机器学习笔记之波尔兹曼机(二)梯度求解(正相、负相均采用MCMC)
机器学习笔记之波尔兹曼机——基于MCMC的梯度求解
- 引言
-
- 回顾:波尔兹曼机
-
- 波尔兹曼机的结构表示
- 模型参数的对数似然梯度
- 基于MCMC梯度求解过程存在的问题
- 关于单个变量的后验概率
-
- 关于单个变量后验概率的推导过程
- 单个变量后验概率与受限玻尔兹曼机
引言
上一节介绍了波尔兹曼机,并对波尔兹曼机的对数似然梯度进行描述。本节将使用马尔可夫链蒙特卡洛方法对模型参数的梯度进行求解。
回顾:波尔兹曼机
波尔兹曼机的结构表示
这里讨论的含隐变量的波尔兹曼机。基于波尔兹曼机的概率图结构,可以将结点分成两个部分:
- 观测变量集合(Observed Variable) v v v:观测变量的特征是样本集合提供的,可观测的变量信息。
- 隐变量集合(Latent Variable) h h h:隐变量的特征是基于假定的概率图模型产生的特征。
无论是观测变量还是隐变量,在波尔兹曼机中均服从伯努利分布:
{ v = ( v 1 , v 2 , ⋯ , v D ) T ; v ∈ { 0 , 1 } D h = ( h 1 , h 2 , ⋯ , h P ) T ; h ∈ { 0 , 1 } P \begin{cases} v = (v_1,v_2,\cdots,v_{\mathcal D})^T;v \in \{0,1\}^{\mathcal D} \\ h = (h_1,h_2,\cdots,h_{\mathcal P})^T;h \in \{0,1\}^{\mathcal P} \end{cases} {v=(v1,v2,⋯,vD)T;v∈{0,1}Dh=(h1,h2,⋯,hP)T;h∈{0,1}P
其中 D , P \mathcal D,\mathcal P D,P分别表示观测变量,隐变量集合中随机变量的数量,那么基于玻尔兹曼机的约束条件,可以将概率密度函数(联合概率分布)表示如下:
P ( X ; θ ) = P ( v , h ; θ ) = { 1 Z exp { − E ( v , h ) } E ( v , h ) = − [ v T W ⋅ h + 1 2 v T L ⋅ v + 1 2 h T J ⋅ h ] \mathcal P(\mathcal X;\theta) = \mathcal P(v,h;\theta) = \begin{cases} \frac{1}{\mathcal Z} \exp \{ - \mathbb E(v,h)\} \\ \mathbb E(v,h) = - \left[v^T \mathcal W \cdot h + \frac{1}{2} v^T \mathcal L\cdot v + \frac{1}{2} h^T \mathcal J \cdot h\right] \end{cases} P(X;θ)=P(v,h;θ)={Z1exp{−E(v,h)}E(v,h)=−[vTW⋅h+21vTL⋅v+21hTJ⋅h]
其中模型参数 θ \theta θ由变量之间边的权重 W , L , J \mathcal W,\mathcal L,\mathcal J W,L,J共同构成。其中:
- W \mathcal W W表示观测变量、隐变量之间边的权重组成的矩阵,其中 W i j \mathcal W_{ij} Wij表示第 i i i个观测变量与第 j j j个隐变量之间关系的权重信息。
如果某观测变量与某隐变量之间不存在边相关联,那么对应的权重信息等于0.
W = [ W i j ] D × P = ( W 11 , W 12 , ⋯ , W 1 P W 21 , W 22 , ⋯ , W 2 P ⋮ W D 1 , W D 2 , ⋯ , W D P ) D × P \mathcal W = [\mathcal W_{ij}]_{\mathcal D \times \mathcal P} = \begin{pmatrix} \mathcal W_{11},\mathcal W_{12},\cdots,\mathcal W_{1 \mathcal P} \\ \mathcal W_{21},\mathcal W_{22},\cdots,\mathcal W_{2 \mathcal P} \\ \vdots\\ \mathcal W_{\mathcal D1},\mathcal W_{\mathcal D2},\cdots,\mathcal W_{\mathcal D \mathcal P} \\ \end{pmatrix}_{\mathcal D \times \mathcal P} W=[Wij]D×P= W11,W12,⋯,W1PW21,W22,⋯,W2P⋮WD1,WD2,⋯,WDP D×P - 同理, L , J \mathcal L,\mathcal J L,J分别表示观测变量、隐变量内部关系的权重信息。基于波尔兹曼机是一个无向图模型,因此对应的 L , J \mathcal L,\mathcal J L,J均是实对称矩阵,并且对角线上的元素均为0:
主对角线上元素表示各结点和自身的关联信息。基于波尔兹曼机的条件,模型中的结点不会与自身存在边相连接。
L = [ L i j ] D × D = ( L 11 = 0 , L 12 , ⋯ , L 1 D L 21 , L 22 = 0 , ⋯ , L 2 D ⋮ L D 1 , L D 2 , ⋯ , L D D = 0 ) D × D J = [ J i j ] P × P = ( J 11 = 0 , J 12 , ⋯ , J 1 P J 21 , J 22 = 0 , ⋯ , J 2 P ⋮ J P 1 , J P 2 , ⋯ , J P P = 0 ) P × P \mathcal L = [\mathcal L_{ij}]_{\mathcal D \times \mathcal D} = \begin{pmatrix} \mathcal L_{11} = 0,\mathcal L_{12},\cdots,\mathcal L_{1\mathcal D} \\ \mathcal L_{21},\mathcal L_{22} = 0,\cdots,\mathcal L_{2\mathcal D} \\ \vdots \\ \mathcal L_{\mathcal D1},\mathcal L_{\mathcal D2},\cdots,\mathcal L_{\mathcal D\mathcal D} = 0 \\ \end{pmatrix}_{\mathcal D \times \mathcal D} \\ \mathcal J = [\mathcal J_{ij}]_{\mathcal P \times \mathcal P} = \begin{pmatrix} \mathcal J_{11} = 0,\mathcal J_{12},\cdots,\mathcal J_{1\mathcal P} \\ \mathcal J_{21},\mathcal J_{22} = 0,\cdots,\mathcal J_{2\mathcal P} \\ \vdots \\ \mathcal J_{\mathcal P1},\mathcal J_{\mathcal P2},\cdots,\mathcal J_{\mathcal P\mathcal P} =0\\ \end{pmatrix}_{\mathcal P \times \mathcal P} L=[Lij]D×D= L11=0,L12,⋯,L1DL21,L22=0,⋯,L2D⋮LD1,LD2,⋯,LDD=0 D×DJ=[Jij]P×P= J11=0,J12,⋯,J1PJ21,J22=0,⋯,J2P⋮JP1,JP2,⋯,JPP=0 P×P
模型参数的对数似然梯度
对于波尔兹曼机的模型参数求解(学习任务)问题,由于波尔兹曼机模型结构的复杂性,因而没有办法求解模型参数的解析解。因此,通常使用极大似然估计,通过求解模型参数的对数似然梯度,从而使用梯度上升法来逼近模型参数的最优解。
