opencv(11):训练自己的opencv级联分类器
一 采集数据并制作正负样本数据集
1.1 录制视频
1.2 将单个视频截取为指定分辨率的图像
1.3 处理负样本视频
1.4 本次训练正负样本数量选择与图片重编号
二 利用matlab制作制作正样本标注框文件
三 开始训练opencv级联分类器
3.1 生成正样本文件pos.txt
3.1.1 对label.txt进行处理,
3.1.2 生成暂时性的pos.txt即pos_tmp.txt
3.1.3 合并pos_tmp.txt和label.txt,得到pos.txt
3.1.4 手动将pos.txt中小数改为整数
3.2 生成负样本文件neg.txt
3.3 生成样本文件
四 测试级联分类器及调参
4.1 pub_image功能包
4.2 利用级联分类器检测车辆
4.3 编译运行
4.4 github仓
@meng
一 采集数据并制作正负样本数据集
1.1 录制视频
录制的视频如下,包括正样本视频(车辆)、负样本视频(不包含车辆)。
利用自己手机或者相机等录制视频有一个好处是—原始的图像分辨率一致(视频的分辨率均为1920*1080),比从网上或一些数据集上找的数据要好一些(可能数据量不够全面,但简单学习应该是够用)


1.2 将单个视频截取为指定分辨率的图像
这里选择导出为分辨率640*360(原始分辨率1920*1080各缩小3倍)
用PotPlayer视频软件打开一个视频;将视频暂停,并将时间拖到视频开头
依次点击:PotPlayer—视频—图像截取—连续截图
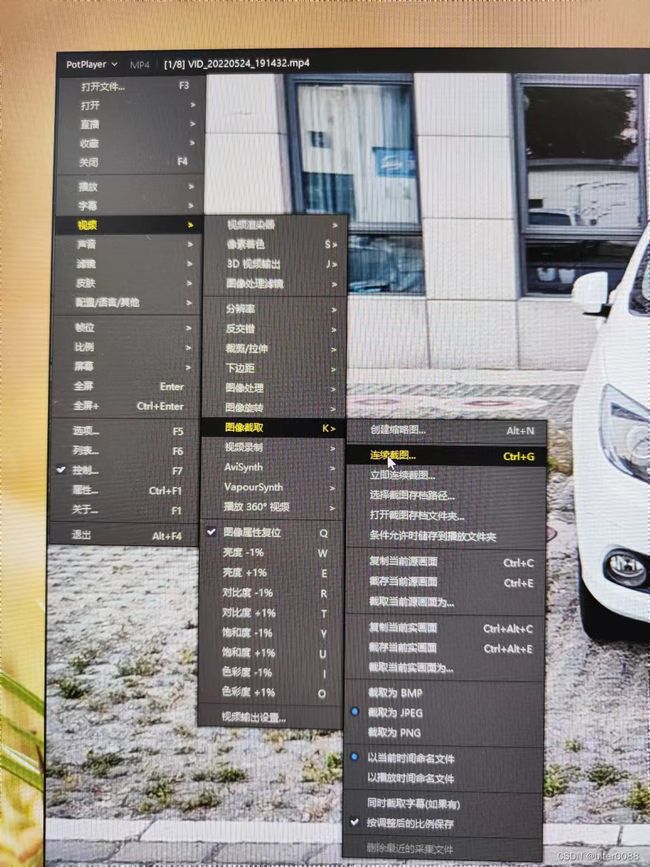
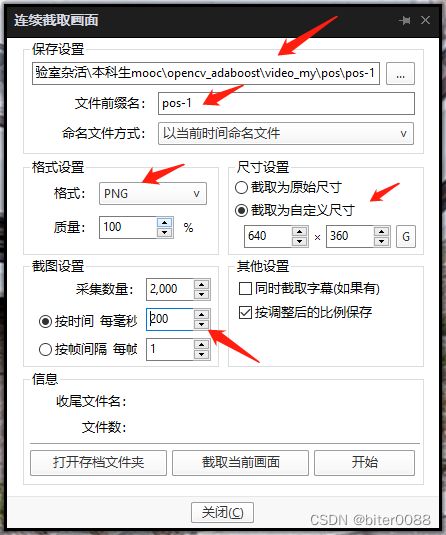
这里根据需要配置如下,注意箭头所指的地方,自己熟悉后可以根据需要进行更改;配置完成后,点击“开始”(此页面不要关闭!!!!!!!!)
