Pytorch实现线性回归——Pytorch学习笔记一
Pytorch实现线性回归
本文所记录的内容是观看B站刘二大人的相关pytorch教学视频所做的笔记
视频链接:Pytorch深度学习实践
一、Python知识点
1.类的继承
类做继承时,在初始化时需要这样操作:
Module是父类,LinearModel类继承自该父类
class LinearModel(torch.nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
super(LinearModel, self).——init()——
super(LinearModel, self).init()首先找到LinearModel的父类(此处是类Module),然后把类LinearModel的对象self转换为类Module的对象,然后“被转换”的类Module对象调用自己的init函数,其实简单理解就是子类把父类的init()放到自己的init()当中,这样子类就有了父类的init()的那些东西。
再来看上面的代码,LinearModel类继承nn.Module,super(LinearModel, self).init()就是对继承自父类nn.Module的属性进行初始化,用nn.Module的初始化方法来初始化继承的属性。
class LinearModel(nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
# 输入图像channel:1;输出channel:6;5x5卷积核
self.conv1 = nn.Conv2d(1, 6, 5)
也就是说,子类继承了父类的所有属性和方法,父类属性自然会用父类方法来进行初始化。 当然,如果初始化的逻辑与父类的不同,不使用父类的方法,自己重新初始化也是可以的。比如:
class DiabetesDataset(Dataset):
def __init__(self, filepath):
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32)
#例如xy矩阵式Nx9的,那么其shape即为(N,9),所以shape[0]指取出N,得知总共的样本数量
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:, :-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
2.可调用的对象
这里的linear是Linear类实例化后的对象,但下方却可以直接调用该对象
self.linear = torch.nn.Linear(1, 1)#类的对象实例化
y_pred = linear(x)#该实例化的对象可以调用
实现这一点,需要在创建类时,做到如下,在定义类时要定义call函数,这样才能做到对象的直接调用:
class FooBar():
def __init__(self):
pass
def __call__(self, *args, **kwargs):
print("Hello" + str(args[0]))
foobar = FooBar()
foobar(1,2,3)
结果是:
Hello1
因为这里args是一个元组,元组的第0个元素是数字1
3.函数参数:*arg和**kwargs
此处补充关于函数定义时的参数*arg和**kwargs的解释:
def test(*args,**kwargs):
print(args)
print(kwargs)
test(1,2,3,x=5,y=6)
结果是:
(1, 2, 3)
{'x': 5, 'y': 6}
即args为所传进来的所有未命名的参数创建了一个元组,kwargs为传进来的所有命名过的变量创建一个词典,但要注意,传进来的参数必须要遵循未命名数字全部在前,命名变量全部在后,否将会报错。
二、Pytorch相关函数
1.torch.nn.Module类
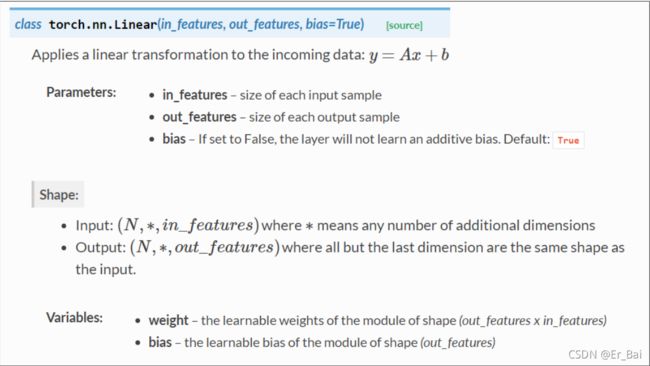
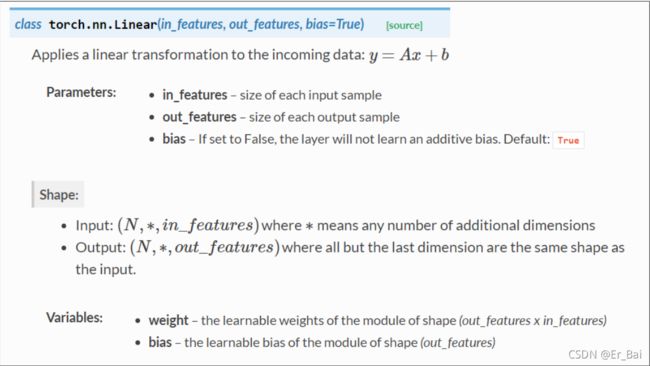
2.Linear()函数
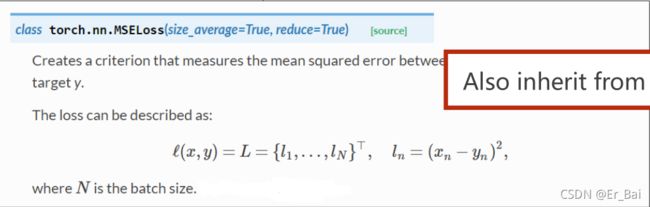
3.torch.nn.MSELoss()函数
4.torch.optim.SGD()函数

5.Module.parameters()函数
三、本节代码详解
1.创建数据集
首先是创建一个数据集,这里的数据集是Pytorch的Tensor建立的
#创建数据集
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[2.0], [4.0], [6.0]])
2.定义模型
模型的定义继承自Pytorch中的torch.nn(Neural Network)里面的Module类
"""模型必须继承自Module"""
class LinearModel(torch.nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