已知样本集合 V = { v ( 1 ) , v ( 2 ) , ⋯ , v ( N ) } ; v ( i ) ∈ { 0 , 1 } D \mathcal V = \{v^{(1)},v^{(2)},\cdots,v^{(N)}\};v^{(i)} \in \{0,1\}^{\mathcal D} V={v(1),v(2),⋯,v(N)};v(i)∈{0,1}D。因此,似然函数 P ( V ; θ ) \mathcal P(\mathcal V;\theta) P(V;θ)可表示为如下形式:
P ( V ; θ ) = 1 N log ∏ i = 1 N P ( v ( i ) ; θ ) = 1 N ∑ i = 1 N log P ( v ( i ) ; θ ) θ = { W , L , J } \begin{aligned} \mathcal P(\mathcal V;\theta) & = \frac{1}{N} \log \prod_{i=1}^N \mathcal P(v^{(i)};\theta) \\ & = \frac{1}{N} \sum_{i=1}^N \log \mathcal P(v^{(i)};\theta) \quad \theta = \{\mathcal W,\mathcal L,\mathcal J\} \end{aligned} P(V;θ)=N1logi=1∏NP(v(i);θ)=N1i=1∑NlogP(v(i);θ)θ={W,L,J}
至此,需要对模型参数求解梯度。关于上述三个模型参数 W , L , J \mathcal W,\mathcal L,\mathcal J W,L,J的梯度分别表示如下:
从概率密度函数的表达可以看出,这里并没有将 1 2 \frac{1}{2} 21加上去。但并不影响 L , J \mathcal L,\mathcal J L,J的梯度方向,原因在于学习率 η \eta η同样需要设定,在设定的过程中已经将参数 1 2 \frac{1}{2} 21包含在内了。
∇ W [ log P ( v ( i ) ; θ ) ] = E P d a t a [ v ( i ) ( h ( i ) ) T ] − E P m o d e l [ v ( i ) ( h ( i ) ) T ] ∇ L [ log P ( v ( i ) ; θ ) ] = E P d a t a [ v ( i ) ( v ( i ) ) T ] − E P m o d e l [ v ( i ) ( v ( i ) ) T ] ∇ J [ log P ( v ( i ) ; θ ) ] = E P d a t a [ h ( i ) ( h ( i ) ) T ] − E P m o d e l [ h ( i ) ( h ( i ) ) T ] \begin{aligned} \nabla_{\mathcal W} \left[\log \mathcal P(v^{(i)};\theta)\right] = \mathbb E_{\mathcal P_{data}} \left[v^{(i)}(h^{(i)})^T\right] - \mathbb E_{\mathcal P_{model}} \left[v^{(i)}(h^{(i)})^T\right] \\ \nabla_{\mathcal L} \left[\log \mathcal P(v^{(i)};\theta)\right] = \mathbb E_{\mathcal P_{data}} \left[v^{(i)}(v^{(i)})^T\right] - \mathbb E_{\mathcal P_{model}}\left[v^{(i)}(v^{(i)})^T\right]\\ \nabla_{\mathcal J} \left[\log \mathcal P(v^{(i)};\theta)\right] = \mathbb E_{\mathcal P_{data}} \left[h^{(i)}(h^{(i)})^T\right] - \mathbb E_{\mathcal P_{model}} \left[h^{(i)}(h^{(i)})^T\right] \end{aligned} ∇W[logP(v(i);θ)]=EPdata[v(i)(h(i))T]−EPmodel[v(i)(h(i))T]∇L[logP(v(i);θ)]=EPdata[v(i)(v(i))T]−EPmodel[v(i)(v(i))T]∇J[logP(v(i);θ)]=EPdata[h(i)(h(i))T]−EPmodel[h(i)(h(i))T]
其中 P d a t a \mathcal P_{data} Pdata表示真实分布,该分布由两部分组成:
P d a t a ⇒ P d a t a ( v ( i ) ∈ V ) ⋅ P m o d e l [ h ( i ) ∣ v ( i ) ] \mathcal P_{data} \Rightarrow \mathcal P_{data}(v^{(i)} \in \mathcal V) \cdot \mathcal P_{model} \left[h^{(i)} \mid v^{(i)}\right] Pdata⇒Pdata(v(i)∈V)⋅Pmodel[h(i)∣v(i)]
其原因是:这里以模型参数 W \mathcal W W为例。
P ( h ( i ) ∣ v ( i ) ) \mathcal P(h^{(i)} \mid v^{(i)}) P(h(i)∣v(i))表示隐变量的后验概率,而隐变量仅存在于假定模型中,因而 P ( h ( i ) ∣ v ( i ) ) \mathcal P(h^{(i)} \mid v^{(i)}) P(h(i)∣v(i))是模型的分布,记作 P m o d e l [ h ( i ) ∣ v ( i ) ] \mathcal P_{model} \left[h^{(i)} \mid v^{(i)}\right] Pmodel[h(i)∣v(i)].
E P d a t a [ v ( i ) ( h ( i ) ) T ] ≈ E P d a t a ( v ( i ) ∈ V ) { E P ( h ( i ) ∣ v ( i ) ) [ v ( i ) ( h ( i ) ) T ] } \mathbb E_{\mathcal P_{data}} \left[v^{(i)}(h^{(i)})^T \right] \approx \mathbb E_{\mathcal P_{data}(v^{(i)} \in \mathcal V)} \left\{\mathbb E_{\mathcal P(h^{(i)} \mid v^{(i)})} \left[v^{(i)}(h^{(i)})^T\right]\right\} EPdata[v(i)(h(i))T]≈EPdata(v(i)∈V){EP(h(i)∣v(i))[v(i)(h(i))T]}
而 P m o d e l \mathcal P_{model} Pmodel表示假定模型的概率分布,它的概率分布具体是联合概率分布:
P m o d e l ⇒ P m o d e l ( h ( i ) , v ( i ) ) \mathcal P_{model} \Rightarrow \mathcal P_{model}(h^{(i)},v^{(i)}) Pmodel⇒Pmodel(h(i),v(i))
基于MCMC梯度求解过程存在的问题
此时,各个模型参数的对数似然梯度已经表示出来,可以使用梯度上升法去近似求解最优模型参数:
这里以模型参数 W \mathcal W W为例。