直接点击播放,即可在指定的路径下生成当前视频的指定分辨率的图片
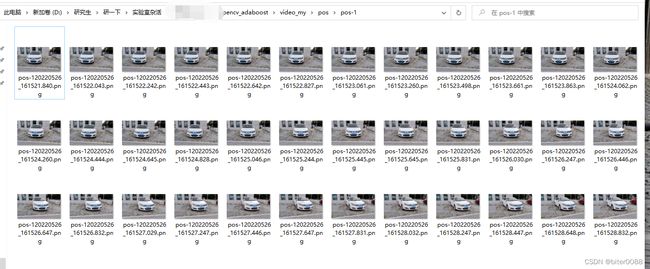
对其他正样本视频进行类似处理就好;总共得到293个正样本图片
1.3 处理负样本视频
为了保证负样本是正样本的3倍-5倍,需要截取比正样本多的图片,这里截取了1357个负样本图片
(这里就不放图了)
1.4 本次训练正负样本数量选择与图片重编号
注:图像重编号不是必要的,但是重编号后能够保证后面matlab生成的标注框顺序与图片顺序在各种排序(win10、ubuntu)下能够比较容易保持一致
从选择100张,负样本中选择300张;分别重新编号为pos-00001。。。pos-00100,放到pos文件夹下,neg-00001。。。neg-00300,放到neg文件夹下
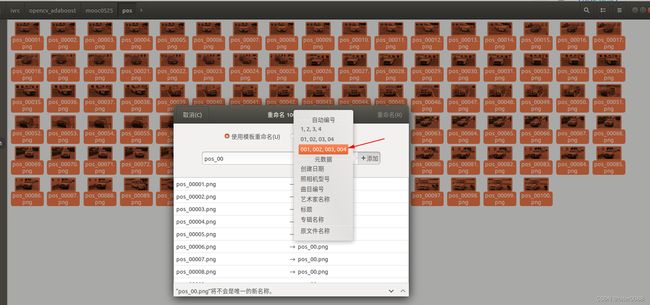
这里提供一种方法:使用ubuntu系统进行的重编号:图片目录下,依次全选、右键重命名、输入pos_00或输入neg_00,点击+号并选择”001,002,003,004”
二 利用matlab制作制作正样本标注框文件
打开matlab,依次APP--图像处理和计算机视觉--Image Labeler;会弹出Image Labeler窗口,效果如下:
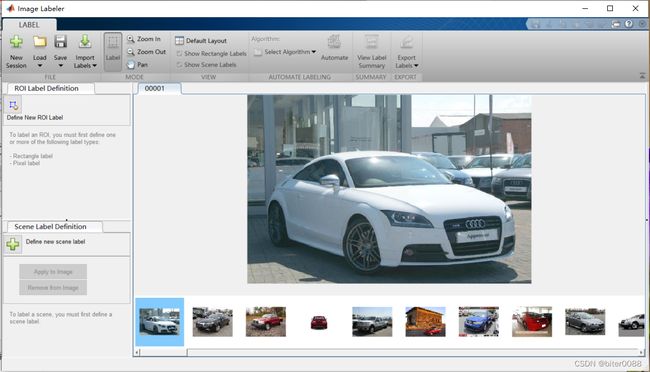
Image Labeler窗口内,点击Load—Add image from folder,到达正样本文件夹时,CTRL+A选中全部图片即可,如下:
创建car标签
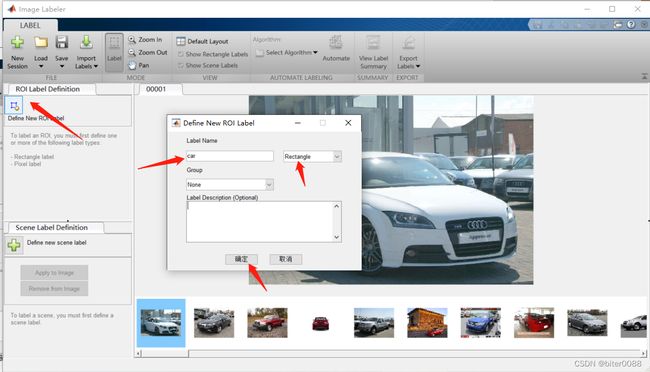
创建car标签后,会自动选中car标签(如果创建多个标签,需要先选中指定标签);然后将鼠标在图片中框选出car区域,即可完成一张图片的标注
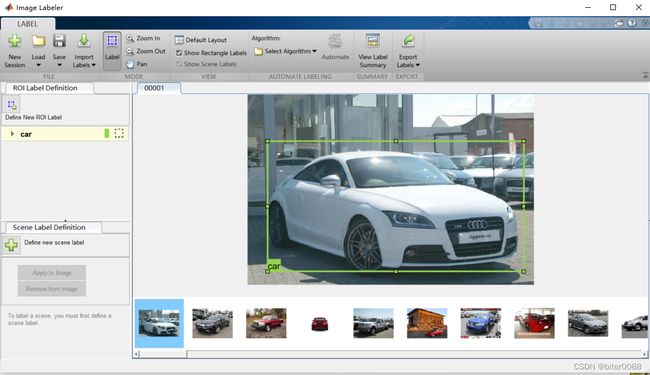
标注完所有图片后,选择导出到文件;
同时也选择导出到工作空间
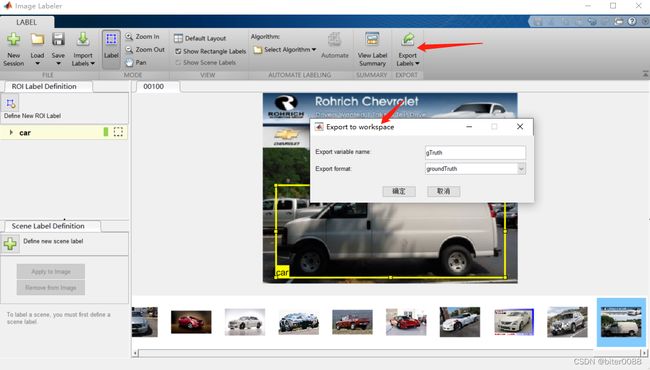
查看导出到工作空间的变量内容:

依次查看左边上下上下两个箭头所指的源图片目录和标签内容,可以看出导入到image labeler的图片是按照名称序号排序的;说明得到的标注框(下图右图)也是按照图片名称顺序排序的
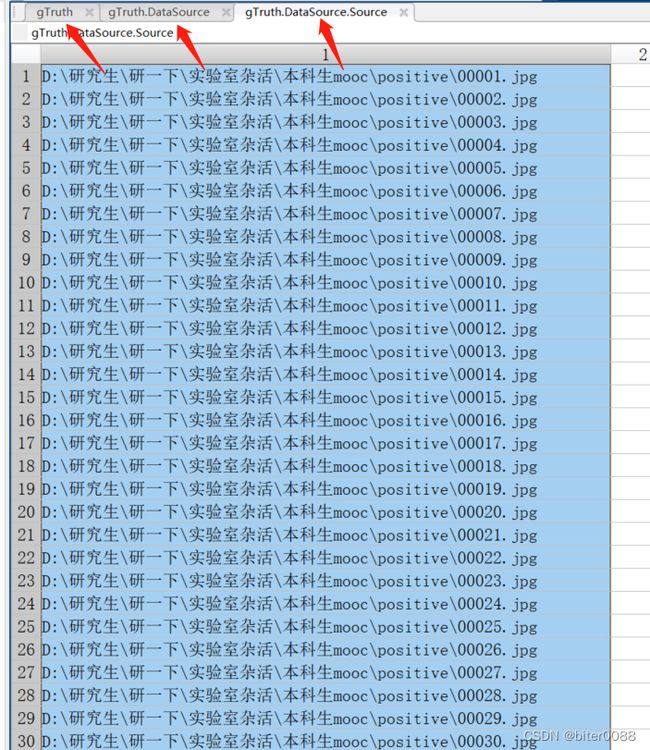
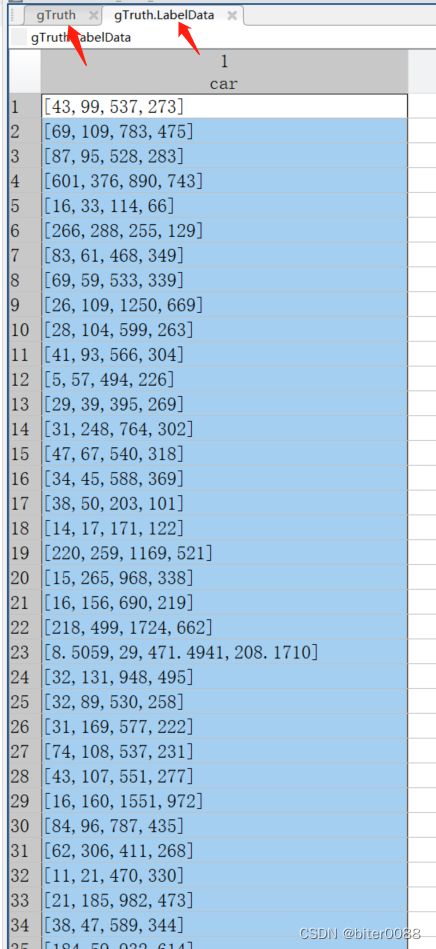
将标签内容另存为一个txt文件,取名为label.txt
三 开始训练opencv级联分类器
注:下面使用ubuntu系统进行操作,win10下面操作是类似的
下面这张图片是这节最终得到的文件目录,下面操作中有不清楚的可以看这张图片

3.1 生成正样本文件pos.txt
将文件夹名称分别取为pos(车辆),neg(非车辆)--前面改了这里就不用改了,并将两个文件夹里面非图片内容删除;将matlab生成的标签文件label.txt拿到外边来
3.1.1 对label.txt进行处理,
修改前如下:
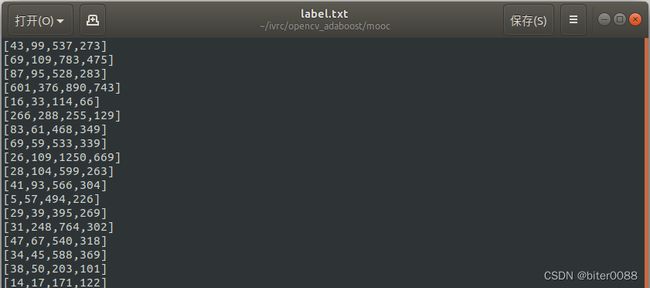
用空格代替“,”
#在当前目录,打开终端,输入:
sed -i 's/,/ /g' label.txt去除每行的第一个字符:
sed -i 's/^.//' label.txt去除右方框号
sed -i 's/]//' label.txt 
修改后结果如下:
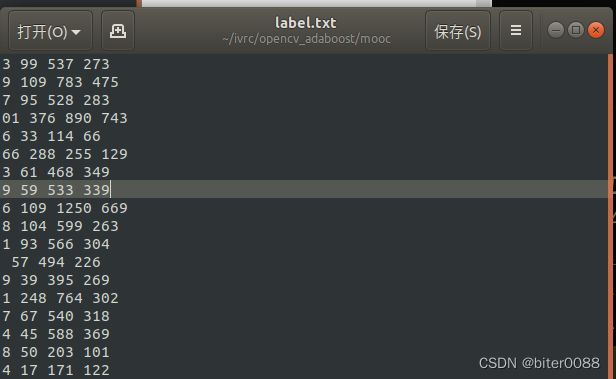
3.1.2 生成暂时性的pos.txt即pos_tmp.txt
#在当前目录下,打开终端,输入:
ls pos/*.*>pos_tmp.txt
在每行末尾加上“ 1 ”(空格1空格)
sed -i 's/$/ 1 /g' pos_tmp.txt 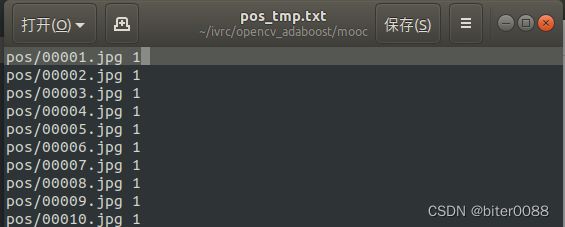
3.1.3 合并pos_tmp.txt和label.txt,得到pos.txt
运行逐行合并脚本:
python imerge2oneline.py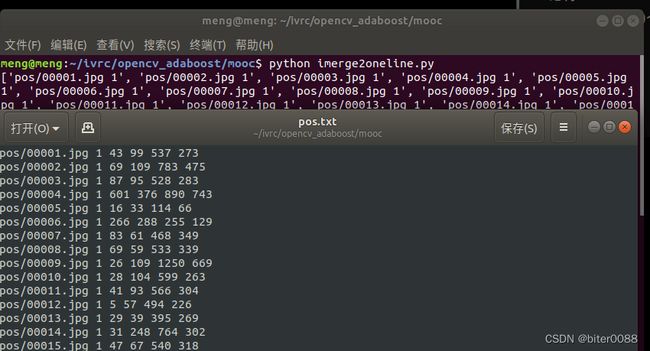
imerge2oneline.py:
# -*- coding:UTF-8 -*-
'''
https://zhidao.baidu.com/question/437546324704569644.html
