二十三. 基于Soft NMS方法对物体检测网络YOLO v5进行性能改进
一. 现有YOLO v5网络的NMS情况
在我前面的博文: 十八.在JetsonNano上为基于PyTorch的物体检测网络测速和选型 一文中我综合各个物体检测网络的性能及在目标平台上的执行速度,为我的测试平台选择了基于PyTorch的YOLO v5物体检测网络. 该网络各项指标均已达到了一个较高水平,再通过调整网络结构本身去提高检测性能,难度越来越大. 于是我选择从物体检测的NMS细节上对该网络做进一步优化.
NMS(Non-Maximum Suppression)的详细概念及过程这里不再做阐述, 其基本思想是: 利用得分高的边框抑制得分低且重叠度(IoU)高的边框. 但基本的NMS虽然简单有效,可在某些特殊要求茶场景下,存在以下缺陷:
- 简单地过滤掉得分低且重叠度高的边框可能会导致漏检问题. 比如密集和拥挤情况下,容易漏检,降低召回率.
- NMS阈值无法确定: 如果阈值较低,则很容易将本属于两个物体的预测框抑制掉一个,造成漏检; 而阈值过高,很可能会在两个物体之间多了一个错误预测框,造成误检.
- 将得分作为衡量标准: 某些情况下,得分高的边框不一定位置更准,此衡量标准待考虑;
4. 执行速度: NMS的实现存在较多循环判断步骤, 擅长并行化处理的GPU执行效率不高.
手头的YOLO v5版本在模型输出边框信息(bboxes),分类置信度得分(scores)后,使用了PyTorch官方提供的NMS接口: torchvision.ops.nms(boxes, scores, iou_thres), 进行边框的过滤优选. 具体源文件为: torchvision.0.11.1\torchvision\csrc\ops\cuda\nms_kernel.cu 或 torchvision.0.11.1\torchvision\csrc\ops\cpu\nms_kernel.cu, 这是一个C++源文件,阅读其代码,可以看出其执行了一个基本的NMS过程. 存在基于NMS进行细节优化的空间.
因为我们的目标网络均在GPU上执行,所以我们仅考虑CUDA版本的各个NMS版本性能分析.
二. 官方版torchvision.ops.nms, 网络版基本NMS 和 自己编写的Soft NMS源码分析
1. PyTorch官方版torchvision.ops.nms接口:
其CUDA版本的源码在torchvision.0.11.1\torchvision\csrc\ops\cuda\nms_kernel.cu, 这里不再展示其源码.
优势: 官方正品,基于C++和cuda优化, 执行效率相当高.
2. 一个网络版基本NMS
这也是一个实现基本NMS功能的版本,其功能和官方torchvision.ops.nms接口完全一致. 之所以选用这个版本的NMS源码, 是因为其实现代码简洁优雅,技巧丰富. 此外,也是为了在执行效率和性能上做个横向对比.
其源码如下:
def base_nms(bboxes, scores, iou_thresh=0.5):
bboxes = bboxes.contiguous()
x1 = bboxes[:,0].contiguous()
y1 = bboxes[:,1].contiguous()
x2 = bboxes[:,2].contiguous()
y2 = bboxes[:,3].contiguous()
# 计算每个box的面积
areas = (x2-x1+1)*(y2-y1+1)
#对得分进行降序排列, oeder为降序排列后的索引
_, order = scores.sort(0, descending=True)
# NMS后,保存留下来的边框
keep = []
while order.numel() > 0:
if order.numel() == 1:
i = order.item()
keep.append(i)
break
else:
i = order[0].item() # 保留首个得分最大的边框
keep.append(i)
# 巧妙使用tersor.clamp()函数求取每一个边框,与当前框的最大值和最小值
xx1 = x1[order[1:]].clamp(min=x1[i])
yy1 = y1[order[1:]].clamp(min=y1[i])
xx2 = x2[order[1:]].clamp(max=x2[i])
yy2 = y2[order[1:]].clamp(max=y2[i])
# 求取每一个边框与当前边框的交集面积
inter = (xx2-xx1).clamp(min=0) * (yy2-yy1).clamp(min=0)
# 计算每一个框与当前框的IoU
iou = inter / (areas[i]+areas[order[1:]]-inter)
#保留IoU小于阈值的边框的索引
idx = (iou <= iou_thresh).nonzero().squeeze()
if idx.numel() == 0:
break
#这里+1,是为了补充idx与order之间的索引差
order = order[idx+1]
#返回保留下来的所有边框的索引值,类型torch.LongTensor
return torch.LongTensor(keep)3. 基于上述网络版基本NMS, 自己改编的Soft NMS版本
基本NMS的问题在于将和当前最高分边框的所有边框中,IoU大于阈值的边框,其得分直接置0,相当于丢弃掉, 结果会造成拥挤遮挡物体的漏检.
Soft NMS的基本思想: 对于上述Base NMS中IoU大于阈值的边框,不是直接将其得分值0,而是采用一定策略降低这些边框的得分.
一种合理的得分衰减方法是,连续的高斯置信度降低策略公式如下:
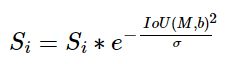
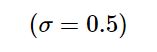
采用这种得分衰减方法, 对于某些得分很高的边框来说, 即使在NMS阶段被降分, 在后续的计算中,还有可能被作为正确的检测框机会. 理论上可以有效提升物体检测的精度和召回率.
