实例分割: 一文读懂 E2EC (CVPR 2022)
论文:E2EC:An End-to-End Contour-based Method for High-Quality High-Speed Instance Segmentation
代码: https://github.com/zhang-tao-whu/e2ec
1 前言
1.1 实例分割技术路线
实例分割方法可分为two stage方法和one stage方法:
(1) two stage:先生成bboxes,再进行实例分割,代表模型有:Mask R-CNN、PANet,优点:精度高;缺点:速度慢,难以应用在实时性要求高的任务上。
(2) one stage :有2条技术路线:mask-based和contour-based。
-
mask-based: 对图像中的每个像素点进行分类,代表模型有:YOLACT、BlendMask、TensorMask、CenterMask ,缺点:计算内存高,后处理复杂,难以应用在实时性要求高的任务上。
-
contour-based 将像素分类问题转换成轮廓点回归问题,该方法更加简单高效,代表模型有:Curve GCN 、Deep Snake、Point-Set Anchors、DANCE、PolarMask、LSNet。
1.2 当前 contour-based方法问题
目前的 contour-based方法存在如下3个问题:
(1)初始轮廓为人为设计的形状,与目标GT边界存在差异,导致不合理的defomation paths,使得训练困难;
(2)轮廓点的调整只是使用了局部信息,难以纠正较大的预测误差;
(3)预测轮廓点和GT是固定的配对,忽略了预测轮廓点位置调整的连续性,导致模型收敛速度慢,甚至会产生错误的预测结果。
1.3 论文创新点
(1)针对问题1:使用可学习的轮廓初始化架构;
(2)针对问题2:提出使用 Global deformation 代替 circular convolution;
(3)针对问题3:提出multi direction alignment (MDA) 和 dynamic matching loss (DML)
E2EC 在KITTI、SBD
和COCO均取得了SOTA成绩,可视化效果如下:
2 论文理解
2.1 网络架构
网络主要分成4个阶段,如下图:
阶段1:输入图片,经过目标检测器获得图片feature map以及物体的中心坐标;
阶段2:根据物体中心点生成初始轮廓;
阶段3:调整初始轮廓为粗糙的coarse轮廓;
阶段4:对coarse轮廓进行2次细化调整得到物体最终的轮廓

2.1.1 生成初始轮廓
使用目标检测器获得图片物体的中心坐标,计算物体轮廓点相对中心坐标点的偏移量,一个轮廓可以用128个点连接而成 (N =128)。得到坐标偏移量:
( ∆ x i n i t i , ∆ y i n i t i ) ∣ i = 1 , 2 , . . . , N {(∆x^i_{init}, ∆y^i_{init})|i = 1, 2, ..., N} (∆xiniti,∆yiniti)∣i=1,2,...,N
中心坐标加上偏移量则得到初始轮廓点坐标:
( x i n i t i , y i n i t i ) ∣ i = 1 , 2 , . . . , N {(x^i_{init}, y^i_{init})|i = 1, 2, ..., N} (xiniti,yiniti)∣i=1,2,...,N

2.1.2 生成 coarse 轮廓
论文提出 Global deformation,将生成的初始轮廓点送入MLP模型,输出所有轮廓点调整的偏移量。
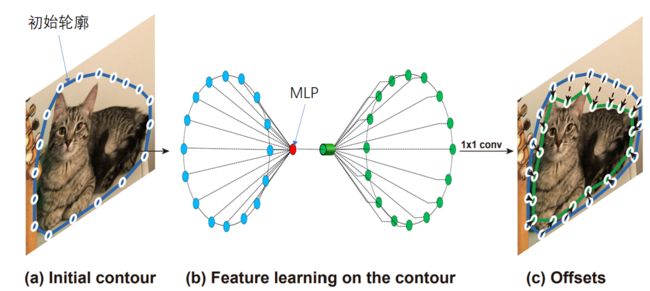
MLP 的输入为 (N + 1) × C ,N 表示 N 个 轮廓点, C 表示每个轮廓点特征维度,论文中取 64。
MLP的输出为 N × 2 ,代表轮廓点偏移量:
( ∆ x c o a r s e i , ∆ y c o a r s e i ) ∣ i = 1 , 2 , . . . , N {(∆x^i_{coarse}, ∆y^i_{coarse})|i = 1, 2, ..., N} (∆xcoarsei,∆ycoarsei)∣i=1,2,...,N

将初始轮廓点 与 轮廓点偏移量相加,可得到 coarse 轮廓点坐标:
( x c o a r s e i , y c o a r s e i ) ∣ i = 1 , 2 , . . . , N {(x^i_{coarse}, y^i_{coarse})|i = 1, 2, ..., N} (xcoarsei,ycoarsei)∣i=1,2,...,N
2.1.3 细化调整
轮廓点实际变形方向(deformation path)与理想的变形方向存在偏差,导致一些轮廓点的调整收敛慢,甚至是错误的调整。
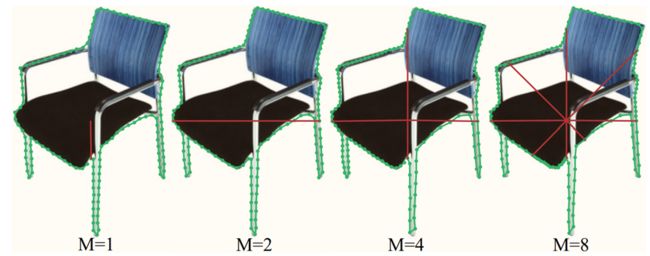
论文提出 MDA (multi-direction alignment),即固定 M 个轮廓点的变形方向,比如当M=2时,左边和右边的2个点的调整方向只能分别向右和向左,指向中心点,实验发现M=4时,效果最好。
2.2 Loss计算
Loss计算对应不同的阶段:
(1) 目标检测:
可使用任意的目标检测器(论文使用 CenterNet),loss为 L d e t L_{det} Ldet
(2) 初始轮廓:
L i n i t = 1 N ∑ i = 1 N s m o o t h l 1 ( x i i n i t − x i g t ) L_{init}=\frac{1}{N}\sum_{i=1}^N smooth l_1(x_i^{init}-x_i^{gt}) Linit=N1i=1∑Nsmoothl1(xiinit−xigt)
式中: x i i n i t x_i^{init} xiinit 是预测的初始轮廓点; x i g t x_i^{gt} xigt 是轮廓点label。
(3) coarse 轮廓:
L c o a r s e = 1 N ∑ i = 1 N s m o o t h l 1 ( x i c o a r s e − x i g t ) L_{coarse}=\frac{1}{N}\sum_{i=1}^N smooth l_1(x_i^{coarse}-x_i^{gt}) Lcoarse=N1i=1∑Nsmoothl1(xicoarse−xigt)
式中: x i c o a r s e x_i^{coarse} xicoarse 是预测的 coarse 轮廓点。
(4) 细化调整阶段1:
L i t e r 1 = 1 N ∑ i = 1 N s m o o t h l 1 ( x i i t e r 1 − x i g t ) L_{iter1}=\frac{1}{N}\sum_{i=1}^N smooth l_1(x_i^{iter1}-x_i^{gt}) Liter1=N1i=1∑Nsmoothl1(xiiter1−xigt)
式中: x i i t e r 1 x_i^{iter1} xiiter1 细化调整第一阶段的轮廓点。
(5) 细化调整阶段2:
L i t e r 2 = L D M L ( x i i t e r 2 − x i g t ) L_{iter2}=L_{DML}(x_i^{iter2}-x_i^{gt}) Liter2=LDML(xiiter2−xigt)
式中: x i i t e r 2 x_i^{iter2} xiiter2 细化调整第一阶段的轮廓点; DML (dynamic matching loss), DML由于2部分组成:
- 如图 (a), 每个预测的轮廓点调整到离它最近的
ground-truth边界上,loss如下:
x i ∗ = arg min x ∣ ∣ p r e d i i n − g t x i p t ∣ ∣ 2 L 1 ( p r e d , g t ) = 1 N ∑ i = 1 N ∣ ∣ p r e d i o u t − g t x ∗ i p t ∣ ∣ 1 x^∗_i = {\underset {x}{\operatorname {arg\,min} }}\, ||pred_i^{in} − gt^{ipt}_x ||_2\\ L_1(pred,gt)=\frac{1}{N}\sum_{i=1}^N||pred_i^{out}-gt_{x^*}^{ipt}||_1 xi∗=xargmin∣∣prediin−gtxipt∣∣2L1(pred,gt)=N1i=1∑N∣∣prediout−gtx∗ipt∣∣1
式中: g t i p t gt^{ipt} gtipt 最近邻插值 ground-truth
- 如图 (b) ,关键点
label将离它最近的预测点拉过来,loss如下:
y i ∗ = arg min y ∣ ∣ p r e d y i n − g t i k e y ∣ ∣ 2 L 2 ( p r e d , g t ) = 1 n k e y ∑ i = 1 n k e y ∣ ∣ p r e d y ∗ o u t − g t i k e y ∣ ∣ 1 y^∗_i = {\underset {y}{\operatorname {arg\,min} }}\, ||pred_y^{in} − gt^{key}_i ||_2\\ L_2(pred,gt)=\frac{1}{n_{key}}\sum_{i=1}^{n_{key}}||pred_{y^*}^{out}-gt_i^{key}||_1 yi∗=yargmin∣∣predyin−gtikey∣∣2L2(pred,gt)=nkey1i=1∑nkey∣∣predy∗out−gtikey∣∣1
DML是上述两项loss的平均:
L D M L ( p r e d , g t ) = L 1 ( p r e d , g t ) + L 2 ( p r e d , g t ) 2 L_{DML}(pred,gt)=\frac{L_1(pred,gt)+L_2(pred,gt)}{2} LDML(pred,gt)=2L1(pred,gt)+L2(pred,gt)

(图中:黄色点是轮廓点预测值,绿色点是label,红点是关键点 label,箭头表示变形方向)
总体的Loss 计算如下:
L o v e r a l l = L d e t + α L i n i t + β L c o a r s e + L i t e r 1 + L i t e r 2 L_{overall} = L_{det} + αL_{init} + βL_{coarse} + L_{iter1}+ L_{iter2} Loverall=Ldet+αLinit+βLcoarse+Liter1+Liter2
式中: α α α 和 β β β 是Loss权重,论文中两者都设置为0.1