#构造一个对象,Linear里面分别是input_feature(输入样本的维度),output_feature,和bias(True默认 or False)
self.linear = torch.nn.Linear(1, 1)
def forward(self, x):
y_pred = self.linear(x)
return y_pred
#定义模型
model = LinearModel()
使用这个类创建一个线性模型,即Y=w*x+b,注意这里的这个实例化结果linear是可以回调的(callable),具体参见一、Python知识点
#构造一个对象,Linear里面分别是input_feature(输入样本的维度),output_feature,和bias(True默认 or False)
self.linear = torch.nn.Linear(1, 1)
这里使用了的Linear函数,本次线性回归所用到的样本,每一个样本的输入都是1维的,输出也是。
注意:
此处Linear()会自动的创建Tensor类型的weights和bias,并不需要考虑初始化赋值问题
3.定义损失函数和优化器
#构造损失函数
criterion = torch.nn.MSELoss(size_average=False)
这里借助了Pytorch中的相关模块构建了一个MSE损失的函数,size_average=False意味着多个损失求和后不平均化。
#构造优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
这里借助Pytorch中的相关模块构建了一个梯度下降优化模块,其中是model类继承自torch.nn.Module类,这里使用到的model.parameters()函数就是父类的函数,该函数的作用就是自动找到model类所有的成员,找到需要梯度下降优化的tensor,然后SGD自动的进行梯度下降优化。
4.模型训练
#训练模型
for epoch in range(1000):
#这里model会自动调用forward()函数,因为是model父类的特性
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
#所有梯度归零化
optimizer.zero_grad()
#反向传播求出梯度
loss.backward()
#更新权重和偏置值,即w和b
optimizer.step()
四、完整代码
"""
Pytorch实现线性回归,向量化
"""
import torch
import visdom
#创建数据集
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[2.0], [4.0], [6.0]])
"""模型必须继承自Module"""
class LinearModel(torch.nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
#构造一个对象,Linear里面分别是input_feature(输入样本的维度),output_feature,和bias(True默认 or False)
self.linear = torch.nn.Linear(1, 1)
def forward(self, x):
y_pred = self.linear(x)
return y_pred
#定义模型
model = LinearModel()
#构造损失函数
criterion = torch.nn.MSELoss(size_average=False)
#构造优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
vis = visdom.Visdom(env='main') # 设置环境窗口的名称,如果不设置名称就默认为main
opt = {
'xlabel': 'epochs',
'ylabel': 'loss_value',
'title': 'train_loss'
}
#定义一个图像窗口
loss_window = vis.line(
X=[0],
Y=[0],
opts=opt
)
#训练模型
for epoch in range(1000):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
#所有梯度归零化
optimizer.zero_grad()
#反向传播求出梯度
loss.backward()
#更新权重和偏置值,即w和b
optimizer.step()
#不断更新图像
vis.line(X=[epoch], Y=[loss.item()], win=loss_window, opts=opt, update='append')
print('w= ', model.linear.weight.item())
print('b= ', model.linear.bias.item())
x_test = torch.Tensor([4.0])
y_test = model(x_test)
print('y_pred= ', y_test.data.item())