千次的尝试总能找到你的错误。那么我就将上面情况出现错误的题目也展示给大家,大家可以去尝试一下。

#include
#define EPS 1e-7
//加法
double add(double a, double b)
{
return a + b;
}
//减法
double sub(double a, double b)
{
return a - b;
}
//乘法
double mul(double a, double b)
{
return a * b;
}
double div(double a, double b)
{
return a / b;
}
int main()
{
double a = 0, b = 0;
char ch = 0;
while (scanf("%lf%c%lf", &a, &ch, &b) != EOF)
{
switch (ch)
{
case'+':
printf("%.4f%c%.4f=%.4f\n", a, ch, b, add(a, b));
break;
case'-':
printf("%.4f%c%.4f=%.4f\n", a, ch, b, sub(a, b));
break;
case'*':
printf("%.4f%c%.4f=%.4f\n", a, ch, b, mul(a, b));
break;
case'/':
if (b < EPS && b > -EPS)
{
printf("Wrong!Division by zero!\n");
break;
}
printf("%.4f%c%.4f=%.4f\n", a, ch, b, div(a, b));
break;
default:
printf("Invalid operation!\n");
break;
}
}
return 0;
} 对于Math函数的使用注意事项
这一部分我想跟大家说的其实跟我们上面浮点数计算中想对大家说的一样。math函数为了方便大家进行计算,考虑到使用者可能利用 math 头文件可能回去处理一些小数的数据因此特别将math函数的所有类型都定义为 double 以此来提高计算的精确度。
同样也验证了我们上面总结的经验在进行小数运算的时候,为了提高准确度最好定义 double 类型的数据进行使用。
在使用我们math函数的时候需要注意格式上的对称性,即math函数返回值也是 double 类型不进行强转直接使用的话会出现编译器警告,但是没有什么特别的影响,所以在此只点到为止。
下面让我们来看一下常见的math函数的格式吧!
开平方函数:

求绝对值函数:

x 的 y 次方函数:

(五)强转操作符的定义
这一部分主要带领大家分析《C陷阱与缺陷》上面的一道与强转操作符有关的题目,以提高大家对复杂代码的分析能力。
首先题目的内容是这样的:作者正在编写一个独立运行于某种微处理器上的C程序。当计算机启动的时候,硬件就调用首地址为 0 位置的函数程序。为了模拟开机启动时的情景,我们必须设计出一个C语句,以显示调用该函数的情况。所以作者写出了以下语句:
( *(void (*)())0)();
是不是一眼看上去有种无所适从的感觉,这是什么鬼?!!别着急,我们来一点一点进行这个语句的分析,等分析结束的时候你就会恍然大悟,原来这也不难嘛!
首先我们要清楚的就是函数的优先级
我们需要知道的是()这个操作符在函数读取分析的时候具有最高层次的优先级,也就是说一旦出现了()程序就会优先确定()里面的成分。
之后将括号一层一层剥离
由于我们所需要分析的内容中括号里面嵌套括号的形式是在令我们心惊胆战因此我们需要将括号一层一层剥离,最里面的部分是程序最先要是别的,依次向外进行。那么我们的程序识别的顺序就是:
PART 1:(内容1)()
PART 2:*(内容2)0
PART 3:void(*)()
我们根据上面的条件一次分析剥离就得到了上面三个部分我们程序一次的读取顺序就是part3 -> part2 -> part1 。怎么样?这样看是不是逻辑清晰多了?我们也来根据我们程序读取的顺序依次分析作者的目的:
PART 3:内容为一个函数指针用于找到函数,进一步调用该函数
PART 2:我们()0为强转操作,将0强转为一个函数的地址然后再解引用,调用我们地址为0的函数。
PART 1:调用该位置的函数形参为void
上面也就是我们的全部内容的分析了。最内层括号中的数据为一个函数指针,由于系统对于 0 只会将其识别为一个整形不会将其认为是一个函数的地址,因此达不到函数调用的效果,因此我们第一步要做的就是将 0 强转为函数指针类型的数据。最后解引用调用该函数。是不是这么一看也不算太难?
强转操作符的表达形式
就像是我们上面的展示一样(void *())就是一个强转操作符,对于我们前传操作符的表达一旦我们知道了如何声明一个类型的数据之后,那么该类型的类型转化符就很容易得到了:只需要把声明中的变量名和声明末尾的分号去掉,再将剩下的部分用一个括号整个“封装”起来即可。例如以下声明转换成强转操作符的形式:
(函数指针) float(*h)(); ———— (float(*)())
(整型变量) int a; ———— (int)
(指针数组) int * arr[3]; ———— (int * [3])
(数组指针) int (*parr[3])[5]; ———— (int(*[3])[5])
经过我们上面的示范示例,相信大家已经对强转操作的改写有了一定的了解了。那么我们本次的博客内容也就到此为止了。要点不多但是很全面,感谢大家的观看,祝大家天天开心。
