初识人脸识别---人脸识别研究报告(概述篇)
不知道自己喜欢做什么,这对于一个可能打算成为程序员的程序员来说,可能是悲哀的。--------写在之前
经过有一段时间的思考,觉得自己有必要对那些几年来特别火的词语重新做个了解,人工智能,大数据,云计算,数据挖掘,计算机视觉,AR,VR等等等等,于是便有了以下文章的将要的可能的诞生(前提是笔者够勤劳)。
2018-11-23
首先需要了解两个概念:
计算机视觉是使用计算机及相关设备对生物视觉的一种模拟,主要任务就是通过对采集的图片或视频进行处理以获得相应场景的三维信息,就像人类和许多其他类生物每天所做的那样。(来自百度百科)
人脸识别是基于人的脸部特征信息进行身份识别的一种生物识别技术。用摄像机或摄像头采集含有人脸的图像或视频流,并自动在图像中检测和跟踪人脸,进而对检测到的人脸进行脸部识别的一系列相关技术,通常也叫做人像识别、面部识别。(来自百度百科)
人脸识别的优势:非侵扰性(无需特意)、便捷性(摄像头即可)、友好性(符合人类习惯)、非接触性、可拓展性(可应用的范围广)。这些特点大多是用来和指纹、虹膜一类的信息采集与识别技术进行比较。
发展历程:
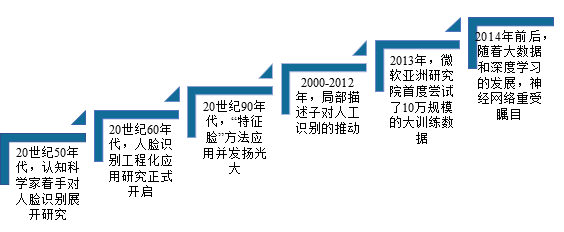
| 时期 | 20世纪50年代 | 20世纪90年代 | 20世纪50年代 | 2000-2012年 | 2013年 | 2014年 |
| 事件(技术) | 认知科学家就已着手对人脸识别展开研究 | 人脸识别工程化应用研究正式开启 | “特征脸”(Eigenface)方法应用并发扬光大 | 研究者的关注点开始从受限场景下的人脸识别转移到非受限环境下的人脸识别 | 微软亚洲研究院的研究者首度尝试了10万规模的大训练数据,并基于高维 LBP 特征和 Joint Bayesian 方法在 LFW 上获得了95.17%的精度 | 随着大数据和深度学习的发展,神经网络重受瞩目,并在图像分类、手写体识别、语音识别等应用中获得了远超经典方法的结果 |
| 优势 | 利用了人脸的几何结构,通过分析人脸器官特征点及其之间的拓扑关系进行辨识,简单直观 | 第一次将主成分分析和统计特征技术引入人脸识别,在实用效果上取得了长足的进步; Belhumer 成功将 Fisher 判别准则应用于人脸分类,提出了基于线性判别分析的 Fisherface 方法 |
相继探索出了基于遗传算法、支持向量机(SVM)、boosting、流形学习以及核方法等进行人脸识别; 稀疏表示(Sparse Representation)因为其优美的理论和对遮挡因素的鲁棒性成为当时的研究热点; 业界基本达成共识:基于人工精心设计的局部描述子进行特征提取和子空间方法进行特征选择能够取得最好的识别效果(Gabor 及 LBP 特征描述子是迄今为止在人脸识别领域最为成功的两种人工设计局部描述子); 对各种人脸识别影响因子的针对性处理也是那一阶段的研究热点,比如人脸光照归一化、人脸姿态校正、人脸超分辨以及遮挡处理等
|
大训练数据集对于有效提升非受限环境下的人脸识别很重要 | 香港中文大学的 Sun Yi 等人提出将卷积神经网络应用到人脸识别上,采用20万训练数据,在 LFW 上第一次得到超过人类水平的识别精度; 自此之后,研究者们不断改进网络结构,同时扩大训练样本规模,将 LFW 上的识别精度推到99.5%以上; 一个基本的趋势:训练数据规模越来越大,识别精度越来越高。 |
|
| 局限 | 一旦人脸姿态、表情发生变化,精度则严重下降 | 距离实用距离颇远(当时最好的识别系统尽管在受限的 FRGC 测试集上能取得99%以上的识别精度,但是在 LFW 上的最高精度仅仅在80%左右) | 然而,以上所有这些经典方法,都难以处理大规模数据集的训练场景 |
注释:
1.特征脸(Eigenface)是指用于机器视觉领域中的人脸识别问题的一组特征向量。使用特征脸进行人脸识别的方法首先由Sirovich and Kirby (1987)提出,并由Matthew Turk和Alex Pentland用于人脸分类。