W ( t + 1 ) ⇐ W ( t ) + η ∇ W [ log P ( v ( i ) ; θ ) ] ⇐ W ( t ) + η { E P d a t a [ v ( i ) ( h ( i ) ) T ] − E P m o d e l [ v ( i ) ( h ( i ) ) T ] } \begin{aligned} \mathcal W^{(t+1)} & \Leftarrow \mathcal W^{(t)} + \eta \nabla_{\mathcal W} \left[\log \mathcal P(v^{(i)};\theta)\right] \\ & \Leftarrow \mathcal W^{(t)} + \eta \left\{\mathbb E_{\mathcal P_{data}} \left[v^{(i)}(h^{(i)})^T\right] - \mathbb E_{\mathcal P_{model}} \left[v^{(i)}(h^{(i)})^T\right]\right\} \end{aligned} W(t+1)⇐W(t)+η∇W[logP(v(i);θ)]⇐W(t)+η{EPdata[v(i)(h(i))T]−EPmodel[v(i)(h(i))T]}
并且模型参数的梯度 ∇ W [ log P ( v ( i ) ; θ ) ] \nabla_{\mathcal W} \left[\log \mathcal P(v^{(i)};\theta)\right] ∇W[logP(v(i);θ)]本身也是一个矩阵形式:
需要注意:上标中的 ( i ) (i) (i)表示某一具体样本;下标中的 i i i表示其中一个观测变量。例如 v i ( i ) v_i^{(i)} vi(i)表示具体样本 v ( i ) v^{(i)} v(i)的第 i i i个观测变量。
∇ W [ log P ( v ( i ) ; θ ) ] = { ∇ W i j [ log P ( v ( i ) ; θ ) ] } D × P ∇ W i j [ log P ( v ( i ) ; θ ) ] = E P d a t a [ v i ( i ) ( h j ( i ) ) T ] − E P m o d e l [ v i ( i ) ( h j ( i ) ) T ] \begin{aligned} \nabla_{\mathcal W} \left[\log \mathcal P(v^{(i)};\theta)\right] = \left\{\nabla_{\mathcal W_{ij}} \left[\log \mathcal P(v^{(i)};\theta)\right]\right\}_{\mathcal D \times \mathcal P} \\ \nabla_{\mathcal W_{ij}} \left[\log \mathcal P(v^{(i)};\theta)\right] = \mathbb E_{\mathcal P_{data}} \left[v_i^{(i)}(h_j^{(i)})^T\right] - \mathbb E_{\mathcal P_{model}}\left[v_i^{(i)}(h_j^{(i)})^T\right] \end{aligned} ∇W[logP(v(i);θ)]={∇Wij[logP(v(i);θ)]}D×P∇Wij[logP(v(i);θ)]=EPdata[vi(i)(hj(i))T]−EPmodel[vi(i)(hj(i))T]
对应图像如下, ∇ W i j [ log P ( v ( i ) ; θ ) ] \nabla_{\mathcal W_{ij}} \left[\log \mathcal P(v^{(i)};\theta)\right] ∇Wij[logP(v(i);θ)]描述的是红色线权重对应的梯度方向。
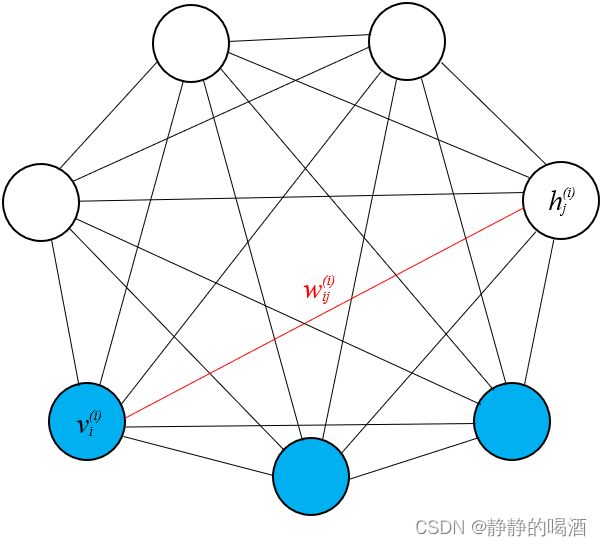
在配分函数——随机最大似然中介绍过,称 E P d a t a [ v i ( i ) ( h j ( i ) ) T ] \mathbb E_{\mathcal P_{data}} \left[v_i^{(i)}(h_j^{(i)})^T\right] EPdata[vi(i)(hj(i))T]为正相(Positive Phase),称 E P m o d e l [ v i ( i ) ( h j ( i ) ) T ] \mathbb E_{\mathcal P_{model}} \left[v_i^{(i)}(h_j^{(i)})^T\right] EPmodel[vi(i)(hj(i))T]为负相(Negative Phase)。
但是波尔兹曼机中对于模型参数梯度的正相的特殊之处在于: v i ( i ) ( h j ( i ) ) T v_i^{(i)}(h_j^{(i)})^T vi(i)(hj(i))T中的 v i ( i ) v_i^{(i)} vi(i)来自于真实样本分布 P d a t a ( v ( i ) ∈ V ) \mathcal P_{data}(v^{(i)} \in \mathcal V) Pdata(v(i)∈V);而 h j ( i ) h_j^{(i)} hj(i)来自于隐变量的后验分布 P m o d e l ( h ( i ) ∣ v ( i ) ) \mathcal P_{model}(h^{(i)} \mid v^{(i)}) Pmodel(h(i)∣v(i))。
关于负相基于的分布是关于隐变量、观测变量的联合概率分布 P m o d e l ( h ( i ) , v ( i ) ) \mathcal P_{model}(h^{(i)},v^{(i)}) Pmodel(h(i),v(i))。
个人理解:
在上述的推导过程中,关于隐变量只能依赖于概率图模型的假设,使得隐变量不会凭空出现。基于步骤1的描述,只要概率分布中含h ( i ) h^{(i)} h(i),无论是条件概率还是联合概率分布,都不可能是‘真实分布’P d a t a \mathcal P_{data} Pdata。因为真实分布只能观察到‘观测变量’的信息。例如正相中的P d a t a ( v ( i ) ∈ V ) \mathcal P_{data}(v^{(i)} \in \mathcal V) Pdata(v(i)∈V);正相、负相均包含的P m o d e l ( h ( i ) ∣ v ( i ) ) , P m o d e l ( h ( i ) , v ( i ) ) \mathcal P_{model}(h^{(i)} \mid v^{(i)}),\mathcal P_{model}(h^{(i)},v^{(i)}) Pmodel(h(i)∣v(i)),Pmodel(h(i),v(i)).
回顾受限玻尔兹曼机中对观测变量、隐变量之间关系的约束,可以直接将后验概率 P ( h ∣ v ) \mathcal P(h \mid v) P(h∣v)求解出来:
P ( h ( i ) ∣ v ( i ) ) = ∏ j = 1 P P ( h j ( i ) ∣ v ( i ) ) P ( h j ( i ) ∣ v ( i ) ) = { Sigmoid ( ∑ i = 1 D W j i ( i ) v i ( i ) + c j ( i ) ) h j ( i ) = 1 1 − Sigmoid ( ∑ i = 1 D W j i ( i ) v i ( i ) + c j ( i ) ) h j ( i ) = 0 \begin{aligned} \mathcal P(h^{(i)} \mid v^{(i)}) & = \prod_{j=1}^{\mathcal P} \mathcal P(h_j^{(i)} \mid v^{(i)}) \\ \mathcal P(h_j^{(i)} \mid v^{(i)}) & = \begin{cases} \text{Sigmoid} \left(\sum_{i=1}^{\mathcal D} \mathcal W_{ji}^{(i)}v_i^{(i)} + c_j^{(i)}\right) \quad h_j^{(i)} = 1 \\ 1 - \text{Sigmoid} \left(\sum_{i=1}^{\mathcal D} \mathcal W_{ji}^{(i)}v_i^{(i)} + c_j^{(i)}\right) \quad h_j^{(i)} = 0 \\ \end{cases} \end{aligned} P(h(i)∣v(i))P(hj(i)∣v(i))=j=1∏PP(hj(i)∣v(i))=⎩ ⎨ ⎧Sigmoid(∑i=1DWji(i)vi(i)+cj(i))hj(i)=11−Sigmoid(∑i=1DWji(i)vi(i)+cj(i))hj(i)=0