我的Soft NMS源码如下, 此代码前半部分计算IoU值代码同上面基本NMS一致:
#score_threshold: 此阈值不同于前面分类置信度阈值
def my_soft_nms(bboxes, scores, iou_thresh=0.5,sigma=0.5,score_threshold=0.25):
bboxes = bboxes.contiguous()
x1 = bboxes[:,0]
y1 = bboxes[:,1]
x2 = bboxes[:,2]
y2 = bboxes[:,3]
# 计算每个box的面积
areas = (x2-x1+1)*(y2-y1+1)
#首先对所有得分进行一次降序排列,仅此一次,以提高后续查找最大值速度. oeder为降序排列后的索引
_, order = scores.sort(0, descending=True)
# NMS后,保存留下来的边框
keep = []
while order.numel() > 0:
if order.numel() == 1: # 仅剩最后一个box的索引
i = order.item()
keep.append(i)
break
else:
i = order[0].item() # 保留首个得分最大的边框box索引,i为scores中实际坐标
keep.append(i)
# 巧妙使用tersor.clamp()函数求取order中当前框[0]之外每一个边框,与当前框[0]的最大值和最小值
xx1 = x1[order[1:]].clamp(min=x1[i])
yy1 = y1[order[1:]].clamp(min=y1[i])
xx2 = x2[order[1:]].clamp(max=x2[i])
yy2 = y2[order[1:]].clamp(max=y2[i])
# 求取order中其他每一个边框与当前边框的交集面积
inter = (xx2-xx1).clamp(min=0) * (yy2-yy1).clamp(min=0)
# 计算order中其他每一个框与当前框的IoU
iou = inter / (areas[i]+areas[order[1:]]-inter) #共order.numel()-1个
idx = (iou > iou_thresh).nonzero().squeeze() #获取order中IoU大于阈值的其他边框的索引
if idx.numel() > 0:
iou = iou[idx]
newScores = torch.exp(-torch.pow(iou,2)/sigma) #计算边框的得分衰减
scores[order[idx+1]] *= newScores #更新那些IoU大于阈值的边框的得分
newOrder = (scores[order[1:]] > score_threshold).nonzero().squeeze()
if newOrder.numel() == 0:
break
else:
newScores = scores[order[newOrder+1]]
maxScoreIndex = torch.argmax(newScores)
if maxScoreIndex != 0:
newOrder[[0,maxScoreIndex],] = newOrder[[maxScoreIndex,0],]
#更新order.
order = order[newOrder+1]
#返回保留下来的所有边框的索引值,类型torch.LongTensor
return torch.LongTensor(keep)三. 官方版torchvision.ops.nms, 网络版NMS和自写Soft NMS性能分析
基于coco数据集做了一个简单的mAP测试, 参数如下:
分类置信度得分阈值: 0.001
IoU阈值: 0.5
Soft NMS 得分衰减再召回阈值: 0.25
我的一次测试结果如下:
| NMS版本 | NMS time | P | R | [email protected] | [email protected]:.95 |
| torchvision.ops.nms 基本NMS |
2.4ms | 0.646 | 0.576 | 0.617 | 0.405 |
| 网络版基本NMS | 140.8ms | 0.64 | 0.582 | 0.618 | 0.404 |
| 改进的Soft NMS | 13.9ms | 0.66 | 0.532 | 0.627 | 0.45 |
根据上表测试可知:
1>.确定了官方版torchvision.ops.nms接口,基于基本NMS思想实现. 且由于采用C++实现和cuda优化处理, 执行效率相当出色;
2>. 网络版基本NMS代码评估结果, 在P,R,mAP等指标上均与官方版torchvision.ops.nms结果基本一致, 但其执行耗时确实官方版的近70倍.
3>. 自己改进版Soft NMS代码评估结果, 在准确率P,[email protected],[email protected]:.95指标上均有明显的提升. 但在召回率R指标上却又明显下降, 分析其原因: 是因为Soft NMS更适合解决和减少较多密集和拥挤的场景下基本NMS造成的漏检. 对于一般的非拥挤和密集场景,Soft NMS不但不能发挥作用,甚至会增加小概率的误检.
综合上面结论. 我买了是否使用Soft NMS完全代替基本NMS,要根据实际的检测场景和使用基本NMS进行的实际效果来决定,如果是密集检测场景,基本过滤的结果存在很多的被遮挡目标的漏检,那么使用Soft NMS可以改善检测效果。如果是非密集的检测场景,基本NMS的检测效果是以误检为主,这时换成Soft NMS之后的效果未必会有提升。
同样参数下基本NMS和Soft NMS 实际效果对比(图片来于网络并做了面部模糊处理):


左图(基本 NMS), 右图(Soft NMS), 如右图, 同样参数下, Soft NMS在拥挤的人群中, 多识别出一个被前后两人挤在中间的人物标签,见右图黄色箭头处.
四. 基于Softer NMS改进方法
基本NMS和Soft NMS都是使用边框得分,即预测分类置信度作为衡量指标, 即假设得分越高,其位置越精准,但事实并不是如此. 因此, 位置置信度和分类置信度并不是强相关关系, 独立使用其中一个作为NMS的衡量标准的都不是最佳选择.
Softer NMS进一步改进了NMS方法, 在网络中新增加了一个定位置信度预测, 对于大于IoU阈值的边框的坐标进行了加权平均, 希望分类置信度得分高的边框能够利用周围边框的信息,从而提升其位置的准确度.
其过程涉及到为网络增加定位置信度预测分支, 需要重新训练网络. 以后有时间的话我会作为一个单独的话题来阐述.