一组特征脸可以通过在一大组描述不同人脸的图像上进行主成分分析(PCA)获得。任意一张人脸图像都可以被认为是这些标准脸的组合。例如,一张人脸图像可能是特征脸1的10%,加上特征脸2的55%,在减去特征脸3的3%。值得注意的是,它不需要太多的特征脸来获得大多数脸的近似组合。另外,由于人脸是通过一系列向量(每个特征脸一个比例值)而不是数字图像进行保存,可以节省很多存储空间。
https://baike.baidu.com/item/%E7%89%B9%E5%BE%81%E8%84%B8/15618441?fr=aladdin
2.主成分分析(Principal Component Analysis,PCA), 是一种统计方法。通过正交变换将一组可能存在相关性的变量转换为一组线性不相关的变量,转换后的这组变量叫主成分。
https://baike.baidu.com/item/主成分分析/829840?fr=aladdin
3.Fisherface所基于的LDA(Linear Discriminant Analysis,线性判别分析)理论和特征脸里用到的PCA有相似之处,都是对原有数据进行整体降维映射到低维空间的方法,LDA和PCA都是从数据整体入手而不同于LBP提取局部纹理特征
https://blog.csdn.net/smartempire/article/details/23377385
4.稀疏表示:用较少的基本信号的线性组合来表达大部分或者全部的原始信号。
其中,这些基本信号被称作原子,是从过完备字典中选出来的;而过完备字典则是由个数超过信号维数的原子聚集而来的。可见,任一信号在不同的原子组下有不同的稀疏表示。
假设我们用一个M*N的矩阵表示数据集X,每一行代表一个样本,每一列代表样本的一个属性,一般而言,该矩阵是稠密的,即大多数元素不为0。 稀疏表示的含义是,寻找一个系数矩阵A(K*N)以及一个字典矩阵B(M*K),使得B*A尽可能的还原X,且A尽可能的稀疏。A便是X的稀疏表示。
https://www.cnblogs.com/yifdu25/p/8128028.html
5.遗传算法:是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。遗传算法是从代表问题可能潜在的解集的一个种群(population)开始的,而一个种群则由经过基因(gene)编码的一定数目的个体(individual)组成。每个个体实际上是染色体(chromosome)带有特征的实体。染色体作为遗传物质的主要载体,即多个基因的集合,其内部表现(即基因型)是某种基因组合,它决定了个体的形状的外部表现,如黑头发的特征是由染色体中控制这一特征的某种基因组合决定的。因此,在一开始需要实现从表现型到基因型的映射即编码工作。由于仿照基因编码的工作很复杂,我们往往进行简化,如二进制编码,初代种群产生之后,按照适者生存和优胜劣汰的原理,逐代(generation)演化产生出越来越好的近似解,在每一代,根据问题域中个体的适应度(fitness)大小选择(selection)个体,并借助于自然遗传学的遗传算子(genetic operators)进行组合交叉(crossover)和变异(mutation),产生出代表新的解集的种群。这个过程将导致种群像自然进化一样的后生代种群比前代更加适应于环境,末代种群中的最优个体经过解码(decoding),可以作为问题近似最优解。
6.支持向量机:支持向量机将向量映射到一个更高维的空间里,在这个空间里建立有一个最大间隔超平面。在分开数据的超平面的两边建有两个互相平行的超平面。建立方向合适的分隔超平面使两个与之平行的超平面间的距离最大化。其假定为,平行超平面间的距离或差距越大,分类器的总误差越小。
https://baike.baidu.com/item/%E6%94%AF%E6%8C%81%E5%90%91%E9%87%8F%E6%9C%BA/9683835?fr=aladdin
