python 中,sklearn包下的f1_score、precision、recall使用方法,Accuracy、Precision、Recall和F1-score公式,TP、FP、TN、FN的概念
目录
1.sklearn.metrics.f1_score
2.sklearn.metrics.precision_score
3.sklearn.metrics.recall_score
4.Accuracy,、Precision、 Recall和F1-score公式
5.TP、FP、TN、FN的概念
sklearn.metrics.f1_score官网链接sklearn.metrics.f1_score — scikit-learn 1.0.2 documentation
sklearn.metrics.f1_score(y_true, y_pred, *, labels=None, pos_label=1,
average='binary', sample_weight=None, zero_division='warn')重要参数说明:
y_true:一维数组,或标签指示数组/稀疏矩阵 (真实值)
y_pred:一维数组,或标签指示数组/稀疏矩阵 (预测值)
pos_label:str or int, default=1
报告是否average='binary'且数据为binary的类。如果数据是多类或多标签的,这将 被忽略;设置labels=[pos_label]和average != 'binary'将只报告该标签的分数。
average:{‘micro’, ‘macro’, ‘samples’,’weighted’, ‘binary’} or None, default=’binary’
多类/多标签目标时需要此参数。如果为None,则返回每个类的分数。否则,这决定了对数据进行平均的类型:
“binary”: 只报告由pos_label指定的类的结果。这只适用于目标(y_{true,pred})是二进制的情况。
“micro”: 通过计算总真阳性、假阴性和假阳性来全局计算指标。
“macro”: 计算每个标签的度量,并找到它们的未加权平均值。这还没有考虑到标签的不平衡。
“weighted”: 计算每个标签的指标,并根据支持找到它们的平均权重(每个标签的真实实例数)。这改变了“宏观”的标签不平衡;它会导致一个不介于准确率和召回率之间的f值。
“samples”: 为每个实例计算指标,并找到它们的平均值(仅对与accuracy_score不同的多标签分类有意义)。
sample_weight:array-like of shape (n_samples,), default=None
样本的权重
zero_division:“warn”, 0 or 1, default=”warn”
设置除法为零时返回的值,即所有预测和标签为负数时返回。如果设置为" warn ",这将充当0,但也会引发警告。
返回值:
f1_score:float or array of float, shape = [n_unique_labels]
二分类中正类的F1分,
或多类任务中,每个类的F1分的加权平均。示例:
from sklearn.metrics import f1_score
y_true = [0, 1, 1, 1, 2, 2]
y_pred = [0, 1, 1, 2, 1, 2]
macro_f1 = f1_score(y_true, y_pred, average='macro')
micro_f1 = f1_score(y_true, y_pred, average='micro')
weighted_f1= f1_score(y_true, y_pred, average='weighted')
None_f1 = f1_score(y_true, y_pred, average=None)
print('macro_f1:',macro_f1,'\nmicro_f1:',micro_f1,'\nweighted_f1:',
weighted_f1,'\nNone_f1:',None_f1)输出结果:
macro_f1: 0.7222222222222222
micro_f1: 0.6666666666666666
weighted_f1: 0.6666666666666666
None_f1: [1. 0.66666667 0.5 ]sklearn.metrics.precision_score官网链接
sklearn.metrics.precision_score — scikit-learn 1.1.1 documentation
sklearn.metrics.precision_score(y_true, y_pred, *, labels=None, pos_label=1,
average='binary', sample_weight=None, zero_division='warn')重要参数意义与f1-score类似
代码实例:
>>> from sklearn.metrics import precision_score
>>> y_true = [0, 1, 2, 0, 1, 2]
>>> y_pred = [0, 2, 1, 0, 0, 1]
>>> precision_score(y_true, y_pred, average='macro')
0.22...
>>> precision_score(y_true, y_pred, average='micro')
0.33...
>>> precision_score(y_true, y_pred, average='weighted')
0.22...
>>> precision_score(y_true, y_pred, average=None)
array([0.66..., 0. , 0. ])
>>> y_pred = [0, 0, 0, 0, 0, 0]
>>> precision_score(y_true, y_pred, average=None)
array([0.33..., 0. , 0. ])
>>> precision_score(y_true, y_pred, average=None, zero_division=1)
array([0.33..., 1. , 1. ])
>>> # multilabel classification
>>> y_true = [[0, 0, 0], [1, 1, 1], [0, 1, 1]]
>>> y_pred = [[0, 0, 0], [1, 1, 1], [1, 1, 0]]
>>> precision_score(y_true, y_pred, average=None)
array([0.5, 1. , 1. ])sklearn.metrics.recall_score官网链接
sklearn.metrics.recall_score — scikit-learn 1.1.1 documentation
sklearn.metrics.recall_score(y_true, y_pred, *, labels=None, pos_label=1,
average='binary',sample_weight=None, zero_division='warn')重要参数意义与f1-score类似
代码实例:
>>> from sklearn.metrics import recall_score
>>> y_true = [0, 1, 2, 0, 1, 2]
>>> y_pred = [0, 2, 1, 0, 0, 1]
>>> recall_score(y_true, y_pred, average='macro')
0.33...
>>> recall_score(y_true, y_pred, average='micro')
0.33...
>>> recall_score(y_true, y_pred, average='weighted')
0.33...
>>> recall_score(y_true, y_pred, average=None)
array([1., 0., 0.])
>>> y_true = [0, 0, 0, 0, 0, 0]
>>> recall_score(y_true, y_pred, average=None)
array([0.5, 0. , 0. ])
>>> recall_score(y_true, y_pred, average=None, zero_division=1)
array([0.5, 1. , 1. ])
>>> # multilabel classification
>>> y_true = [[0, 0, 0], [1, 1, 1], [0, 1, 1]]
>>> y_pred = [[0, 0, 0], [1, 1, 1], [1, 1, 0]]
>>> recall_score(y_true, y_pred, average=None)
array([1. , 1. , 0.5])Accuracy、Precision、Recall和F1-score公式:


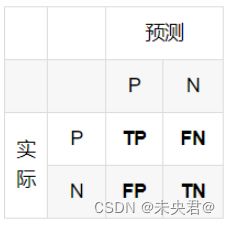
TP、FP、TN、FN的概念:
TP(True Positive):预测为正,预测结果是正确的
FP(False Positive):预测为正,预测结果是错误的
TN(True Negative):预测为负,预测结果是正确的
FN(False Negative):预测为负,预测结果是错误的