先将两个文件分别读取到两个列表中,再用循环输出到第3个文件。
'''
f_ = open('pos_tmp.txt','r')
n=0
list1=[]
for i in f_.readlines():
n+=1
s=i.strip()
list1.append(s)
f_.close()
print list1
ff_ = open('label.txt','r')
m=0
list2=[]
for i in ff_.readlines():
m+=1
s=i.strip()
list2.append(s)
ff_.close()
print list2
fff_=open('pos.txt','w')
for i in range(n):
s=list1[i]+' '+list2[i]
fff_.write(s+'\n')
print(s)
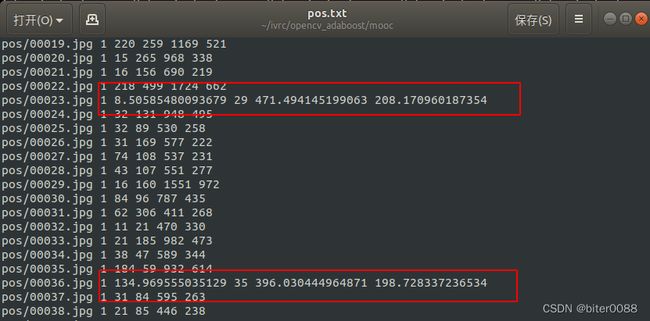
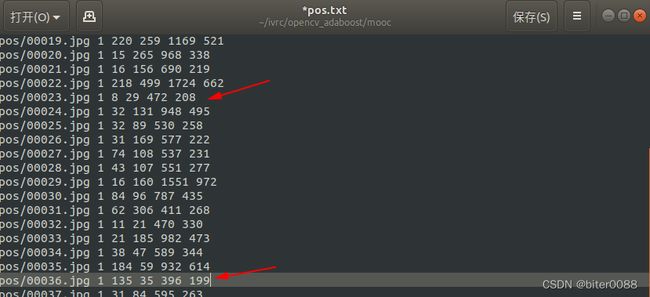
fff_.close() 3.1.4 手动将pos.txt中小数改为整数
修改原则为尽可能接近标注框或者略微大于标注框;这里修改得有些随意。。。
改前:
改后:
3.2 生成负样本文件neg.txt
ls neg/*.*>neg.txt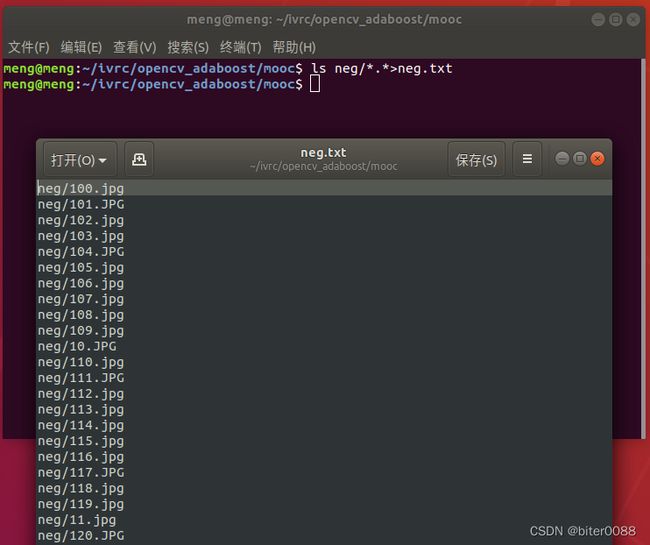
3.3 生成样本文件
将opencv目录下的可执行文件复制到当前目录来:
opencv_createsamples文件
opencv_traincascade文件
(注:对应win10为opencv_createsamples.exe文件、opencv_traincascade.exe文件; ubuntu系统如果安装了opencv,可以在计算机根目录“/”或者opencv源码编译目录下面搜索文件名,即可找到,复制到当前目录即可;这里opencv2.4.13、opencv3.2测试过,opencv4.x应该也可以执行下面的操作)

生成样本文件:
(正样本的分辨率为640*360,这里观察多张正样本图片中车辆大小,大概是1/3的长和宽,这里640/3余不尽,还没有测试1/4,这里选择了1/5)