https://cuijiahua.com/blog/2017/11/ml_8_svm_1.html(这个理解挺有意思的)
7.Boosting方式每次使用的是全部的样本,每轮训练改变样本的权重。下一轮训练的目标是找到一个函数f 来拟合上一轮的残差。当残差足够小或者达到设置的最大迭代次数则停止。Boosting会减小在上一轮训练正确的样本的权重,增大错误样本的权重。(对的残差小,错的残差大)
https://www.cnblogs.com/earendil/p/8872001.html
8.流形学习(基本看不懂)
流形: 流形(manifold)是一般几何对象的总称,包括各种维度的曲线与曲面等,和一般的降维分析一样,流形学习是把一组在高维空间中的数据在低维空间中重新表示。不同之处是,在流形学习中假设:所处理的数据采样与一个潜在的流形上,或者说对于这组数据存在一个潜在的流形。
流形上的点本身是没有坐标的,所以为了表示这些数据点,我们把流形放入到外围空间(ambient space),用外围空间上的坐标来表示流形上的点,例如三维空间 R^3 中球面是一个2维曲面,即球面上只有两个自由度,但我们一般采用外围空间R^3 空间中的坐标来表示这个球面。
流行学习可以概括为:在保持流形上点的某些几何性质特征的情况下,找出一组对应的内蕴坐标(intrinsic coordinate),将流形尽量好的展开在低维平面上,这种低维表示也叫内蕴特征(intrinsic feature),外围空间的维数叫观察维数,其表示叫自然坐标,在统计上称为observation。
https://blog.csdn.net/chenaiyanmie/article/details/80167649
9.核方法:
核方法kernel methods (KMs)是一类模式识别的算法。其目的是找出并学习一组数据中的相互的关系。用途较广的核方法有支持向量机、高斯过程等。核方法是解决非线性模式分析问题的一种有效途径,其核心思想是:首先,通过某种非线性映射将原始数据嵌入到合适的高维特征空间;然后,利用通用的线性学习器在这个新的空间中分析和处理模式。
https://baike.baidu.com/item/%E6%A0%B8%E6%96%B9%E6%B3%95/1683712?fr=aladdin
10.鲁棒性的英文是robustness,其实是稳健性或稳定性的意思,个人认为反映为稳定性更好,但大家都这么叫,可能是音译。
鲁棒性一般用来描述某个东西的稳定性,就是说在遇到某种干扰时,这个东西的性质能够比较稳定。
举个例子,比如统计里面的均值和中位数,均值很容易受到极端值的影响,如果数据里面有很大或很小的数值,均值会偏大或偏小。而中位数就稳定的多,即使数据里面有很大或很小的数值,中位数也不会发生很大变化。所以,中位数这个统计量便具有鲁棒性。
https://zhidao.baidu.com/question/14914172.html
12.LFW:LFW 是由美国马萨诸塞大学发布并维护的公开人脸数集,测试数据规模为万。
研究热点:
主要集中在人脸识别、特征提取、稀疏表示、图像分类、神经网络、目标检测、人脸图像、人脸检测、图像表示、计算机视觉、姿态估计、人脸确认等领域。
 Caption
Caption
相关会议:
- ICCV:IEEE International Conference on Computer Vision
- CVPR:IEEE Conference on Computer Vision and Pattern Recognition
- ECCV:European Conference on Computer Vision
- ACCV:Asian Conference on Computer Vision
- FG:IEEE International Conference on Automatic Face and Gesture Recognition
这一篇先大致这样,还会修改,囫囵吞枣而已。。