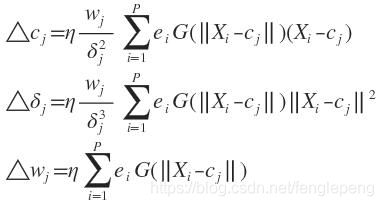深度学习之 RBF神经网络
RBF神经网络通常只有三层,即输入层、中间层和输出层。其中中间层主要计算输入x和样本矢量c(记忆样本)之间的欧式距离的Radial Basis Function (RBF)的值,输出层对其做一个线性的组合。
径向基函数:
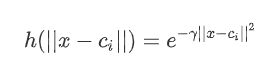
RBF神经网络的训练可以分为两个阶段:
第一阶段为无监督学习,从样本数据中选择记忆样本/中心点;可以使用聚类算法,也可以选择随机给定的方式。
第二阶段为监督学习,主要计算样本经过RBF转换后,和输出之间的关系/权重;可以使用BP算法计算、也可以使用简单的数学公式计算。

1. 随机初始化中心点
2. 计算RBF中的激活函数值,每个中心点到样本的距离
3. 计算权重,原函数:Y=GW
4. W = G^-1Y
RBF网络能够逼近任意非线性的函数(因为使用的是一个局部的激活函数。在中心点附近有最大的反应;越接近中心点则反应最大,远离反应成指数递减;就相当于每个神经元都对应不同的感知域)。
可以处理系统内难以解析的规律性,具有很好的泛化能力,并且具有较快的学习速度。
有很快的学习收敛速度,已成功应用于非线性函数逼近、时间序列分析、数据分类、模式识别、信息处理、图像处理、系统建模、控制和故障诊断等。
当网络的一个或多个可调参数(权值或阈值)对任何一个输出都有影响时,这样的网络称为全局逼近网络。由于对于每次输入,网络上的每一个权值都要调整,从而导致全局逼近网络的学习速度很慢,比如BP网络。
如果对于输入空间的某个局部区域只有少数几个连接权值影响输出,则该网络称为局部逼近网络,比如RBF网络。
RBF和BP神经网络的对比
BP神经网络(使用Sigmoid激活函数)是全局逼近;RBF神经网络(使用径向基函数作为激活函数)是局部逼近;
相同点:
- 1. RBF神经网络中对于权重的求解也可以使用BP算法求解。
不同点:
- 1. 中间神经元类型不同(RBF:径向基函数;BP:Sigmoid函数)
- 2. 网络层次数量不同(RBF:3层;BP:不限制)
- 3. 运行速度的区别(RBF:快;BP:慢)
简单的RBF神经网络代码实现
# -*- coding:utf-8 -*-
"""
@Time :
@Author: Feng Lepeng
@File : RBF_demo.py
@Desc :
"""
import numpy as np
import matplotlib as mpl
from matplotlib import pyplot as plt
from scipy.linalg import norm, pinv # norm 求模,pinv 求逆
mpl.rcParams["font.sans-serif"] = ["SimHei"]
np.random.seed(28)
class RBF:
"""
RBF径向基神经网络
"""
def __init__(self, input_dim, num_centers, out_dim):
"""
初始化函数
:param input_dim: 输入维度数目
:param num_centers: 中间的核数目
:param out_dim:输出维度数目
"""
self.input_dim = input_dim
self.out_dim = out_dim
self.num_centers = num_centers
self.centers = [np.random.uniform(-1, 1, input_dim) for i in range(num_centers)]
self.beta = 8
self.W = np.random.random((self.num_centers, self.out_dim))
def _basisfunc(self, c, d):
return np.exp(-self.beta * norm(c - d) ** 2)
def _calcAct(self, X):
G = np.zeros((X.shape[0], self.num_centers), float)
for ci, c in enumerate(self.centers):
for xi, x in enumerate(X):
G[xi, ci] = self._basisfunc(c, x)
return G
def train(self, X, Y):
"""
进行模型训练
:param X: 矩阵,x的维度必须是给定的 n * input_dim
:param Y: 列的向量组合,要求维度必须是n * 1
:return:
"""
# 随机初始化中心点
rnd_idx = np.random.permutation(X.shape[0])[:self.num_centers]
self.centers = [X[i, :] for i in rnd_idx]
# 相当于计算RBF中的激活函数值
G = self._calcAct(X)
# 计算权重==> Y=GW ==> W = G^-1Y
self.W = np.dot(pinv(G), Y)
def test(self, X):
""" x的维度必须是给定的n * input_dim"""
G = self._calcAct(X)
Y = np.dot(G, self.W)
return Y
if __name__ == '__main__':
# 构造数据
n = 100
x = np.linspace(-1, 1, n).reshape(n, 1)
y = np.sin(3 * (x + 0.5) ** 3 - 1)
# RBF神经网络
rbf = RBF(1, 20, 1)
rbf.train(x, y)
z = rbf.test(x)
plt.figure(figsize=(12, 8))
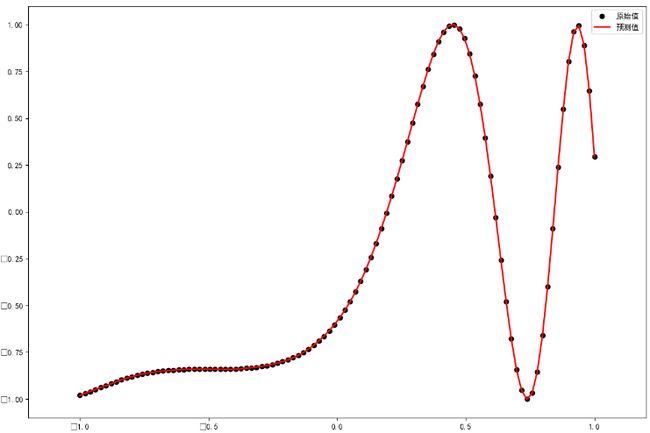
plt.plot(x, y, 'ko', label="原始值")
plt.plot(x, z, 'r-', linewidth=2, label="预测值")
plt.legend()
plt.xlim(-1.2, 1.2)
plt.show()
效果图片:
RBF训练
RBF函数中心,扩展常数,输出权值都应该采用监督学习算法进行训练,经历一个误差修正学习的过程,与BP网络的学习原理一样.同样采用梯度下降爱法,定义目标函数为:
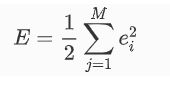
ei为输入第i个样本时候的误差。
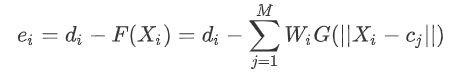
这个等式输出函数中忽略了阈值,为使目标函数最小化,各参数的修正量应与其梯度成正比。