./opencv_createsamples -vec pos.vec -info pos.txt -bg neg.txt -w 128 -h 72meng@meng:~/ivrc/opencv_adaboost/mooc0525$ ./opencv_createsamples -vec pos.vec -info pos.txt -bg neg.txt -w 128 -h 72
Info file name: pos.txt
Img file name: (NULL)
Vec file name: pos.vec
BG file name: neg.txt
Num: 1000
BG color: 0
BG threshold: 80
Invert: FALSE
Max intensity deviation: 40
Max x angle: 1.1
Max y angle: 1.1
Max z angle: 0.5
Show samples: FALSE
Width: 128
Height: 72
Max Scale: -1
Create training samples from images collection...
pos.txt(101) : parse errorDone. Created 100 samples
创建data文件夹
训练得到级联分类器文件
opencv_traincascade -data data -vec pos.vec -bg neg.txt -numPos 100 -numNeg 300 -numStages 10 -featureType LBP -w 128 -h 72 -minHitRate 0.995 -maxFalseAlarmRate 0.3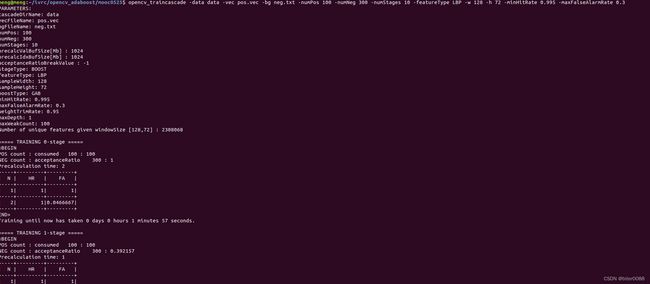
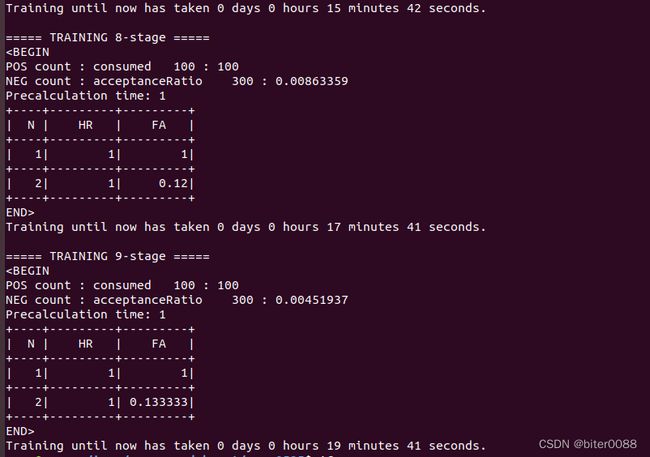
训练得到的级联分类器文件如下:

四 测试级联分类器及调参
下面使用两个功能包进行测试,一个是将图片发布为话题,另一个是利用级联分类器进行检测
4.1 pub_image功能包
主要代码如下:/camera_ws/src/pub_image/src/imwrite_1.cpp
#include
#include
#include "opencv2/highgui.hpp"