此时的后验概率 P m o d e l ( h ( i ) ∣ v ( i ) ) \mathcal P_{model}(h^{(i)} \mid v^{(i)}) Pmodel(h(i)∣v(i))可以直接使用观测变量进行表示,而 P d a t a ( v ( i ) ∈ V ) \mathcal P_{data}(v^{(i)} \in \mathcal V) Pdata(v(i)∈V)是基于样本集合 V \mathcal V V产生的,因此关于受限波尔兹曼机的正相是可表示的。
但关于受限波尔兹曼机的负相部分,没有办法对联合概率分布直接进行求解,在受限波尔兹曼机——对数似然梯度求解过程中针对负相的积分问题,采用的是块吉布斯采样方法进行近似求解。由于受限波尔兹曼机中各隐变量之间相互独立,不需要传统采样方式中先固定除采样外的其他所有变量,再对该变量进行采样的方式,而是隐变量之间各采各的,互不影响。
为了增加采样效率,同样使用了对比散度的方式进行优化。
但如果将受限波尔兹曼机泛化至波尔兹曼机,此时由于没有隐变量/观测变量相互独立的约束,对于 P m o d e l ( h ( i ) ∣ v ( i ) ) \mathcal P_{model}(h^{(i)} \mid v^{(i)}) Pmodel(h(i)∣v(i))同样没有办法进行求解。至此,无论是正相还是负相,波尔兹曼机都是极难直接求解的。
在当时给出的做法就是马尔可夫链蒙特卡洛方法(Markov Chain Monte Carlo,MCMC),但是这种方式自然是非常棘手的。例如吉布斯采样,随着随机变量数量的增长,它的计算量是指数级别的增加。对于过多的随机变量,它的分布近似过程是十分复杂的。
例如,想要使用MCMC方法近似求解 P m o d e l ( h ( i ) ∣ v ( i ) ) \mathcal P_{model}(h^{(i)} \mid v^{(i)}) Pmodel(h(i)∣v(i)),以上述的全连接波尔兹曼机为例,蓝色点给定的条件下,求解某一白色点的后验概率。这明显是不可求的——因为隐变量不仅仅和观测变量相关联,隐变量自身之间也存在关联,并且作为条件的观测变量之间也存在关联。如果使用因子图的方式对该模型进行分解——很遗憾,该概率图本身就是一个极大团,没有继续向下分解的可能。因而没有办法表示隐变量,并基于隐变量进行采样。
关于单个变量的后验概率
基于上面的介绍,可以知道:仅将观测变量作为条件,求解隐变量的后验概率 P m o d e l ( h ( i ) ∣ v ( i ) ) \mathcal P_{model}(h^{(i)} \mid v^{(i)}) Pmodel(h(i)∣v(i))是基本不可能的。
能否退而求其次,通过单个变量(观测变量、隐变量)的后验概率去描述 P m o d e l ( h ( i ) ∣ v ( i ) ) , P m o d e l ( v ( i ) , h ( i ) ) \mathcal P_{model}(h^{(i)} \mid v^{(i)}),\mathcal P_{model}(v^{(i)},h^{(i)}) Pmodel(h(i)∣v(i)),Pmodel(v(i),h(i))呢?
这里单个变量的后验存在两种类型:
需要强调的点:无论 P ( v i ( i ) = 1 ∣ h ( i ) , v − i ( i ) ) \mathcal P(v_i^{(i)} = 1 \mid h^{(i)},v_{-i}^{(i)}) P(vi(i)=1∣h(i),v−i(i))还是 P ( h j ( i ) = 1 ∣ v ( i ) , h − j ( i ) ) \mathcal P(h_j^{(i)} = 1 \mid v^{(i)},h_{-j}^{(i)}) P(hj(i)=1∣v(i),h−j(i)),它们均只是某一个随机变量的后验概率,而不是隐变量/观测变量的后验概率。
- 某观测变量 v i ( i ) v_i^{(i)} vi(i)的后验概率;
P ( v i ( i ) = 1 ∣ h ( i ) , v − i ( i ) ) = P ( v i ( i ) = 1 ∣ h 1 ( i ) , ⋯ , h P ( i ) , v 1 ( i ) , ⋯ , v i − 1 ( i ) , v i + 1 ( i ) , ⋯ , v D ( i ) ) \begin{aligned} \mathcal P(v_i^{(i)} = 1 \mid h^{(i)},v_{-i}^{(i)}) = \mathcal P(v_i^{(i)} = 1 \mid h_1^{(i)},\cdots,h_{\mathcal P}^{(i)},v_1^{(i)},\cdots,v_{i-1}^{(i)},v_{i+1}^{(i)},\cdots,v_{\mathcal D}^{(i)}) \end{aligned} P(vi(i)=1∣h(i),v−i(i))=P(vi(i)=1∣h1(i),⋯,hP(i),v1(i),⋯,vi−1(i),vi+1(i),⋯,vD(i)) - 某隐变量 h j ( i ) h_j^{(i)} hj(i)的后验概率;
P ( h j ( i ) = 1 ∣ v ( i ) , h − j ( i ) ) = P ( h j ( i ) = 1 ∣ v 1 ( i ) , ⋯ , v D ( i ) , h 1 ( i ) , ⋯ , h j − 1 ( i ) , h j + 1 ( i ) , ⋯ , h P ( i ) ) \mathcal P(h_j^{(i)} = 1 \mid v^{(i)},h_{-j}^{(i)}) = \mathcal P(h_j^{(i)} = 1 \mid v_1^{(i)},\cdots,v_{\mathcal D}^{(i)},h_1^{(i)},\cdots,h_{j-1}^{(i)},h_{j+1}^{(i)},\cdots,h_{\mathcal P}^{(i)}) P(hj(i)=1∣v(i),h−j(i))=P(hj(i)=1∣v1(i),⋯,vD(i),h1(i),⋯,hj−1(i),hj+1(i),⋯,hP(i))
这种表示方式给MCMC提供了有效的操作空间,例如吉布斯采样。假设对 v i ( i ) v_i^{(i)} vi(i)进行采样的过程中,可以固定除 v i ( i ) v_i^{(i)} vi(i)之外的所有随机变量。当 v i ( i ) v_i^{(i)} vi(i)采样结束之后,再继续选择其他随机变量如 v i + 1 ( i ) v_{i+1}^{(i)} vi+1(i),再次执行上述操作。直到所有随机变量全部采样过,一次迭代才算结束,继续进行下一次迭代。最终达到平稳分布。
关于吉布斯采样,详见吉布斯采样——传送门
关于单个变量后验概率的推导过程
P ( v i ( i ) ∣ h ( i ) , v − i ( i ) ) \mathcal P(v_i^{(i)} \mid h^{(i)},v_{-i}^{(i)}) P(vi(i)∣h(i),v−i(i)) 为例,描述它的推导过程。观察基于玻尔兹曼机条件下,该后验能够表示成什么形式:
- 使用条件概率公式,将 P ( v i ( i ) ∣ h ( i ) , v − i ( i ) ) \mathcal P(v_i^{(i)} \mid h^{(i)},v_{-i}^{(i)}) P(vi(i)∣h(i),v−i(i))表示为如下形式:
P ( v i ( i ) ∣ h ( i ) , v − i ( i ) ) = P ( h ( i ) , v i ( i ) , v − i ( i ) ) P ( h ( i ) , v − i ( i ) ) = P ( h ( i ) , v ( i ) ) P ( h ( i ) , v − i ( i ) ) \mathcal P(v_i^{(i)} \mid h^{(i)},v_{-i}^{(i)}) = \frac{\mathcal P(h^{(i)},v_i^{(i)},v_{-i}^{(i)})}{\mathcal P(h^{(i)},v_{-i}^{(i)})} = \frac{\mathcal P(h^{(i)},v^{(i)})}{\mathcal P(h^{(i)},v_{-i}^{(i)})} P(vi(i)∣h(i),v−i(i))=P(h(i),v−i(i))P(h(i),vi(i),v−i(i))=P(h(i),v−i(i))P(h(i),v(i)) - 上式中分子部分明显是玻尔兹曼机的概率密度函数;而分母是概率密度函数将 v i ( i ) v_i^{(i)} vi(i)积分掉后的结果。将概率密度函数带入,有:
后续为了方便表达,将P ( v i ( i ) ∣ h ( i ) , v − i ( i ) ) \mathcal P(v_i^{(i)} \mid h^{(i)},v_{-i}^{(i)}) P(vi(i)∣h(i),v−i(i))使用I \mathcal I I表示。
I = P ( h ( i ) , v ( i ) ) ∑ v i ( i ) P ( h ( i ) , v ( i ) ) = 1 Z exp { − E ( v ( i ) , h ( i ) ) } ∑ v i ( i ) 1 Z exp { − E ( v ( i ) , h ( i ) ) } \begin{aligned} \mathcal I & = \frac{\mathcal P(h^{(i)},v^{(i)})}{\sum_{v_i^{(i)}} \mathcal P(h^{(i)},v^{(i)})} \\ & = \frac{\frac{1}{\mathcal Z}\exp \{ - \mathbb E(v^{(i)},h^{(i)})\}}{\sum_{v_i^{(i)}}\frac{1}{\mathcal Z}\exp \{ - \mathbb E(v^{(i)},h^{(i)})\}} \end{aligned} I=∑vi(i)P(h(i),v(i))P(h(i),v(i))=∑vi(i)Z1exp{−E(v(i),h(i))}Z1exp{−E(v(i),h(i))}
观察分布部分, Z \mathcal Z Z是配分函数,它的表示如下:
Z = ∑ v ( i ) ∑ h ( i ) exp { − E ( v ( i ) , h ( i ) ) } \mathcal Z = \sum_{v^{(i)}} \sum_{h^{(i)}} \exp \{- \mathbb E(v^{(i)},h^{(i)})\} Z=v(i)∑h(i)∑exp{−E(v(i),h(i))}
可以看出,配分函数 Z \mathcal Z Z与 v i ( i ) v_i^{(i)} vi(i)之间没有关系,因此可以将 1 Z \frac{1}{\mathcal Z} Z1提到 ∑ v i ( i ) \sum_{v_i^{(i)}} ∑vi(i)前面,最终和分子中的 1 Z \frac{1}{\mathcal Z} Z1消掉。然后根据 玻尔兹曼机的定义,将能量函数展开,最终表示如下:
I = 1 Z exp { − E ( v ( i ) , h ( i ) ) } 1 Z ∑ v i ( i ) exp { − E ( v ( i ) , h ( i ) ) } = exp { [ v ( i ) ] T W ⋅ h ( i ) + 1 2 [ v ( i ) ] T L ⋅ v ( i ) + 1 2 [ h ( i ) ] T J ⋅ h ( i ) } ∑ v i ( i ) exp { [ v ( i ) ] T W ⋅ h ( i ) + 1 2 [ v ( i ) ] T L ⋅ v ( i ) + 1 2 [ h ( i ) ] T J ⋅ h ( i ) } \begin{aligned} \mathcal I & = \frac{\frac{1}{\mathcal Z} \exp \{- \mathbb E(v^{(i)},h^{(i)})\}}{\frac{1}{\mathcal Z}\sum_{v_i^{(i)}}\exp \{- \mathbb E(v^{(i)},h^{(i)})\}} \\ & = \frac{\exp \left\{[v^{(i)}]^T\mathcal W\cdot h^{(i)} + \frac{1}{2} [v^{(i)}]^T \mathcal L\cdot v^{(i)} +\frac{1}{2} [h^{(i)}]^T \mathcal J \cdot h^{(i)}\right\}}{\sum_{v_i^{(i)}}\exp \left\{[v^{(i)}]^T\mathcal W\cdot h^{(i)} + \frac{1}{2} [v^{(i)}]^T \mathcal L\cdot v^{(i)} +\frac{1}{2} [h^{(i)}]^T \mathcal J \cdot h^{(i)}\right\}} \end{aligned} I=Z1∑vi(i)exp{−E(v(i),h(i))}Z1exp{−E(v(i),h(i))}=∑vi(i)exp{[v(i)]TW⋅h(i)+21[v(i)]TL⋅v(i)+21[h(i)]TJ⋅h(i)}exp{[v(i)]TW⋅h(i)+21[v(i)]TL⋅v(i)+21[h(i)]TJ⋅h(i)} - 继续将分子分母的大括号展开:
注意:h ( i ) h^{(i)} h(i)和∑ v i ( i ) \sum_{v_i^{(i)}} ∑vi(i)之间没有关系,可以将分母中的1 2 [ h ( i ) ] T J ⋅ h ( i ) \frac{1}{2} [h^{(i)}]^T \mathcal J \cdot h^{(i)} 21[h(i)]TJ⋅h(i)提到积分号前,并与分子中的对应项消掉。
I = exp { [ v ( i ) ] T W ⋅ h ( i ) + 1 2 [ v ( i ) ] T L ⋅ v ( i ) } ⋅ exp { 1 2 [ h ( i ) ] T J ⋅ h ( i ) } exp { 1 2 [ h ( i ) ] T J ⋅ h ( i ) } ⋅ ∑ v i ( i ) exp { [ v ( i ) ] T W ⋅ h ( i ) + 1 2 [ v ( i ) ] T L ⋅ v ( i ) } = exp { [ v ( i ) ] T W ⋅ h ( i ) + 1 2 [ v ( i ) ] T L ⋅ v ( i ) } ∑ v i ( i ) exp { [ v ( i ) ] T W ⋅ h ( i ) + 1 2 [ v ( i ) ] T L ⋅ v ( i ) } \begin{aligned} \mathcal I & = \frac{\exp \left\{[v^{(i)}]^T\mathcal W \cdot h^{(i)} + \frac{1}{2} [v^{(i)}]^T \mathcal L \cdot v^{(i)}\right\} \cdot \exp\{\frac{1}{2} [h^{(i)}]^T \mathcal J \cdot h^{(i)}\}}{\exp \left\{\frac{1}{2} [h^{(i)}]^T \mathcal J \cdot h^{(i)}\right\} \cdot \sum_{v_i^{(i)}}\exp\left\{[v^{(i)}]^T\mathcal W \cdot h^{(i)} + \frac{1}{2} [v^{(i)}]^T \mathcal L \cdot v^{(i)}\right\}} \\ & = \frac{\exp\left\{[v^{(i)}]^T\mathcal W \cdot h^{(i)} + \frac{1}{2} [v^{(i)}]^T \mathcal L \cdot v^{(i)}\right\}}{\sum_{v_i^{(i)}}\exp\left\{[v^{(i)}]^T\mathcal W \cdot h^{(i)} + \frac{1}{2} [v^{(i)}]^T \mathcal L \cdot v^{(i)}\right\}} \end{aligned} I=exp{21[h(i)]TJ⋅h(i)}⋅∑vi(i)exp{[v(i)]TW⋅h(i)+21[v(i)]TL⋅v(i)}exp{[v(i)]TW⋅h(i)+21[v(i)]TL⋅v(i)}⋅exp{21[h(i)]TJ⋅h(i)}=∑vi(i)exp{[v(i)]TW⋅h(i)+21[v(i)]TL⋅v(i)}exp{[v(i)]TW⋅h(i)+21[v(i)]TL⋅v(i)} - 由于 v i ( i ) v_i^{(i)} vi(i)服从伯努利分布,因而分母自然可以写成两项相加的形式 ( v i ( i ) = 0 , v i ( i ) = 1 ) (v_i^{(i)}=0,v_i^{(i)} = 1) (vi(i)=0,vi(i)=1),并且在分母中 v i ( i ) v_i^{(i)} vi(i)已经被积分掉,也就是说 v i ( i ) v_i^{(i)} vi(i)在分母中不是变量。当 v i ( i ) = 1 v_i^{(i)} = 1 vi(i)=1时,仅修改分子中的描述:
P ( v i ( i ) = 1 ∣ h ( i ) , v − i ( i ) ) = I v i ( i ) = 1 = exp { [ v ( i ) ] T W ⋅ h ( i ) + 1 2 [ v ( i ) ] T L ⋅ v ( i ) } ∣ v i ( i ) = 1 exp { [ v ( i ) ] T W ⋅ h ( i ) + 1 2 [ v ( i ) ] T L ⋅ v ( i ) } ∣ v i ( i ) = 0 + exp { [ v ( i ) ] T W ⋅ h ( i ) + 1 2 [ v ( i ) ] T L ⋅ v ( i ) } ∣ v i ( i ) = 1 \begin{aligned} \mathcal P(v_i^{(i)} = 1 \mid h^{(i)},v_{-i}^{(i)}) & = \mathcal I_{v_i^{(i)} = 1} \\ & = \frac{\exp\left\{[v^{(i)}]^T\mathcal W \cdot h^{(i)} + \frac{1}{2} [v^{(i)}]^T \mathcal L \cdot v^{(i)}\right\} \mid_{v_i^{(i)} = 1}}{\exp\left\{[v^{(i)}]^T\mathcal W \cdot h^{(i)} + \frac{1}{2} [v^{(i)}]^T \mathcal L \cdot v^{(i)}\right\} \mid_{v_i^{(i)} = 0} + \exp\left\{[v^{(i)}]^T\mathcal W \cdot h^{(i)} + \frac{1}{2} [v^{(i)}]^T \mathcal L \cdot v^{(i)}\right\} \mid_{v_i^{(i)} = 1}} \end{aligned} P(vi(i)=1∣h(i),v−i(i))=Ivi(i)=1=exp{[v(i)]TW⋅h(i)+21[v(i)]TL⋅v(i)}∣vi(i)=0+exp{[v(i)]TW⋅h(i)+21[v(i)]TL⋅v(i)}∣vi(i)=1exp{[v(i)]TW⋅h(i)+21[v(i)]TL⋅v(i)}∣vi(i)=1
定义符号: Δ = exp { [ v ( i ) ] T W ⋅ h ( i ) + 1 2 [ v ( i ) ] T L ⋅ v ( i ) } \Delta = \exp\left\{[v^{(i)}]^T\mathcal W \cdot h^{(i)} + \frac{1}{2} [v^{(i)}]^T \mathcal L \cdot v^{(i)}\right\} Δ=exp{[v(i)]TW⋅h(i)+21[v(i)]TL⋅v(i)},上式可简写成如下形式:
P ( v i ( i ) = 1 ∣ h ( i ) , v − i ( i ) ) = Δ v i ( i ) = 1 Δ v i ( i ) = 0 + Δ v i ( i ) = 1 \mathcal P(v_i^{(i)} = 1 \mid h^{(i)},v_{-i}^{(i)}) = \frac{\Delta_{v_i^{(i)} = 1}}{\Delta_{v_i^{(i)} = 0} + \Delta_{v_i^{(i)}=1}} P(vi(i)=1∣h(i),v−i(i))=Δvi(i)=0+Δvi(i)=1Δvi(i)=1 - 继续观察,暂时先不管 v i ( i ) v_i^{(i)} vi(i)的取值,先观察 Δ \Delta Δ。由于 Δ \Delta Δ中全部是向量乘积的形式,因而将其展开,表示成连加形式:
Δ = exp { [ v ( i ) ] T W ⋅ h ( i ) + 1 2 [ v ( i ) ] T L ⋅ v ( i ) } = exp { ∑ l = 1 D ∑ j = 1 P v l ( i ) ⋅ W l j ⋅ h j ( i ) + 1 2 ∑ l = 1 D ∑ k = 1 D v l ( i ) ⋅ L l k ⋅ v k ( i ) } \begin{aligned} \Delta & = \exp\left\{[v^{(i)}]^T\mathcal W \cdot h^{(i)} + \frac{1}{2} [v^{(i)}]^T \mathcal L \cdot v^{(i)}\right\} \\ & = \exp \left\{\sum_{l=1}^{\mathcal D}\sum_{j=1}^{\mathcal P} v_l^{(i)} \cdot \mathcal W_{lj} \cdot h_j^{(i)} + \frac{1}{2} \sum_{l=1}^{\mathcal D}\sum_{k=1}^{\mathcal D} v_l^{(i)} \cdot \mathcal L_{lk} \cdot v_k^{(i)}\right\} \end{aligned} Δ=exp{[v(i)]TW⋅h(i)+21[v(i)]TL⋅v(i)}=exp{l=1∑Dj=1∑Pvl(i)⋅Wlj⋅hj(i)+21l=1∑Dk=1∑Dvl(i)⋅Llk⋅vk(i)}
观察上式大括号中的第一项, ∑ l = 1 D ∑ j = 1 P v l ( i ) ⋅ W l j ⋅ h j ( i ) \sum_{l=1}^{\mathcal D}\sum_{j=1}^{\mathcal P} v_l^{(i)} \cdot \mathcal W_{lj} \cdot h_j^{(i)} ∑l=1D∑j=1Pvl(i)⋅Wlj⋅hj(i)内部一共包含 D × P \mathcal D \times \mathcal P D×P个连加项,其中有 P \mathcal P P个项是和 v i ( i ) v_i^{(i)} vi(i)相关的:
v i ( i ) ⇒ ∑ j = 1 P v i ( i ) ⋅ W i j ⋅ h j ( i ) v_i^{(i)} \Rightarrow \sum_{j=1}^{\mathcal P} v_i^{(i)} \cdot \mathcal W_{ij} \cdot h_j^{(i)} vi(i)⇒j=1∑Pvi(i)⋅Wij⋅hj(i)
同理,观察上式大括号中的第二项, 1 2 ∑ l = 1 D ∑ k = 1 D v l ( i ) ⋅ L l k ⋅ v k ( i ) \frac{1}{2} \sum_{l=1}^{\mathcal D}\sum_{k=1}^{\mathcal D} v_l^{(i)} \cdot \mathcal L_{lk} \cdot v_k^{(i)} 21∑l=1D∑k=1Dvl(i)⋅Llk⋅vk(i)内部一共包含 D × D \mathcal D \times \mathcal D D×D个连加项,其中和 v i ( i ) v_i^{(i)} vi(i)相关的项有 2 D − 1 2\mathcal D - 1 2D−1项:
L \mathcal L L矩阵第i i i行与第i i i列的项之和。其中i i i行 i i i列结果被加重了一次,需要减掉。
v i ( i ) ⇒ v i ( i ) ⋅ L i i ⋅ v i ( i ) ⏟ 1 项 + ∑ l ≠ i D v l ( i ) ⋅ L l i ⋅ v i ( i ) ⏟ D − 1 项 + ∑ k ≠ i D v i ( i ) ⋅ L i k ⋅ v k ( i ) ⏟ D − 1 项 v_i^{(i)} \Rightarrow \underbrace{v_i^{(i)} \cdot \mathcal L_{ii} \cdot v_i^{(i)}}_{1项} + \underbrace{\sum_{l\neq i}^{\mathcal D}v_l^{(i)} \cdot \mathcal L_{li} \cdot v_i^{(i)}}_{\mathcal D - 1项} + \underbrace{\sum_{k \neq i}^{\mathcal D}v_i^{(i)} \cdot \mathcal L_{ik} \cdot v_k^{(i)}}_{\mathcal D - 1项} vi(i)⇒1项 vi(i)⋅Lii⋅vi(i)+D−1项 l=i∑Dvl(i)⋅Lli⋅vi(i)+D−1项 k=i∑Dvi(i)⋅Lik⋅vk(i)
实际上,由于 L \mathcal L L是对角线上元素为0的实对称矩阵,因此,有:
∑ l ≠ i D v l ( i ) ⋅ L l i ⋅ v i ( i ) = ∑ k ≠ i D v i ( i ) ⋅ L i k ⋅ v k ( i ) v i ( i ) ⇒ v i ( i ) ⋅ L i i ⋅ v i ( i ) ⏟ = 0 + 2 ∑ k ≠ i D v i ( i ) ⋅ L i k ⋅ v k ( i ) \begin{aligned} \sum_{l\neq i}^{\mathcal D}v_l^{(i)} \cdot \mathcal L_{li} \cdot v_i^{(i)} = \sum_{k \neq i}^{\mathcal D}v_i^{(i)} \cdot \mathcal L_{ik} \cdot v_k^{(i)} \\ v_i^{(i)} \Rightarrow \underbrace{v_i^{(i)} \cdot \mathcal L_{ii} \cdot v_i^{(i)}}_{=0} + 2\sum_{k \neq i}^{\mathcal D}v_i^{(i)} \cdot \mathcal L_{ik} \cdot v_k^{(i)} \end{aligned} l=i∑Dvl(i)⋅Lli⋅vi(i)=k=i∑Dvi(i)⋅Lik⋅vk(i)vi(i)⇒=0 vi(i)⋅Lii⋅vi(i)+2k=i∑Dvi(i)⋅Lik⋅vk(i) - 至此,已经将所有关于 v i ( i ) v_i^{(i)} vi(i)的项全部找到。最终将 Δ \Delta Δ中的所有连加项分成与 v i ( i ) v_i^{(i)} vi(i)相关和不相关的两部分:
Δ = exp { ∑ l ≠ i D ∑ j = 1 P v l ( i ) ⋅ W l j ⋅ h j ( i ) + ∑ j = 1 P v i ( i ) ⋅ W i j ⋅ h j ( i ) + 1 2 [ ∑ l ≠ i D ∑ k ≠ i D v l ( i ) ⋅ L l k ⋅ v k ( i ) + v i ( i ) ⋅ L i i ⋅ v i ( i ) ⏟ = 0 + 2 ∑ k ≠ i D v i ( i ) ⋅ L i k ⋅ v k ( i ) ] } = exp { ∑ l ≠ i D ∑ j = 1 P v l ( i ) ⋅ W l j ⋅ h j ( i ) + ∑ j = 1 P v i ( i ) ⋅ W i j ⋅ h j ( i ) + 1 2 ∑ l ≠ i D ∑ k ≠ i D v l ( i ) ⋅ L l k ⋅ v k ( i ) + ∑ k ≠ i D v i ( i ) ⋅ L i k ⋅ v k ( i ) } \begin{aligned} \Delta & = \exp \left\{\sum_{l \neq i}^{\mathcal D} \sum_{j=1}^{\mathcal P} v_l^{(i)} \cdot \mathcal W_{lj} \cdot h_j^{(i)} + \sum_{j=1}^{\mathcal P}v_i^{(i)} \cdot \mathcal W_{ij} \cdot h_j^{(i)} + \frac{1}{2} \left[\sum_{l \neq i}^{\mathcal D}\sum_{k \neq i}^{\mathcal D} v_l^{(i)} \cdot \mathcal L_{lk}\cdot v_k^{(i)} + \underbrace{v_i^{(i)} \cdot \mathcal L_{ii} \cdot v_i^{(i)}}_{=0} + 2\sum_{k \neq i}^{\mathcal D}v_i^{(i)} \cdot \mathcal L_{ik} \cdot v_k^{(i)}\right]\right\} \\ & = \exp \left\{\sum_{l \neq i}^{\mathcal D} \sum_{j=1}^{\mathcal P} v_l^{(i)} \cdot \mathcal W_{lj} \cdot h_j^{(i)} + \sum_{j=1}^{\mathcal P}v_i^{(i)} \cdot \mathcal W_{ij} \cdot h_j^{(i)} + \frac{1}{2} \sum_{l \neq i}^{\mathcal D}\sum_{k \neq i}^{\mathcal D} v_l^{(i)} \cdot \mathcal L_{lk}\cdot v_k^{(i)} + \sum_{k \neq i}^{\mathcal D}v_i^{(i)} \cdot \mathcal L_{ik} \cdot v_k^{(i)}\right\} \end{aligned} Δ=exp⎩ ⎨ ⎧l=i∑Dj=1∑Pvl(i)⋅Wlj⋅hj(i)+j=1∑Pvi(i)⋅Wij⋅hj(i)+21 l=i∑Dk=i∑Dvl(i)⋅Llk⋅vk(i)+=0 vi(i)⋅Lii⋅vi(i)+2k=i∑Dvi(i)⋅Lik⋅vk(i) ⎭ ⎬ ⎫=exp⎩ ⎨ ⎧l=i∑Dj=1∑Pvl(i)⋅Wlj⋅hj(i)+j=1∑Pvi(i)⋅Wij⋅hj(i)+21l=i∑Dk=i∑Dvl(i)⋅Llk⋅vk(i)+k=i∑Dvi(i)⋅Lik⋅vk(i)⎭ ⎬ ⎫
当 v i ( i ) = 0 v_i^{(i)} = 0 vi(i)=0时, Δ v i ( i ) = 0 \Delta_{v_i^{(i)} = 0} Δvi(i)=0具体表示为:
Δ v i ( i ) = 0 = exp { ∑ l ≠ i D ∑ j = 1 P v l ( i ) ⋅ W l j ⋅ h j ( i ) + ∑ j = 1 P v i ( i ) ⋅ W i j ⋅ h j ( i ) ⏟ = 0 + 1 2 ∑ l ≠ i D ∑ k ≠ i D v l ( i ) ⋅ L l k ⋅ v k ( i ) + ∑ k ≠ i D v i ( i ) ⋅ L i k ⋅ v k ( i ) ⏟ = 0 } = exp { ∑ l ≠ i D ∑ j = 1 P v l ( i ) ⋅ W l j ⋅ h j ( i ) + 1 2 ∑ l ≠ i D ∑ k ≠ i D v l ( i ) ⋅ L l k ⋅ v k ( i ) } \begin{aligned} \Delta_{v_i^{(i)} = 0} & = \exp \left\{\sum_{l \neq i}^{\mathcal D} \sum_{j=1}^{\mathcal P} v_l^{(i)} \cdot \mathcal W_{lj} \cdot h_j^{(i)} + \underbrace{\sum_{j=1}^{\mathcal P}v_i^{(i)} \cdot \mathcal W_{ij} \cdot h_j^{(i)}}_{=0} + \frac{1}{2} \sum_{l \neq i}^{\mathcal D}\sum_{k \neq i}^{\mathcal D} v_l^{(i)} \cdot \mathcal L_{lk}\cdot v_k^{(i)} + \underbrace{\sum_{k \neq i}^{\mathcal D}v_i^{(i)} \cdot \mathcal L_{ik} \cdot v_k^{(i)}}_{=0}\right\} \\ & = \exp \left\{\sum_{l \neq i}^{\mathcal D} \sum_{j=1}^{\mathcal P} v_l^{(i)} \cdot \mathcal W_{lj} \cdot h_j^{(i)} + \frac{1}{2} \sum_{l \neq i}^{\mathcal D}\sum_{k \neq i}^{\mathcal D} v_l^{(i)} \cdot \mathcal L_{lk}\cdot v_k^{(i)}\right\} \end{aligned} Δvi(i)=0=exp⎩ ⎨ ⎧l=i∑Dj=1∑Pvl(i)⋅Wlj⋅hj(i)+=0 j=1∑Pvi(i)⋅Wij⋅hj(i)+21l=i∑Dk=i∑Dvl(i)⋅Llk⋅vk(i)+=0 k=i∑Dvi(i)⋅Lik⋅vk(i)⎭ ⎬ ⎫=exp⎩ ⎨ ⎧l=i∑Dj=1∑Pvl(i)⋅Wlj⋅hj(i)+21l=i∑Dk=i∑Dvl(i)⋅Llk⋅vk(i)⎭ ⎬ ⎫
对应的 v i ( i ) = 1 v_i^{(i)} = 1 vi(i)=1时, Δ v i ( i ) = 1 \Delta_{v_i^{(i)} = 1} Δvi(i)=1具体表示为:
Δ v i ( i ) = 1 = exp { ∑ l ≠ i D ∑ j = 1 P v l ( i ) ⋅ W l j ⋅ h j ( i ) + ∑ j = 1 P W i j ⋅ h j ( i ) + 1 2 ∑ l ≠ i D ∑ k ≠ i D v l ( i ) ⋅ L l k ⋅ v k ( i ) + ∑ k ≠ i D L i k ⋅ v k ( i ) } \Delta_{v_i^{(i)} = 1} = \exp \left\{\sum_{l \neq i}^{\mathcal D} \sum_{j=1}^{\mathcal P} v_l^{(i)} \cdot \mathcal W_{lj} \cdot h_j^{(i)} + \sum_{j=1}^{\mathcal P} \mathcal W_{ij} \cdot h_j^{(i)} + \frac{1}{2} \sum_{l \neq i}^{\mathcal D}\sum_{k \neq i}^{\mathcal D} v_l^{(i)} \cdot \mathcal L_{lk}\cdot v_k^{(i)} + \sum_{k \neq i}^{\mathcal D} \mathcal L_{ik} \cdot v_k^{(i)}\right\} Δvi(i)=1=exp⎩ ⎨ ⎧l=i∑Dj=1∑Pvl(i)⋅Wlj⋅hj(i)+j=1∑PWij⋅hj(i)+21l=i∑Dk=i∑Dvl(i)⋅Llk⋅vk(i)+k=i∑DLik⋅vk(i)⎭ ⎬ ⎫ - 最终,将 Δ v i ( i ) = 0 , Δ v i ( i ) = 1 \Delta_{v_i^{(i)} = 0},\Delta_{v_i^{(i)} = 1} Δvi(i)=0,Δvi(i)=1带回 P ( v i ( i ) = 1 ∣ h ( i ) , v − i ( i ) ) = Δ v i ( i ) = 1 Δ v i ( i ) = 0 + Δ v i ( i ) = 1 \mathcal P(v_i^{(i)} = 1 \mid h^{(i)},v_{-i}^{(i)}) = \frac{\Delta_{v_i^{(i)} = 1}}{\Delta_{v_i^{(i)} = 0} + \Delta_{v_i^{(i)}=1}} P(vi(i)=1∣h(i),v−i(i))=Δvi(i)=0+Δvi(i)=1Δvi(i)=1中,有:
分子、分母同时除以exp { ∑ l ≠ i D ∑ j = 1 P v l ( i ) ⋅ W l j ⋅ h j ( i ) + 1 2 ∑ l ≠ i D ∑ k ≠ i D v l ( i ) ⋅ L l k ⋅ v k ( i ) } \exp \left\{\sum_{l \neq i}^{\mathcal D} \sum_{j=1}^{\mathcal P} v_l^{(i)} \cdot \mathcal W_{lj} \cdot h_j^{(i)} + \frac{1}{2} \sum_{l \neq i}^{\mathcal D}\sum_{k \neq i}^{\mathcal D} v_l^{(i)} \cdot \mathcal L_{lk}\cdot v_k^{(i)}\right\} exp{∑l=iD∑j=1Pvl(i)⋅Wlj⋅hj(i)+21∑l=iD∑k=iDvl(i)⋅Llk⋅vk(i)}
P ( v i ( i ) = 1 ∣ h ( i ) , v − i ( i ) ) = exp { ∑ j = 1 P W i j ⋅ h j ( i ) + ∑ k ≠ i D L i k ⋅ v k ( i ) } 1 + exp { ∑ j = 1 P W i j ⋅ h j ( i ) + ∑ k ≠ i D L i k ⋅ v k ( i ) } \mathcal P(v_i^{(i)} = 1 \mid h^{(i)},v_{-i}^{(i)}) = \frac{\exp \left\{\sum_{j=1}^{\mathcal P} \mathcal W_{ij} \cdot h_j^{(i)} + \sum_{k \neq i}^{\mathcal D} \mathcal L_{ik} \cdot v_k^{(i)}\right\}}{1 + \exp \left\{\sum_{j=1}^{\mathcal P} \mathcal W_{ij} \cdot h_j^{(i)} + \sum_{k \neq i}^{\mathcal D} \mathcal L_{ik} \cdot v_k^{(i)}\right\}} P(vi(i)=1∣h(i),v−i(i))=1+exp{∑j=1PWij⋅hj(i)+∑k=iDLik⋅vk(i)}exp{∑j=1PWij⋅hj(i)+∑k=iDLik⋅vk(i)}
基于上式,分子、分母继续同时除以exp { ∑ j = 1 P W i j ⋅ h j ( i ) + ∑ k ≠ i D L i k ⋅ v k ( i ) } \exp \left\{\sum_{j=1}^{\mathcal P} \mathcal W_{ij} \cdot h_j^{(i)} + \sum_{k \neq i}^{\mathcal D} \mathcal L_{ik} \cdot v_k^{(i)}\right\} exp{∑j=1PWij⋅hj(i)+∑k=iDLik⋅vk(i)},有:
P ( v i ( i ) = 1 ∣ h ( i ) , v − i ( i ) ) = 1 1 + 1 exp { ∑ j = 1 P W i j ⋅ h j ( i ) + ∑ k ≠ i D L i k ⋅ v k ( i ) } = 1 1 + exp − { ∑ j = 1 P W i j ⋅ h j ( i ) + ∑ k ≠ i D L i k ⋅ v k ( i ) } = Sigmoid { ∑ j = 1 P W i j ⋅ h j ( i