MXNet的Faster R-CNN(基于区域提议网络的实时目标检测)《1》
原论文:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
开源代码:https://github.com/ijkguo/mx-rcnn
Parallel Faster R-CNN implementation with MXNet,使用MXNet实现快速并行的区域提议的卷积神经网络,这里的框架就是用MXNet,如果没有安装这个框架的,具体安装可以查看:MXNet的安装以及一些常见错误处理
这节主要就是安装模型与测试看下这个模型的效果怎么样,以及安装过程遇到哪些问题。
克隆源码
我们先克隆一份源码到本地:
C:\Users\Tony>git clone https://github.com/ijkguo/mx-rcnn.git
当然如果网络不稳定,可能出现下面这样的错误:
fatal: unable to access 'https://github.com/ijkguo/mx-rcnn.git/': OpenSSL SSL_read: Connection was aborted, errno 10053
再试几次就好了,这个属于国内访问国外的站点,网络问题造成的。然后我们就在C:\Users\Tony目录克隆了一份mx-rcnn了。
VOC数据集
训练模型少不了数据集,这里我使用VOC的数据集,下载数据集地址:
http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
文件都是比较大,所以建议使用迅雷下载,下载好了之后解压。放入到data目录下面,我们来看下VOCdevkit\VOC2012里面都保存的是一些什么文件?
ImageSets\Segmentation :训练与验证的txt文本文件,里面内容是图片名,类似下面:
2007_000032
2007_000039
...
JPEGImages :样本的输入图片
如图:
SegmentationClass :标签,跟样本一样的图片格式,而且尺寸和它所标注的输入图像的尺寸相同。标签中颜色相同的像素属于同一个语义类别。
如图:

Annotations :标注,里面是xml文件,打开一个2007_000027.xml(人),可以看到里面有图片尺寸,人的姿势,坐标,头脚等的坐标属性。你可以打开其他的xml文件看看,是其他各种对象的名称和坐标信息等。对于Annotations标注文件,可以查阅:Python基础知识之读取XML文件 熟悉对XML文件里面的对象节点的读取。
VGG16预训练模型参数
下载vgg_voc07-0010.params参数文件,dropbox需要登录,没有账号先注册账号即可:https://www.dropbox.com/s/gfxnf1qzzc0lzw2/vgg_voc07-0010.params?dl=0
当然如果不想注册或者可能需要科学上网的话,那就直接点击这里下载:vgg-voc07-0010.params然后来做个测试,看下这个模型效果如何,我这里使用的是网络随便下载的一张狗猫图片hi.jpg:
python demo.py --dataset voc --network vgg16 --params model/vgg_voc07-0010.params --image hi.jpg
执行之后的结果:
called with args
{'dataset': 'voc',
'gpu': '',
'image': 'myimage.jpg',
'img_long_side': 1000,
'img_pixel_means': (123.68, 116.779, 103.939),
'img_pixel_stds': (1.0, 1.0, 1.0),
'img_short_side': 600,
'net_fixed_params': ['conv1', 'conv2'],
'network': 'vgg16',
'params': 'model/vgg_voc07-0010.params',
'rcnn_batch_size': 1,
'rcnn_bbox_stds': (0.1, 0.1, 0.2, 0.2),
'rcnn_conf_thresh': 0.001,
'rcnn_feat_stride': 16,
'rcnn_nms_thresh': 0.3,
'rcnn_num_classes': 21,
'rcnn_pooled_size': (7, 7),
'rpn_anchor_ratios': (0.5, 1, 2),
'rpn_anchor_scales': (8, 16, 32),
'rpn_feat_stride': 16,
'rpn_min_size': 16,
'rpn_nms_thresh': 0.7,
'rpn_post_nms_topk': 300,
'rpn_pre_nms_topk': 6000,
'vis': False,
'vis_thresh': 0.7}
cat 0.9973692893981934 [15.126463492392649, 175.17550730853654, 171.60225596158054, 453.5603692509072]
dog 0.9986190795898438 [214.57471593545327, 0.0, 473.58240774725783, 473.91646690260296]
可以看到这个识别率很高,也正确识别出了cat和dog。
另外再下载一张图片里面包含飞机和人的图片hi.png: 
(pygpu) C:\Users\Tony\mx-rcnn>python demo.py --dataset voc --network vgg16 --params model/vgg_voc07-0010.params --image hi.png
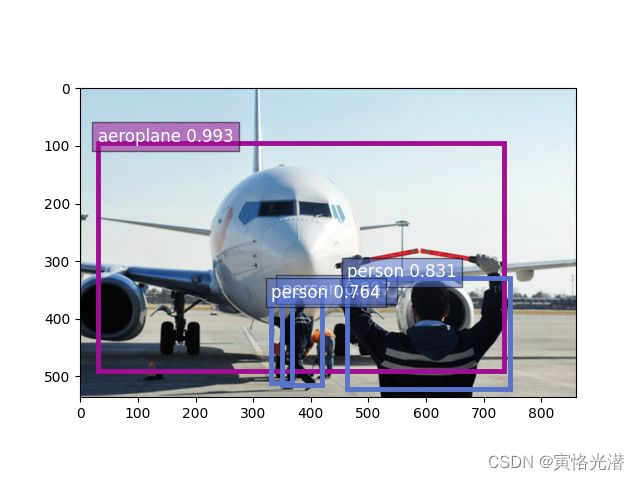
aeroplane 0.9932262301445007 [30.012542606770246, 94.47606422545638, 736.2043076034429, 490.1165506755796]
person 0.9973176121711731 [349.8960436870949, 360.76963968838686, 419.708646633156, 515.0064940880594]
person 0.8311970829963684 [463.2724951553385, 329.9512759694035, 746.2167398828122, 521.4361603167887]
person 0.7637878060340881 [331.2129511589329, 365.46689139662453, 367.05844125486556, 512.2362556924838]
也能准确的在图片中找出飞机和三个人,准确率也是很不错的
可视化效果
我们来可视化这两张图片,看下效果怎么样,增加一个vis参数
(pygpu) C:\Users\Tony\mx-rcnn>python demo.py --dataset voc --network vgg16 --params model/vgg_voc07-0010.params --image hi.jpg --vis
cat 0.9973692893981934 [15.126463492392649, 175.17550730853654, 171.60225596158054, 453.5603692509072]
dog 0.9986190795898438 [214.57471593545327, 0.0, 473.58240774725783, 473.91646690260296]
可以看到非常精准的锚框着对象,而且狗的识别率达到了99.9%

错误处理
如果没有安装opencv这个库的话,会报错,如下:
No module named 'cv2'
安装,最好带镜像地址,速度快:
pip install opencv-contrib-python -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
如果在安装过程中有遇到什么疑问的,可以留言交流。