#include "opencv2/core.hpp"
#include "opencv2/imgproc.hpp"
#include //C++标准输入输出库
#include //opencv2标准头文件
#include //cv_bridge中包含CvBridge库
#include
using namespace std;
int main(int argc, char** argv)
{
ros::init(argc, argv, "image_publisher");
ros::NodeHandle nh;
image_transport::ImageTransport it(nh);
image_transport::Publisher pub = it.advertise("/usb_cam/image_raw", 1);
cv::Mat srcImage;
//加载图像
srcImage = cv::imread("/home/meng/ivrc/opencv_adaboost/camera_ws/src/pub_image/src/pos_030.png",1);
//std::cout << " rows " <<"\t"< 4.2 利用级联分类器检测车辆
主要文件为:/camera_ws/src/opencv_detect/scripts/book_detect.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import rospy
import cv2
# from std_msgs.msg import String
from sensor_msgs.msg import Image
from cv_bridge import CvBridge
def callback(imgmsg):
bridge=CvBridge()
img=bridge.imgmsg_to_cv2(imgmsg,"bgr8")
cv2.namedWindow("callback",cv2.WINDOW_NORMAL)
cv2.imshow("callback",img)
detect_book(img)
cv2.waitKey(10)
def detect_book(img_detect):
cascade_tidy=cv2.CascadeClassifier("/home/meng/ivrc/opencv_adaboost/mooc0525/data/cascade.xml")
cv2.namedWindow("camera",cv2.WINDOW_NORMAL)
gray=cv2.cvtColor(img_detect,cv2.COLOR_BGR2GRAY)
tidys=cascade_tidy.detectMultiScale(gray,1.25, 50) #这两个参数“1.25、50”可以调整
# 参数3:scaleFactor–表示在前后两次相继的扫描中,搜索窗口的比例系数。默认为1.1即每次搜索窗口依次扩大10%;
# 参数4:minNeighbors–表示构成检测目标的相邻矩形的最小个数(默认为3个)。
for (x,y,w,h) in tidys:
cv2.rectangle(img_detect,(x,y),(x+w,y+h),(0,255,0),2)
cv2.imshow("camera",img_detect)
cv2.waitKey(10)
def listener():
rospy.init_node('book_detect',anonymous=True)
rospy.Subscriber('/usb_cam/image_raw',Image,callback)
rospy.spin()
if __name__=='__main__':
listener()
4.3 编译运行
开启roscore:
roscore
另开一个终端:
catkin_make
source devel/setup.bash
rosrun pub_image pub_image_node
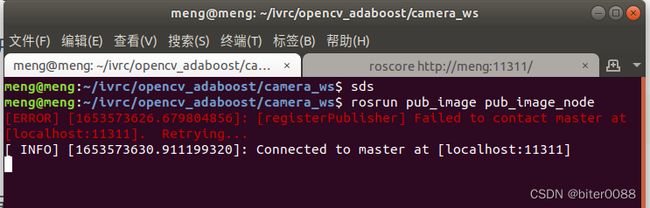
再另开一个终端:
source devel/setup.bash
rosrun opencv_detect book_detect.py
检测效果如下:

4.4 github仓
自己发的第一个github,欢迎学习交流
GitHub - menghxz/opencv-cascade-classifier-test