Pytorch 基本概念
Pytorch 基本概念
张量(Tensor)
PyTorch 张量(Tensor),张量是PyTorch最基本的操作对象,英文名称为Tensor,它表示的是一个多维的矩阵。比如零维是一个点,一维就是向量,二维就是一般的矩阵,多维就相当于一个多维的数组,这和numpy是对应的,而且 Pytorch 的 Tensor 可以和 numpy 的ndarray相互转换,唯一不同的是Pytorch可以在GPU上运行,而numpy的 ndarray 只能在CPU上运行。
常用的不同数据类型的 Tensor 如下:
- 32位浮点型 torch.FloatTensor
- 64位浮点型 torch.DoubleTensor
- 16位整型 torch.ShortTensor
- 32位整型 torch.IntTensor
- 64位整型 torch.LongTensor
变量(Variable)
Variable,也就是变量,这个在numpy里面是没有的,是神经网络计算图里特有的一个概念,就是Variable提供了自动求导的功能,之前如果了解Tensorflow的读者应该清楚神经网络在做运算的时候需要先构造一个计算图谱,然后在里面运行前向传播和反向传播。
Variable和Tensor本质上没有区别,不过Variable会被放入一个计算图中,然后进行前向传播,反向传播,自动求导。
首先Variable是在torch.autograd.Variable中,要将一个tensor变成Variable也非常简单,比如想让一个tensor a变成Variable,只需要Variable(a)就可以了。Variable的属性如下:

Variable 有三个比较重要的组成属性:data、grad和grad_fn。通过data可以取出 Variable 里面的tensor数值,grad_fn表示的是得到这个Variable的操作。比如通过加减还是乘除来得到的,最后grad是这个Variable的反向传播梯度。
构建Variable,要注意得传入一个参数requires_grad=True,这个参数表示是否对这个变量求梯度,默认的是False,也就是不对这个变量求梯度,这里我们希望得到这些变量的梯度,所以需要传入这个参数。
y.backward(),这一行代码就是所谓的自动求导,这其实等价于y.backward(torch.FloatTensor([1])),只不过对于标量求导里面的参数就可以不写了,自动求导不需要你再去明确地写明哪个函数对哪个函数求导,直接通过这行代码就能对所有的需要梯度的变量进行求导,得到它们的梯度,然后通过x.grad可以得到x的梯度。
矩阵求导,相当于给出了一个三维向量去做运算,这时候得到的结果y就是一个向量,这里对这个向量求导就不能直接写成y.backward(),这样程序就会报错的。这个时候需要传入参数声明,比如y.backward(troch.FloatTensor([1, 1, 1])),这样得到的结果就是它们每个分量的梯度,或者可以传入y.backward(torch.FloatTensor([1, 0.1, 0.01])),这样得到的梯度就是它们原本的梯度分别乘上1, 0.1 和 0.01。
数据集(dataset)
数据读取和预处理是进行机器学习的首要操作,PyTorch提供了很多方法来完成数据的读取和预处理。本文介绍 Dataset,TensorDataset,DataLoader,ImageFolder的简单用法。
torch.utils.data.Dataset
torch.utils.data.Dataset是代表这一数据的抽象类。你可以自己定义你的数据类,继承和重写这个抽象类,非常简单,只需要定义__len__和__getitem__这个两个函数:
from torch.utils.data import Dataset
import pandas as pd
class myDataset(Dataset):
def __init__(self,csv_file,txt_file,root_dir, other_file):
self.csv_data = pd.read_csv(csv_file)
with open(txt_file,'r') as f:
data_list = f.readlines()
self.txt_data = data_list
self.root_dir = root_dir
def __len__(self):
return len(self.csv_data)
def __gettime__(self,idx):
data = (self.csv_data[idx],self.txt_data[idx])
return data
通过上面的方式,可以定义我们需要的数据类,可以通过迭代的方式来获取每一个数据,但这样很难实现取batch,shuffle或者是多线程去读取数据。
torch.utils.data.TensorDataset
torch.utils.data.TensorDataset 继承自 Dataset,新版把之前的data_tensor和target_tensor去掉了,输入变成了可变参数,也就是我们平常使用*args。
原版使用方法
train_dataset = Data.TensorDataset(data_tensor=x, target_tensor=y)
# 新版使用方法
train_dataset = Data.TensorDataset(x,y)
使用 TensorDataset 的方法可以参考下面的例子:
import torch
import torch.utils.data as Data
BATCH_SIZE = 5
x = torch.linspace(1, 10, 10)
y = torch.linspace(10, 1, 10)
torch_dataset = Data.TensorDataset(x, y)
loader = Data.DataLoader(
dataset=torch_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=0,
)
for epoch in range(3):
for step, (batch_x, batch_y) in enumerate(loader):
print('Epoch: ', epoch, '| Step: ', step, '| batch x: ', batch_x.numpy(), '| batch y: ', batch_y.numpy())
执行结果:

torch.utils.data.DataLoader
PyTorch中提供了一个简单的办法来做这个事情,通过torch.utils.data.DataLoader来定义一个新的迭代器,如下:
from torch.utils.data import DataLoader
dataiter = DataLoader(myDataset,batch_size=32,shuffle=True,collate_fn=defaulf_collate)
其中的参数都很清楚,只有 collate_fn 是标识如何取样本的,我们可以定义自己的函数来准确地实现想要的功能,默认的函数在一般情况下都是可以使用的。
需要注意的是,Dataset类只相当于一个打包工具,包含了数据的地址。真正把数据读入内存的过程是由Dataloader进行批迭代输入的时候进行的。
torchvision.datasets.ImageFolder
另外在torchvison这个包中还有一个更高级的有关于计算机视觉的数据读取类:ImageFolder,主要功能是处理图片,且要求图片是下面这种存放形式:
root/dog/xxx.png
root/dog/xxy.png
root/dog/xxz.png
root/cat/123.png
root/cat/asd/png
root/cat/zxc.png
之后这样来调用这个类:
from torchvision.datasets import ImageFolder
dset = ImageFolder(root='root_path', transform=None, loader=default_loader)
其中 root 需要是根目录,在这个目录下有几个文件夹,每个文件夹表示一个类别:transform 和 target_transform 是图片增强,后面我们会详细介绍;loader是图片读取的办法,因为我们读取的是图片的名字,然后通过 loader 将图片转换成我们需要的图片类型进入神经网络。
PyTorch 优化
优化算法就是一种调整模型参数更新的策略,在深度学习和机器学习中,我们常常通过修改参数使得损失函数最小化或最大化。
优化算法分为两大类:
(1) 一阶优化算法
这种算法使用各个参数的梯度值来更新参数,最常用的一阶优化算法是梯度下降。所谓的梯度就是导数的多变量表达式,函数的梯度形成了一个向量场,同时也是一个方向,这个方向上方向导数最大,且等于梯度。梯度下降的功能是通过寻找最小值,控制方差,更新模型参数,最终使模型收敛,网络的参数更新公式如下:

(2) 二阶优化算法
二阶优化算法是用来二阶导数(也叫做Hessian方法)来最小化或最大化损失函数,主要基于牛顿法,但由于二阶导数的计算成本很高,所以这种方法并没有广泛使用。torch.optim是一个实现了各种优化算法的库,多数常见的算法都能直接通过这个包来调用,并且接口具备足够的通用性,使得未来能够集成更加复杂的方法,比如随机梯度下降,以及添加动量的随机梯度下降,自适应学习率等。为了构建一个Optimizer,你需要给它一个包含了需要优化的参数(必须都是Variable对象)的iterable。然后设置optimizer的参数选项,比如学习率,动量等等。
import torch
import torch.utils.data as Data
import torch.nn.functional as F
from torch.autograd import Variable
import matplotlib.pyplot as plt
torch.manual_seed(1) # reproducible
LR = 0.01
BATCH_SIZE = 32
EPOCH = 12
# fake dataset
x = torch.unsqueeze(torch.linspace(-1, 1, 1000), dim=1)
y = x.pow(2) + 0.1*torch.normal(torch.zeros(*x.size()))
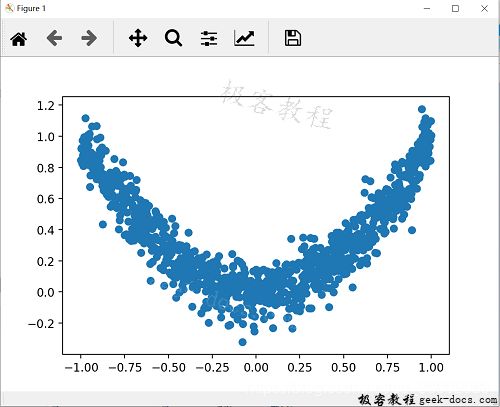
# plot dataset
plt.scatter(x.numpy(), y.numpy())
plt.show()
执行结果如下:
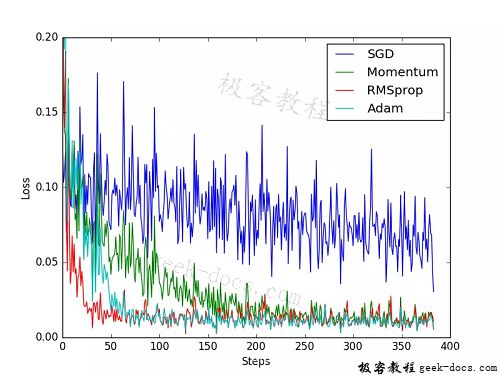
为了对比每一种优化器, 我们给他们各自创建一个神经网络, 但这个神经网络都来自同一个 Net 形式。接下来在创建不同的优化器, 用来训练不同的网络. 并创建一个 loss_func 用来计算误差。几种常见的优化器:SGD, Momentum, RMSprop, Adam。
torch_dataset = Data.TensorDataset(x, y)
loader = Data.DataLoader(dataset=torch_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=0,)
# 默认的 network 形式
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(1, 20) # hidden layer
self.predict = torch.nn.Linear(20, 1) # output layer
def forward(self, x):
x = F.relu(self.hidden(x)) # activation function for hidden layer
x = self.predict(x) # linear output
return x
# 为每个优化器创建一个 net
net_SGD = Net()
net_Momentum = Net()
net_RMSprop = Net()
net_Adam = Net()
nets = [net_SGD, net_Momentum, net_RMSprop, net_Adam]
# different optimizers
opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR)
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8)
opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9)
opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
optimizers = [opt_SGD, opt_Momentum, opt_RMSprop, opt_Adam]
loss_func = torch.nn.MSELoss()
losses_his = [[], [], [], []] # 记录 training 时不同神经网络的 loss
for epoch in range(EPOCH):
print('Epoch: ', epoch)
for step, (batch_x, batch_y) in enumerate(loader):
b_x = Variable(batch_x) # 务必要用 Variable 包一下
b_y = Variable(batch_y)
# 对每个优化器, 优化属于他的神经网络
for net, opt, l_his in zip(nets, optimizers, losses_his):
output = net(b_x) # get output for every net
loss = loss_func(output, b_y) # compute loss for every net
opt.zero_grad() # clear gradients for next train
loss.backward() # backpropagation, compute gradients
opt.step() # apply gradients
l_his.append(loss.item()) # loss recoder
训练和 loss 画图,结果如下: