opencv的分类器制作方法
需要工具:
python,
opencv资源包(链接:https://pan.baidu.com/s/1YKWr_2zZYk944YKkjJh8LQ
提取码:t18c )
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
-
- 需要工具:
- 前言
- 一、收集需要识别的物体图片
- 二、运行程序
-
- 三、训练
- 四、最后一步
前言
由于比赛需要学习了一下分类器的使用方法,本文参考了很多博主的方法和资源,这里也会给出从各博主处获取的一些资源,感谢大佬们!
一、收集需要识别的物体图片
图片尽量拍的占屏比大一些
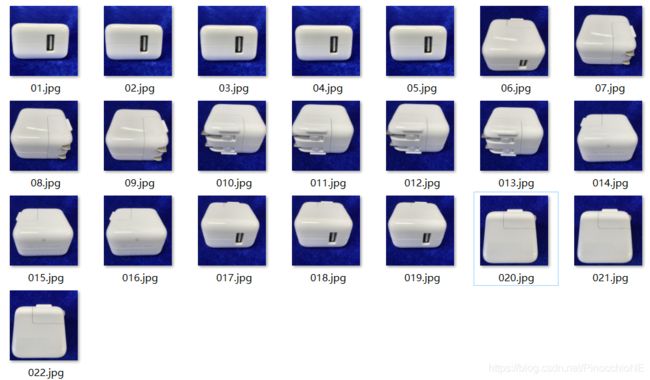
类似这样,然后拍摄物体的多个面并且要让物体和背景之间色差大一点,一共拍了22张
每张照片编好号码,我用的是wps批量重命名
二、运行程序
1.改变图片大小并灰度处理
import cv2
for i in range(1, 23): # 批量处理照片 //左开右闭,以图片数量为准
img = cv2.imread('pos6/'+'0' + str(i) + '.jpg', cv2.IMREAD_GRAYSCALE) # 读入照片,并转灰度
// pos6是工程的当前路径 ‘0’是因为图片名称第一位是0
img1 = cv2.resize(img, (40, 40)) # 调整大小
cv2.imwrite('pos/' + str(i) + '.jpg', img1) # 保存图片
print('批量转灰度成功!')
2.生成样本txt文件,只需要改第三行代码中的’pos’改成’pos’或’neg’
import os
def create_pos_n_neg():
for file_type in ['pos']: # 此处修改pos或neg即可生成正负样本的描述文件,pos是生成正样本描述文件info.txt
for img in os.listdir(file_type):
if (file_type == 'neg'):
line = file_type + '/' + img + '\n'
with open('bg.txt', 'a') as f:
f.write(line)
elif (file_type == 'pos'):
line = file_type + '/' + img + ' 1 0 0 40 40\n'
//1是编号,0 0是起始像素点,40 40是图片大小,要和程序1的大小一样
with open('info.txt', 'a') as f:
f.write(line)
if __name__ == '__main__':
create_pos_n_neg()
print('正样本描述文件info.txt已生成')
做好bg.txt(在最后一行改成bg.txt)后再做info.txt
负样本资源:(链接:https://pan.baidu.com/s/1omQyLDSn9Buo2jeG5SEJxg
提取码:acno )
三、训练
解压opencv后将第1个程创建的pos文件夹和第2个程序的info.txt和bg.txt文件复制到有opencv_createsamples.exe和opencv_traincascade.exe的文件夹内,并且创建data文件夹
代码如下(示例):
opencv_createsamples -info info.txt -num 30 -w 40 -h 40 -vec positives.vec
numPOS是正样本数量,且要小于实际数量,讲道理是样本越多越好,但是数据多了就会出现内存不足
opencv_traincascade.exe -data data -vec positives.vec -bg bg.txt -numPos 21 -numNeg 85 -numStages 10 -w 40 -h 40
成功后会在data文件夹中生成xml文件
四、最后一步
import cv2
import numpy as np
import math
alpha = 1.0 * math.pi / 180 # degree measured manually
v0 = 119.865631204 # from camera matrix
ay = 332.262498472 # from camera matrix
h1 = 5.5 # cm
h2 = 5.5
face_cascade = cv2.CascadeClassifier('cascade.xml')
face_cascade.load('F:/xml/cascade.xml')
cap = cv2.VideoCapture(0)
def calculate(v, h, x_shift, image):
# compute and return the distance from the target point to the camera
d = h / math.tan(alpha + math.atan((v - v0) / ay))
if d > 0:
cv2.putText(image, "%.1fcm" % d,
(image.shape[1] - x_shift, image.shape[0] - 20),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (255, 255, 255), 2)
return d
while True:
ret, img_new = cap.read()
gray_new = cv2.cvtColor(img_new, cv2.COLOR_BGR2GRAY) # hui du tu
# img = cv2.imread('C:/Users/10579/Desktop/03.jpg')
# img_new = cv2.imread('C:/Users/10579/Desktop/04.jpg')
gray = cv2.cvtColor(img_new,cv2.COLOR_BGR2GRAY) #hui du tu
faces = face_cascade.detectMultiScale(gray_new, 1.3, 5) # 分类器对象调用
for (x, y, w, h) in faces:
cv2.rectangle(img_new, (x, y), (x + w, y + h), (255, 255, 255), 2)
roi_gray = gray_new[y:y + h, x:x + w]
roi_color = img_new[y:y + h, x:x + w]
cv2.putText(img_new, 'chong dian qi', (x, y), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (128, 0, 128), 2)
"""
v_param1 = y + h - 5
if v_param1 > 0:
d1 = calculate(v_param1, h1, 300, img_new)
# d2 = calculate(v_param2, self.h2, 100, image)
d_stop_sign = d1
# d_light = d2
print(d1)
"""
# cv2.imshow('img',img)
cv2.imshow('img1', img_new)
if cv2.waitKey(1) & 0XFF == ord('q'): # 检测到按键q退出
cap.release()
cv2.destroyAllWindows()
break
#k = cv2.waitKey(30) & 0xff
#if k == 27:
#break
cap.relaese()
cv2.destroyAllWindows()
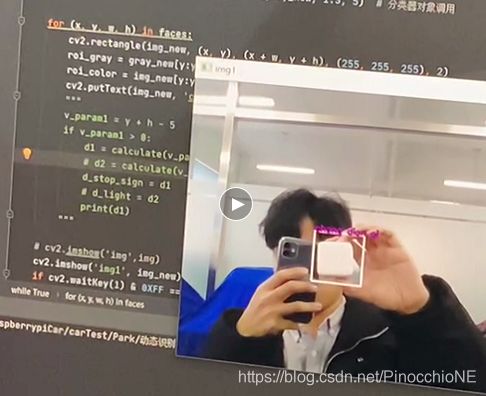
成功